Authors: Stefan Dumont
Category: Paper:Long Paper
Keywords: interchange, correspondence, scholarly edition, TEI, authority files
correspSearch - A Web Service to Connect Diverse Scholarly Editions of Letters
Letters are an important historical source: First, they may contain comments from contemporaries about the most different events, persons, publications, and issues. Second, letters allow insights about connections and networks between correspondence partners. So, questions occur which can only be answered across the borders of scholarly letter editions due to the fact that these editions are usually focussed on partial correspondences (of a certain person or between two specific persons). But this requires time-consuming searches across various letter editions. This has been a well-known problem for quite some time, now (Bunzel, 2013: 117) and has already evoked work on a few databases dedicated to correspondence, like e.g. “Early Modern Letters Online”. 1 But these databases have some limitations: firstly, they focus on specific research questions, time periods, geographic areas, or certain material. Secondly, they don’t provide an open, standard-based and well-documented way to provide and update data. Furthermore, the data can be searched and displayed, but only on a simple website. In none of the existing databases dedicated to edited letters it is possible to query and retrieve the data via an Application Programming Interface (API) and under a free license for subsequent use.
The mentioned methodic problem has lead Wolfgang Bunzel, who works in the field of research about the Romanticism, to request:
‘the creation of a decentralized, preferably open digital platform, based on HTML/XML and operating with minimal TEI standards, which is extensible in different directions and allows for existing web portals and websites to contribute at the lowest possible cost. This doesn’t request some kind of super structure which covers the entire amount of letters from the Romantic era (which could not be estimated exactly, anyway) but rather an intelligent linking system, which associates existing documents with one another. The creation of such nexus will naturally lead to research options reaching from searches for persons and places to specific keyword-based searches [...]’ (Bunzel, 2013: 123) 2
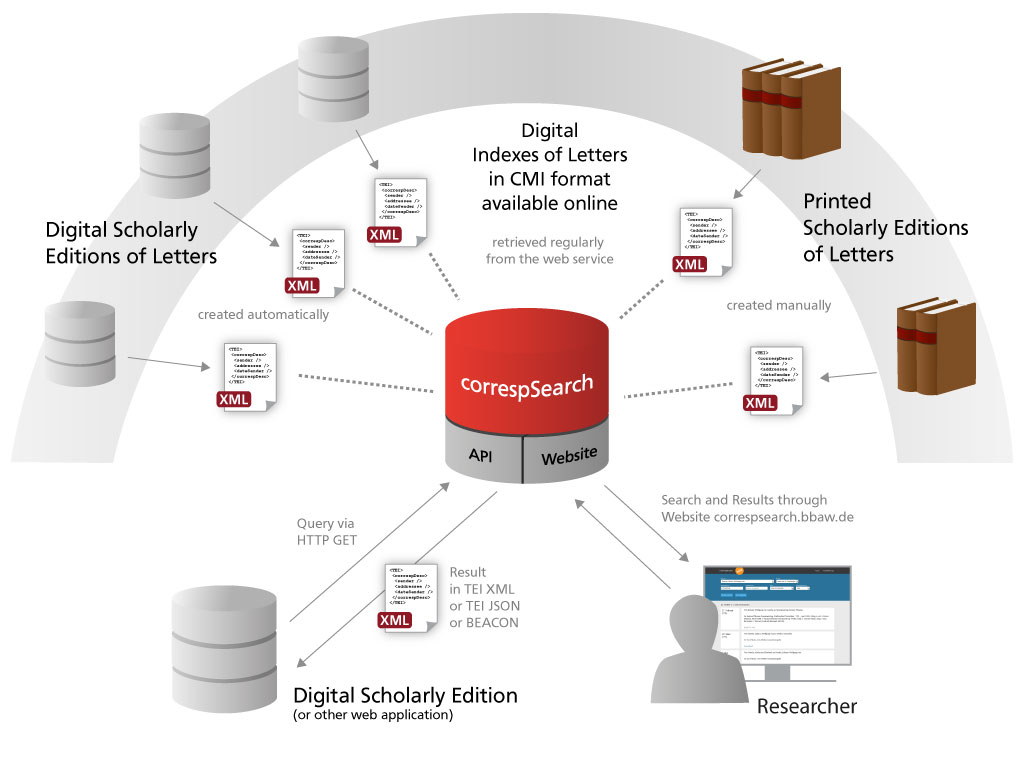
With “correspSearch” ( http://correspSearch.bbaw.de) this paper will present a web service, which takes a step in this direction by aggregating metadata of letters from various (digital or printed) scholarly editions and providing them collectively via open interfaces (Fig. 1). In doing so, it is independent from specific research questions as well as from temporal, geographic, or thematic limits.
The basis of the web service are digital indexes of letters provided by the editions in the “Correspondence Metadata Interchange Format” (CMIF), that has been (and will further be) developed by the Correspondence Special Interest Group of the Text Encoding Initiative (TEI). 3 The CMI format is based on the TEI Guidelines and allows to interchange metadata of letters, postcards etc. between scholarly editions by restricting and normalizing the essential elements of a communication act, namely sender, addressee, dates and places of writing and receiving. Besides the consistent TEI XML encoding, interchange will be enabled by usage of ISO dates and authority controlled identifiers. Sender, addressee, sender’s place as well addressee’s place are identified unambiguously using authority IDs, as e.g. provided by the Library of Congress. 4 When reading the indexes of letters the web service retrieves the most common authority controlled IDs from the Virtual International Authority File (VIAF). This way, IDs from different authority files are mapped onto one another. Up till now, the web service supports VIAF, GND (“Gemeinsame Normdatei” from the Deutsche Nationalbibliothek) as well as the authority files of the Bibliothèque nationale de France (BNF), the Library of Congress (LC), and the National Diet Library (NDL) in Japan. As for place names the web service uses “GeoNames”.
The scholarly editions themselves provide such digital indexes of letters in CMI format, online and under a free license (CC-BY 4.0). For this purpose the CMI format and its creation process is extensively documented on the correspSearch website including a FAQ section. 5 After providing a CMI file online, it is only necessary to register its URL for the web service. After that the file is automatically retrieved by correspSearch periodically (and in that way updated, if necessary).
The aggregated letter indexes are searchable on the correspSearch website by correspondent, location, and date. Correspondent and location can be specified according to their role in the communication process. Search results are displayed based on the metadata of the individual letter, together with biographical details. Letters from digital editions are directly linked.
Apart from the website an API has been implemented which allows for automatic requests to the web service. 6 In this scenario, the results are provided in TEI-XML in the described CMIF under a CC-BY 4.0 license, thus ensuring and facilitating further use and processing of the search results. Furthermore, the web service offers BEACON files as well as an experimental TEI-JSON output.
Thanks to the API it is possible to automatically refer or even link from one digital letter edition to related letters provided by other editions. This function was already implemented in a prototype for the digital scholarly edition “Schleiermacher in Berlin 1808-1834” (Fig. 2). 7 This feature helps researchers avoid methodological problems when interpreting a piece of correspondence: When analyzing a letter they usually consider the preceding and following letters in the correspondence between the sender and addressee, as well. However, their interpretation often does not include the letters which the correspondents send to or receive from other persons. With this feature the background of historical correspondences can be easily explored.
Via the API scholars can also exploit the data basis by usage of their own innovative technologies as well as of technologies which the web service itself does not yet support technically. Therefore, with a sufficiently extended data basis and the suitable software it will be possible to perform research on e.g. social or correspondence networks based on correspSearch. 8 Furthermore, the correspSearch API was connected with the web service “XTriples”, developed by the Academy of Sciences, Humanities and Literature in Mainz (Germany). Thus the results can be converted into RDF and provided for further analyses with the help of semantic web technologies. 9
The web service correspSearch and the CMIF are still under development. In the future it should be possible to search also for mentioned persons, events, publications etc. For this purpose the enhancement of the CMI file is currently discussed (Dumont, 2015). Also additional authority files will be supported, e.g. the Getty Thesaurus of Geographic Names. 10
The web service correspSearch was granted the “Berlin Digital Humanities Award 2015” (First Prize, endowed with 1.200 €).
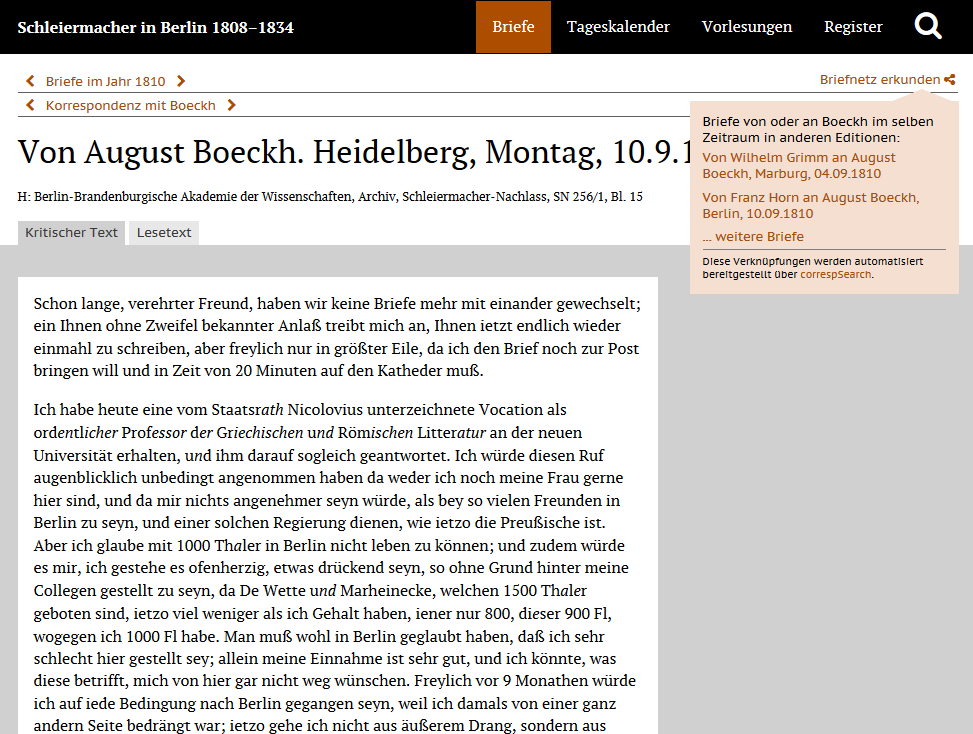
The digital scholarly edition queries the correspSearch API for other letters from and to August Boeckh around the date of the letter displayed (10 september 1810). If there is a result, the edition provides links to these letters.
- Bunzel, W. (2013). Briefnetzwerke der Romantik. Theorie – Praxis – Edition. In Bohnenkamp, A. and Richter, E. (eds.), Brief-Edition im digitalen Zeitalter (=Beihefte zu editio Bd. 34). Berlin/Boston: de Gruyter 2013. pp. 109-31.
- Dumont, S. (2015). Perspectives of the further development of the Correspondence Metadata Interchange Format (CMIF). digiversity — Webmagazin für Informationstechnologie in den Geisteswissenschaften. http://digiversity.net/2015/perspectives-of-the-further-development-of-the-correspondence-metadata-interchange-format-cmif/ (accessed 27 February 2016)
- Stadler, P. (2012). Normdateien in der Edition. Editio, 26: 174-83.
Early Modern Letters Online (EMLO), http://emlo.bodleian.ox.ac.uk/, is the one with the largest databases, but also includes data from other databases like “Circulation of Knowledge and Learned Practices in the 17th-century Dutch Republic”, http://ckcc.huygens.knaw.nl/. Besides this, there also exist more focused databases like “Exilnetz33”, http://exilnetz33.de.
Please note, that this is my own translation into English.
The CMIF is maintained in a GitHub repository: https://github.com/TEI-Correspondence-SIG/CMIF
For using authority files in scholarly editions, cf. Stadler 2012
The first version of the scholarly digital edition “Schleiermacher in Berlin” will be published in the next months by the Berlin-Brandenburg Academy of Sciences and Humanities.
For example: the developers of the visualisation tool “nodegoat” imported the data in their application to visualize a correspondence network: http://correspsearch-test.nodegoat.net/viewer.p/4/136/scenario/1/geo/fullscreen
http://xtriples.spatialhumanities.de. One prototype configuration is available under http://xtriples.spatialhumanities.de/examples.html