Authors: Geoffrey Rockwell, Laura Mandell, Stéfan Sinclair, Matthew Wilkens, Boris Capitanu, Stephen Downie
Category: Paper:Panel / Multiple Paper Session
Keywords: Very Large Collections, Machine Learning, HathiTrust
The Trace of Theory: Extracting Subsets from Large Collections
1. Introduction
Can we find and track theory, especially literary theory, in very large collections of texts using computers? This panel discusses a pragmatic two-step approach to trying to track and then visually explore theory through its textual traces in large collections like those of the HathiTrust.
- Subsetting: The first problem we will discuss is how to extract thematic subsets of texts from very large collections like those of the HathiTrust. We experimented with two methods for identifying “theoretical” subsets of texts from large collections, using keyword lists and machine learning. The first two panel presentations will look at developing two different types of theoretical keyword lists. The third presentation will discuss a machine learning approach to extracting the same sorts of subsets.
- Topic Modelling: The second problem we tackled was what to do with such subsets, especially since they are likely to still be too large for conventional text analysis tools like Voyant (voyant-tools.org) and users will want to explore the results to understand what they got. The fourth panel presentation will therefore discuss how the HathiTrust Research Center (HTRC) adapted Topic Modelling tools to work on large collections to help exploring subsets. The fifth panel talk will then show an adapted visualization tool, the Galaxy Viewer, that allows one to explore the results of Topic Modelling.
The panel brings together a team of researchers who are part of the “Text Mining the Novel” (TMN) project that is funded by the Social Sciences and Humanities Research Council of Canada (SSHRC) and led by Andrew Piper at McGill University. Text Mining the Novel (novel-tm.ca) is a multi-year and multi-university cross-cultural study looking at the use of quantitative methods in the study of literature, with the HathiTrust Research Center is a project partner.
The issue of how to extract thematic subsets from very large corpora such as the HathiTrust is a problem common to many projects that want to use diachronic collections to study the history of ideas or other phenomena. To conclude the panel, a summary reflective presentation will discuss the support the HTRC offers to DH researchers and how the HTRC notion of “worksets” can help with the challenges posed by creating useful subsets. It will further show how the techniques developed in this project can be used by the HTRC to help other future scholarly investigations.
2. Using Word Lists to Subset
Geoffrey Rockwell (Kevin Schenk, Zachary Palmer, Robert Budac and Boris Capitanu)
How can one extract subsets from a corpus without appropriate metadata? Extracting subsets is a problem particular to very large corpora like those kept by the HathiTrust (www.hathitrust.org/). Such collections are too large to be manually curated and their metadata is of limited use in many cases. And yet, one needs ways to classify all the texts in a collection in order to extract subsets if one wants to study particular themes, genres or types of works. In our case we wanted to extract theoretical works which for the purpose of this project we defined as Philosophical works or Literary Critical works. In this first panel presentation we will discuss the use of keyword lists as a way of identifying a subset of “philosophical” texts.
Why philosophical? We choose to experiment extracting philosophical texts first as philosophy is a discipline with a long history and a vocabulary that we hypothesized would lend itself to a keyword approach. Unlike more recent theoretical traditions, philosophical words might allow us to extract works from the HathiTrust going back thousands of years.
Keywords. For the first part of this project we adapted a list of philosophical keywords from the Indiana Philosophy Ontology Project (inpho.cogs.indiana.edu/). Our adapted list has 4,437 words and names starting with "abauzit", "abbagnano", "abdolkarim", "abduction", "abduh", "abel", and so on. There are a number of ways of generating such lists of keywords or features, in our case we were able to start with a very large curated list. The second paper in this panel discusses generating a list of literary critical keywords.
Process. We used this list with a process we wrote in Python that calculates the relative frequency of each word in a text and does this over a collection. The process also calculates the sum of the relative frequencies giving us a simple measurement of the use of philosophical keywords in a text. The word frequency process generates a CSV with the titles, author, frequency sum and individual keyword frequencies which can be checked and manipulated in Excel.
Testing. We iteratively tested this keyword approach on larger and larger collections. First we gathered a collection of 20 philosophical and 20 non-philosophical texts from Project Gutenberg (www.gutenberg.org/). We found the summed frequency accurately distinguished the philosophical from the non-philosophical texts. The process was then run by the HTRC on a larger collection of some 9,000 volumes and the results returned to us. We used the results to refine our list of keywords so that a summed relative frequency of .09 gave us mostly philosophical works with a few false positives. We did this by sorting the false positives by which words contributed to their summed relative frequency and then eliminating those words from the larger list that seemed to be ambiguous.
The process was then run on the HathiTust Open Open collection of 254,000 volumes. This generated some 3230 volumes that had a summed relative frequency over .1, which seemed a safe cut-off point given how .09 had worked with a smaller collection. To assess the accuracy of this method we manually went through these 3,230 and categorized them using the titles producing a CSV that could be used with other classification methods.

The table below summarizes the categories of volumes that we found, though it should be noted that the categorization was based on the titles, which can be misleading. “Unsure” was for works which we weren’t sure about. “Not-Philosophical” were those works that we were reasonably sure were not philosophical from the title. The categories like Science and Education were for works about science and philosophy or education and philosophy.
| Tag (Type) | Number of Volumes | Example |
| Unsure | 349 | The coming revolution (1918) |
| Education | 473 | Education and national character (1904) |
| Philosophy | 813 | Outlines of metaphysics (1911) |
| Science | 189 | Relativity; a new view of the universe (1922) |
| Social | 526 | The study of history and sociology (1890) |
| Religion | 722 | Prolegomena to theism (1910) |
| Not Philosophical | 158 | Pennsylvania archives (1874) |
One of the things that stands out is the overlap between religious titles and philosophical ones. This is not surprising given that the fields have been intertwined for centuries and often treat of the same issues. We also note how many educational works and works dealing with society can have a philosophical bent. It was gratifying to find only 4.9% of the volumes classified seemed clearly not philosophical. If one includes the Unsure category it is 15.7%, but the Unsure category is in many ways the most interesting as one reason for classifying by computer is to find unexpected texts that challenge assumptions about what is theory.
Conclusions. Using large keyword lists to classify texts is a conceptually simple method that can be understood and used by humanists. We have lists of words and names at hand in specialized dictionaries and existing classification systems. Lists can be managed to suit different purposes. Our list from InPhO had the advantage that is was large and inclusive, but also the disadvantage that included words like “being” and “affairs” that have philosophical uses but are also used in everyday prose. The same is true of the names gathered like Croce that can refer to the philosopher or the cross (in Italian). Further trimming and then weighting of words/names could improve the classification of strictly philosophical texts. We also need to look deeper into the results to find not just the false positives, but also the true negatives. In sum, this method has the virtue of simplicity and accessibility and in the case of philosophical texts can be used to extract useful, though not complete, subsets.
3. The Problem with Literary Theory
Laura Mandell (Boris Capitanu, Stefan Sinclair, and Susan Brown)
In this short paper, I describe adapting the word list approach developed by Geoffrey Rockwell for extracting a subset of philosophical texts from a large, undifferentiated corpus, to the task of identifying works of literary theory. The degree to which running the list of terms did in fact pull out and gather together works of literary criticism and theory is very high, despite potential problems with such an enterprise, which we discuss in this talk in detail.
- Developing the list of literary terms. Susan Brown and I decided to gather lists of literary terms. Susan initiated a discussion with the MLA about using terms from the MLA Bibliography but upon consideration these were in fact not at all what we needed: they classified subjects of texts as opposed to listing terms that would appear in those texts. I had recently spent some time learning about JSTOR’s new initiative in which sets of terms are created by what they call “SMEs”--Subject Matter Experts--and then used to locate articles all participating in an interdisciplinary subject. Their first foray is available in Beta: it gathers together all articles in no matter what field on the topic of Environmental Sustainabilty (labs.jstor.org/sustainability/). The terms collected are terms that would appear in the relevant texts, not in the metadata about them; the goal is to collect documents across multiple categories related to specialization, discipline, and field, since the desired result to gather together interdisciplinary texts concerning a common topic.
- Anachronism. JSTOR had started a “literary terms” list, and I finished the list of terms relying on encyclopedias of literary theory. Could a list of terms significant in the late-twentieth-century theories of literature as expressed in articles gathered in JSTOR be used to extract a set of texts published much earlier that analyze literature? What about the historical inaccuracy of using twentieth-century terms to find eighteenth- and nineteenth-century literary criticism?
Results:
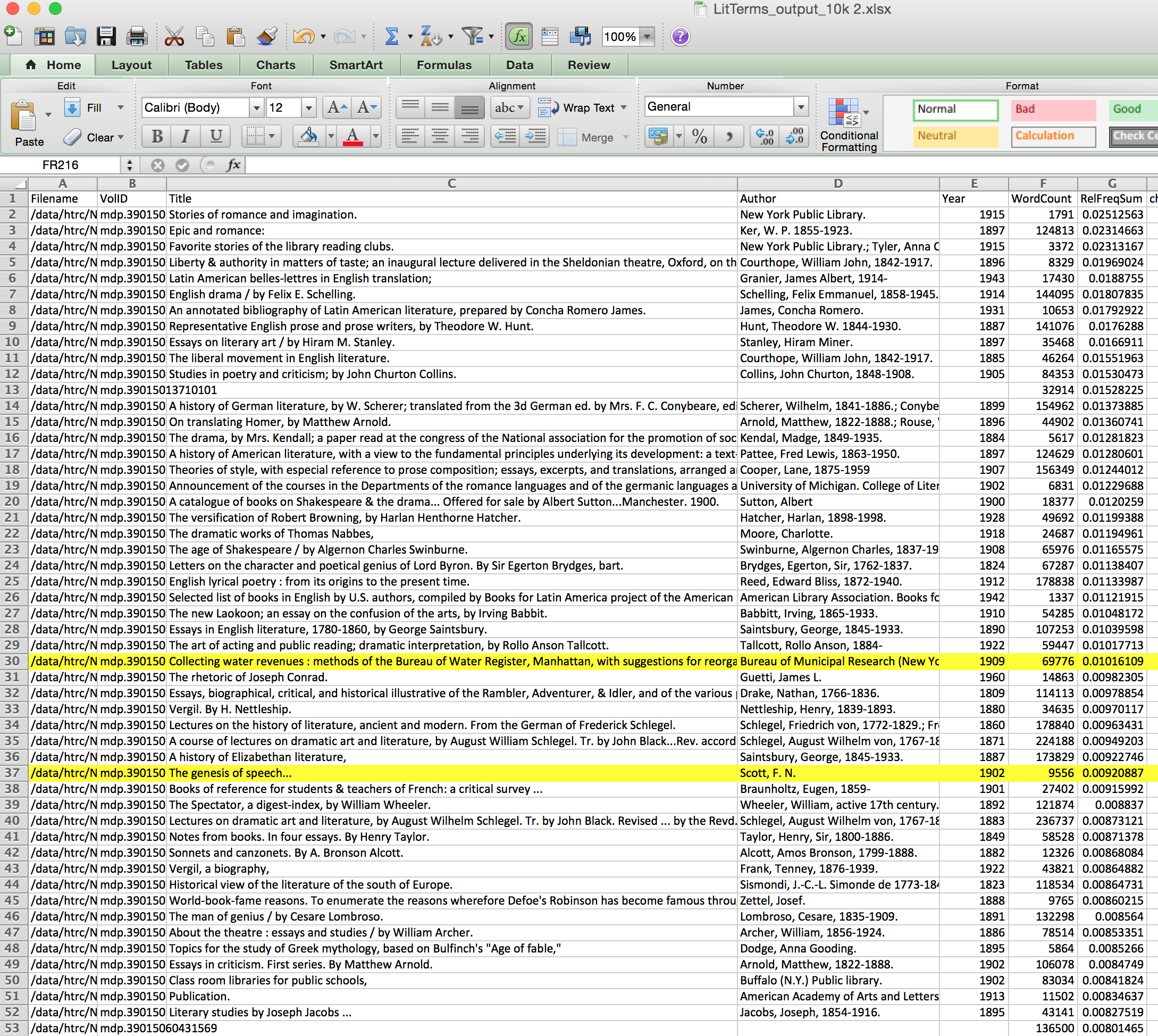
In fact, results show solidly that this anachronistic list of terms developed by experts do work to gather materials that preceded and fed into, served to develop, the discipline of literary theory. One of two falsely identified texts among the top relevant documents has to do with water distribution systems which had, as part of its most frequent terms, “meter” and “collection,” two terms relevant to analyzing the medium and content of poetry. Other false positives are similarly explicable, and, most important, they are rare.
In this paper, we report upon the effects of running these frequent words on very large datasets using both unsupervised to supervised learning.
4. Machine Learning
Stefan Sinclair (and Matthew Wilkens)
The third panel presentation deals with machine learning techniques to extract subsets. Unsupervised learning techniques allow us to evaluate the relative coherence of theoretical clusters within large textual fields and to identify distinct theoretical subclasses in the absence of any firmly established anatomy of the discipline. For these reasons, we performed unsupervised classification on three corpora: (1) A large collection (c. 250,000 volumes) of mixed fiction and nonfiction published in the nineteenth and twentieth centuries. (2) A subset of that corpus identified by algorithmic and manual methods as highly philosophical. And (3) A subset similarly identified as literary-critical.
In the case of the large corpus, the goal was to identify subsets containing high proportions of philosophy and criticism. For the smaller sets, we sought to produce coherent groupings of texts that would resemble subfields or concentrations within those areas. In each case, we extracted textual features including word frequency distributions, formal and stylistic measures, and basic metadata information, then performed both k-means and DBSCAN clustering on the derived Euclidean distances between volumes.
As in past work on literary texts (Wilkens, 105), we found that we were able to identify highly distinct groups of texts, often those dealing with specialized and comparatively codified subdomains, and that we could subdivide larger fields with reasonable but lower accuracy. The model that emerges from this work, however, is one emphasizing continuity over clear distinction. Subfields and areas of intensely shared textual focus do exist, but a systematic view of large corpora in the philosophical and literary critical domains suggests a more fluid conception of knowledge space in the nineteenth and twentieth centuries.
In parallel with the unsupervised classification performed – an attempt to allow distinctive features to emerge without, or with less, bias – we also performed supervised classification, starting with the training set of 40 texts labelled as Philosophical and Other (mentioned in "Using Word Lists to Subset" above). We experimented with several machine learning algorithms and several parameters to determine which ones seemed most suitable for our dataset. Indeed, part of this work was to recognize and and normalize the situation of the budding digital humanist confronting a dizzying array of choices: stoplists, keywords, relative frequencies, TF-IDF values, number of terms to use, Naïve Bayes Multinomial, Linear Support Vector Classification, penalty parameter, iterations, and so on ad infinitum. Some testing is desirable; some guesswork and some craftwork are essential. We reflect on these tensions more in the iPython notebook (Sinclair et al., 2016) and we will discuss them during the presentation as well.
One of the surprises from these initial experiments in machine learning was that using an unbiased list of terms from the full corpus (with stopwords removed) was considerably more effective than attempting to classify using the constrained philosophical vocabulary. Again, this may be because the keywords list was overly greedy.
Just as we experimented with ever-larger corpora for the "Using Lists to Subset" sub-project, the supervised learning subproject broadened its scope gradually in an attempt to identify theoretical texts unknown to us while examining the efficacy of the methodologies along the way. Indeed, the overarching purpose of adopting all three approaches (keyword-based, unsupervised classification, machine learning) was to compare and contrast different ways of studying theory in a large-scale corpus.
5. Working with HTRC datasets
Boris Capitanu
The fourth panel presentation focuses on working with the HathiTrust and the particular format of HathiTrust texts. Researchers may obtain datasets directly from HathiTrust [1] by making a special request, after having fulfilled appropriate security and licensing requirements. Datasets in HathiTrust and HTRC are available in two different ways:
- via rsync in Pairtree format
- via Data API
According to “Pairtrees for Object Storage (V0.1)” [2], the Pairtree is "a filesystem hierarchy for holding objects that are located within that hierarchy by mapping identifier strings to object directory (or folder) paths, two characters at a time”. In the HathiTrust, the objects consist of the individual volume and associated metadata. Volumes are stored as ZIP files containing text files, one text file for each page, where the text file is named by the page number. A volume ZIP file may contain additional non-page text files, whose purpose can be identified from the file name. The metadata for the volume is encoded in METS XML [3] and lives in a file next to the volume ZIP file. For example, a volume with id “loc.ark:/13960/t8pc38p4b” is stored in Pairtree as:
loc/pairtree_root/ar/k+/=1/39/60/=t/8p/c3/8p/4b/ark+=13960=t8pc38p4b/ark+=13960=t8pc38p4b.zip loc/pairtree_root/ar/k+/=1/39/60/=t/8p/c3/8p/4b/ark+=13960=t8pc38p4b/ark+=13960=t8pc38p4b.mets.xml
where “loc” represents the 3-letter code of the library of origin (in this case Library of Congress). As mentioned, the volume ZIP files contain text files named for the page number. For example, here are the first few entries when listing the contents of the above ZIP file:
ark+=13960=t8pc38p4b/
ark+=13960=t8pc38p4b/00000001.txt
ark+=13960=t8pc38p4b/00000002.txt
ark+=13960=t8pc38p4b/00000003.txt
…
Note that the strings that encode the volume id and the ZIP filename are different. Before a volume id can be encoded as a file name, it goes through a “cleaning” process that converts any character that is not a valid character to be used in a filename into one that is (for example “:” was converted to “+” and “/” to “=“), also dropping the 3-letter library code. The specific conversion rules are obscure, but library code already exists [4][5] for multiple languages that is able to perform this conversion both ways.
The pairtree is an efficient structure for storing a large number of files. However, working with this structure can pose certain challenges. One of the issues is that this deeply nested folder hierarchy is slow to traverse. Applications needing to recursively process the volumes in a particular dataset stored in pairtree will have to traverse a large number of folders to “discover” every volume. A second inconvenience stems from the use of ZIP to store the content of a volume. While efficient in terms of disk space usage, it’s inconvenient when applications need to process the text data of the volume as they would need to uncompress the ZIP file and read its contents, in the proper order, concatenating all pages, in order to obtain the entire volume text content. A further complication is due to the fact that the exact ordering and naming of the page text files in the ZIP file is only provided as part of the METS XML metadata file. So, if the goal is to create a large blob of text containing all the pages of a volume (and only the pages, in the proper order, without any additional non-page data), the most correct way of doing so is to first parse the METS XML to determine the page sequence and file names, and then uncompress the ZIP file concatenating the pages in the exact sequence specified. This, of course, has a large performance penalty if it needs to be done on a large dataset every time this dataset is used to address some research question.
An alternative way to obtain a particular dataset is to use the Data API [6]. Currently, access to Data API is limited, and is allowed only from the Data Capsule [7] while in Secure Mode. Using the Data API a researcher can retrieve multiple volumes, pages of volumes, token counts, and METS metadata documents. Authentication via the OAuth protocol is required when making requests to the Data API. The advantage of using the Data API in place of the pairtree (other than disk storage savings) is that one can request already-concatenated text blobs for volumes, and make more granular requests for token counts or page ranges without having to traverse deeply-nested folder structures or parse METS metadata.
In this panel presentation we will show how the tools developed for the Trace of Theory project were adapted to work with the Pairtree format. The goal is to help others be able to work with the HathiTrust data format.
Notes:
[1] https://www.hathitrust.org/datasets
[2] http://tools.ietf.org/html/draft-kunze-pairtree-01
[3] http://www.loc.gov/standards/mets/
[4] https://confluence.ucop.edu/display/Curation/PairTree
[5] https://github.com/htrc/HTRC-Tools-PairtreeHelper
[6] https://wiki.htrc.illinois.edu/display/COM/HTRC+Data+API+Users+Guide
[7] https://wiki.htrc.illinois.edu/display/COM/HTRC+Data+Capsule
6. Topic Modelling and Visualization for Exploration
Susan Brown (Geoffrey Rockwell, Boris Capitanu, Ryan Chartier, and John Montague)
When working with very large collections even subsets can be too large to manage with conventional text analysis tools. Further, one needs ways of exploring the results of extraction techniques to figure out if you got what you were expecting or something surprising in an interesting way. In the fifth panel presentation we will discuss the adaptation of a tool called the Galaxy Viewer for visualizing the results of Topic Modelling (Montague et al., 2015). Topic modeling is an automated text mining technique that has proven popular in the humanities that tries to identify groups of words with a tendency to occur together within the same documents in a corpus. Chaney and Blei explain that, “One of the main applications of topic models is for exploratory data analysis, that is, to help browse, understand, and summarize otherwise unstructured collections.” (Chaney et al., 2012)
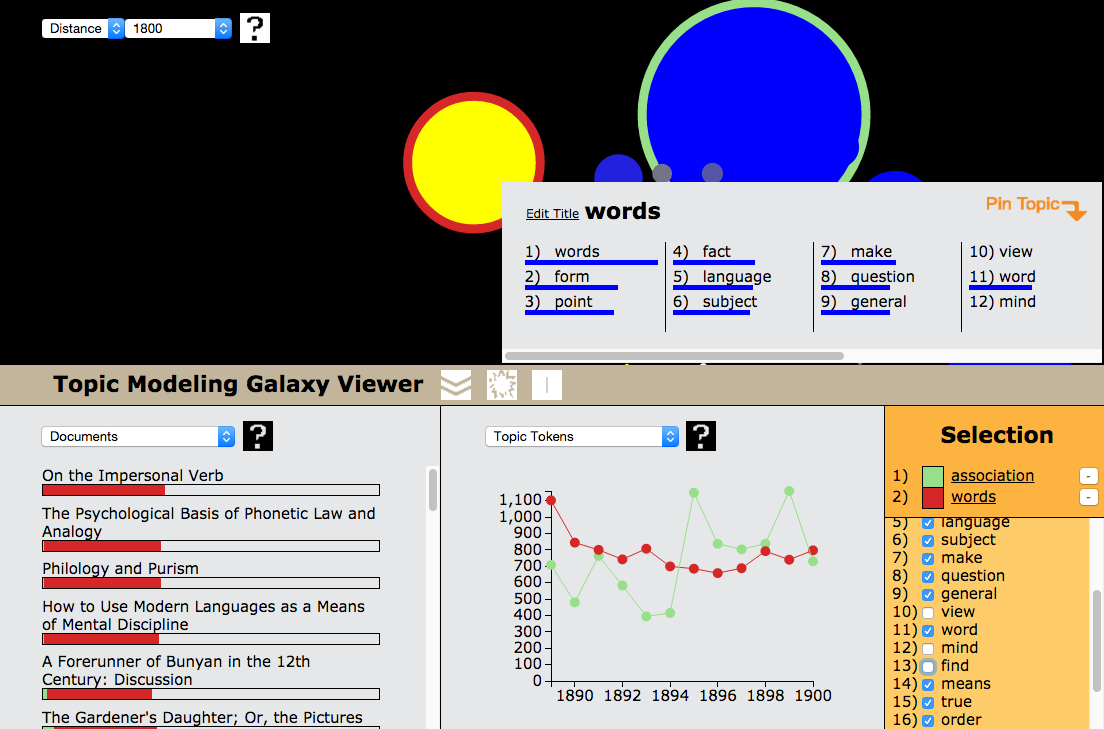
The Galaxy Viewer prototype was developed to explore the results of topic modelling over large collections. It combines different views so that one can select topics, compare topics, explore the words in topics, follow topic tokens over time, and see the document titles associated with topics. In this presentation we will demonstrate the Galaxy Viewer and then discuss how it was scaled to handle much larger collections.
The prototype Galaxy Viewer backend code uses Mallet (McCallum, 2002) to infer the set of topics, topic distributions per document, and word probabilities per topic. Unfortunately, Mallet is meant to be used on small- to medium-sized corpora as it requires that the entire dataset be loaded into RAM during training. An additional constraint with Mallet is the fact that although Mallet can fully utilize all the CPU cores on a single machine, it’s not designed to work in a distributed-computing fashion across a number of machines, to speed up execution. As such, processing very large datasets (if even possible) might take a very long time (as the algorithm makes multiple passes over the entire dataset). Many implementations of LDA exist, which primarily fall into one of two categories: Batch LDA, or Online LDA. The core difference between batch and online LDA stems from what happens during each iteration of the algorithm. In batch mode, as mentioned earlier, each iteration of the algorithm makes a full pass over all the documents in the dataset in order to re-estimate the parameters, checking each time for convergence. In contrast, online LDA only makes a single sweep over the dataset, analyzing a subset of the documents each iteration. The memory requirement for online LDA depends on the chosen batch size only, not on the size of the dataset - as is the case with batch LDA.
We are currently in the process of researching/comparing the available implementations of LDA to establish which one would be best suited to use for the Galaxy Viewer. We are also considering the option of not fixing the LDA implementation, but instead make the backend flexible so that any LDA implementation can be used (as long as it provides the appropriate results that are needed). In the latter case we’d have to create specific result interpreters that can translate the output from the specific implementation of LDA to the appropriate format to be used to store in the database (to be served by the web service).
Given that Topic Modeling results do not expose the textual content of the documents analyzed, and cannot be used to reconstruct the original text, they are safe to be publicly shared without fear of violating copyright law. This is great news for researchers working with collections like those of the HathiTrust as they should be able to gain insight into datasets which are still currently in-copyright and would, otherwise, not be available to be inspected freely.
In the prototype Galaxy Viewer implementation, the output of the topic modeling step is processed through a set of R functions that reshape the data and augment it with additional calculated metrics that are used by the web frontend to construct the visualization. These post-processing results are saved to the filesystem as a set of five CSV files. One of these CSV files is quite large as it contains the topic modeling state data from Mallet (containing topic assignments for each document and word, and associated frequency count). The visual web frontend code loads this set of five files into memory when the interface is accessed the first time, which can take several minutes. For the prototype this approach was tolerated, but it has serious scalability and performance issue that needs to be addressed before the tool can be truly usable by other researchers.
Scaling the Galaxy Viewer therefore consists of creating a web service backed with a (NoSQL) database which will service AJAX requests from the front-end for the data needed to construct the topic visualization and related graphs. We are developing the set of service calls that need to be implemented/exposed by the web service to fulfill the needs of the front-end web-app. The backend service will query the database to retrieve the necessary data to service the requests. The database will be created based on the output of the Topic Modeling process, after required post-processing of the results is completed (to calculate the topic trends, topic distances, and other metrics used in the display). Relevant metadata at the volume and dataset level will also be stored to be made available to the front-end upon request. This work will be completed by the end of December 2015 so that it can be demonstrated in the new year. The scaled Galaxy Viewer will then provide a non-consumptive way of allowing users of the HathiTrust to explore the copyrighted collections. Extraction of subsets and Topic Modelling can take place under the supervision of the HTRC and the results database can then be exposed to visualization tools like the Galaxy Viewer (and others) for exploration.
7. Closing reflections: How “Trace of Theory” will improve the HTRC .
J. Stephen Downie
The HathiTrust Research Center exists to give the Digital Humanities community analytic access to the HathiTrust’s 13.7 million volumes. The HT volumes comprise over 4.8 billion pages each in turn represented by a high-resolution image file and two OCR files yielding some 14.4 billion data files! Thus, as the earlier papers have highlighted, the sheer size of the collection, along with the idiosyncratic nature of the HT data, together create several hurdles that impede meaningful analytic research.The HTRC is engaged in two ongoing endeavours designed to assist DH researchers in overcoming these obstacles: The Advance Collaborative Support (ACS) program [1]; and, the Workset Creation for Scholarly Analysis (WCSA) project [2].
The ACS program at HTRC provides no-cost senior developer time, data wrangling assistance, computation time and analytic consultations to DH researchers who are prototyping new research ideas using the HT data resources. The ACS program is an integral part of the HTRC’s operation mission and was part of its value-added proposition when the HTRC launched its recent four-year operations plan (2014-2018). It is a fundamental component of the HTRC’s outreach activities and as such, has staff dedicated to its planning, management and day-to-delivery. The ACS team was responsible for creating, and then reviewing, the competitive ACS Request for Proposals (RFP) that ask interested DH researchers outline their intellectual goals, describe their data needs, and estimate their computational requirements. The ACS team is generally looking for new projects that could benefit from some kickstarting help from HTRC. HTRC welcomes proposals from researchers with a wide range of experience and skills. Projects run 6 to 12 months.
Originally funded by the Andrew W. Mellon Foundation (2013-2015), the current WCSA program is building upon, extending and implementing the development made during the funding period. The HTRC project team, along with subaward collaborators at University of Oxford, University of Maryland, Texas Agriculture and Marine University and University of Waikato, developed a group of prototype techniques for empowering scholars who want to do computational analyses of the HT materials to more efficiently and effectively create user-specific analytic subsets (called “worksets”). A formal model has been designed to describe the items in a workset along with necessary bibliographic and provenance metadata that is now being incorporated into the HTRC infrastructure (Jett, 2015).
The Trace of Theory project was selected from the first round of ACS proposals. This concluding panel presentation will discuss in what ways the Trace of Theory project has been both a representative and a unique exemplar of the ACS program. It will present some emergent themes that evolved from the HTRC-Trace of Theory interactions that we believe will have an important influence on the delivery of future ACS projects. In the same manner, it will reflect upon the problems the team of researchers had in subsetting the data to build their necessary worksets along with the solutions that the HRTC-Trace of Theory collaboration developed to surmount those difficulties. The panel will finish with a summary of how HTRC intends to incorporate the lessons learned into its day-to-day operations as well as future ACS projects.
Notes:
[1] The 2014 ACS RFP is available at: https://www.hathitrust.org/htrc/acs-rfp
[2] https://www.lis.illinois.edu/research/projects/workset-creation-scholarly-analysis-prototyping-project
- Chaney, A. J. and Blei, D. M. (2012). Visualizing Topic Models, ICWSM. http://www.aaai.org/ocs/index.php/ICWSM/ICWSM12/paper/download/4645%26lt%3B/5021 (accessed Dec 2015).
- Jett, J. (2015).Modeling worksets in the HathiTrust Research Center. CIRSS Technical Report WCSA0715. Champaign, IL: University of Illinois at Urbana-Champaign. Available via: http://hdl.handle.net/2142/78149 (accessed Dec 2015)
- McCallum, A. K. (2002). MALLET: A Machine Learning for Language Toolkit, http://mallet.cs.umass.edu (accessed Dec 2015).
- Montague, J., Simpson, J., Brown, S., Rockwell, G. and Ruecker, S. (2015). Exploring Large Datasets with Topic Model Visualization. Paper presented by Montague at DH 2015 at the University of Western Sydney, Australia.
- Sinclair, S., G. Rockwell and the Trace of Theory Team. (2016). Classifying Philosophical Texts. Online at http://bit.ly/1kHBy56 (accessed Dec 2015).
- Wilkens, M. (2016). Genre, Computation, and the Weird Canonicity of Recently Dead White Men. NovelTM Working Paper.