Authors: Johannes Hellrich, Udo Hahn
Category: Paper:Short Paper
Keywords: language change, German, romantic period, artificial neural network, word2vec
Measuring the Dynamics of Lexico-Semantic Change Since the German Romantic Period
1. Introduction
The dynamics of language change over time are most evident in the lexicon component of natural languages. In particular, the gradual semantic changes words may undergo have a strong effect on the comprehension of historical texts by modern readers. Yet, efforts to automatically detect and trace this lexical evolution are scarce. Our study follows the work of Kim et al. (2014) who detected lexico-semantic changes in English texts over the 20 th century via a series of neural network language models. Our models were trained on the German part of the Google Books Ngram 1 corpus (Michel, et al., 2011; Lin et al., 2012), which covers over 657k German books. Such models have the particular advantage that they can be queried for the semantic similarity of arbitrary words. We tested this query option by sampling nouns from Des Knaben Wunderhorn (Arnim and Brentano, 1806-1808), a collection of German folk poems and songs from the German Romantic period. The choice of this volume is merely motivated by our interest in the literary period it belongs to. We detected interesting semantic changes between 1798 (often taken as the starting point for the German Romantic period) and 2009 (last year in the Google corpus).
2. Methods
Using the specific contexts in which words appear in order to determine the (distributional) meaning of words is an old idea from linguistic structuralism (Firth, 1957). For a long time, this appealing approach could not have been seriously investigated due to the lack of suitably large corpora and adequate computational power to deal with distributional patterns of words on a larger scale. Thus, only few studies on automatically detecting semantic change have been conducted up until now, with a clear focus on the high-volume data provided by Google Books. This collection is widely popular due to its immediate availability and enormous coverage despite well-known problems stemming from both the quality of optical character recognition (OCR) and the sampling strategies used to compile it (Pechenick et al., 2015). 2
Early approaches towards modeling lexico-semantic change patterns used frequency and bi-gram co-occurrence data (Gulordava and Baroni, 2011), as well as (context-based) classifiers (Mihalcea and Nastase, 2012). Riedl et al. (2014) built distributional thesauri to cluster similar word senses. All of these approaches detected lexico-semantic changes between multiple pre-determined periods. In contrast, neural network language models can be used to detect changes between arbitrary points in time, thus offering a longitudinal perspective (Kim et al., 2014; Kulkarni et al., 2015). In our experiments, we use a skip-gram model, a simplified neural network that is trained to predict plausible contexts for a given word, thereby generating (computationally less expensive) low-dimensional vector space representations of a lexicon (Mikolov et al., 2013). Despite their simplicity, neural network language models are a state-of-the-art approach, with details concerning ideal implementation solutions and training scenarios still being under dispute (Baroni et al., 2014; Schnabel et al., 2015).
3. Experiment
We trained our models on 5-grams spanning the years 1748 to 2009, using a uniform sampling size of 1M 5-grams per year; the first 50 years were used for initialization only. Test words for high-lighting semantic change patterns were selected from Des Knaben Wunderhorn by identifying the ten most frequent nouns, i.e. Gott [‘god’], Herr [‘lord, mister’], Liebe [‘love’], Tag [‘day’], Frau [‘woman, miss’], Mutter [‘mother’], Herz [‘heart’], Wein [‘wine’], Nacht [‘night’] and Mann [‘man’]. For each of these ten nouns we selected the three words most similar to them (according to the cosine of their respective vector representations) during 1799 and 1808 and between 2000 and 2009, tracking how the similarity of these words developed between 1798 and 2009. The programs used for our experiments and resulting data are publically available via GitHub. 3
4. Results
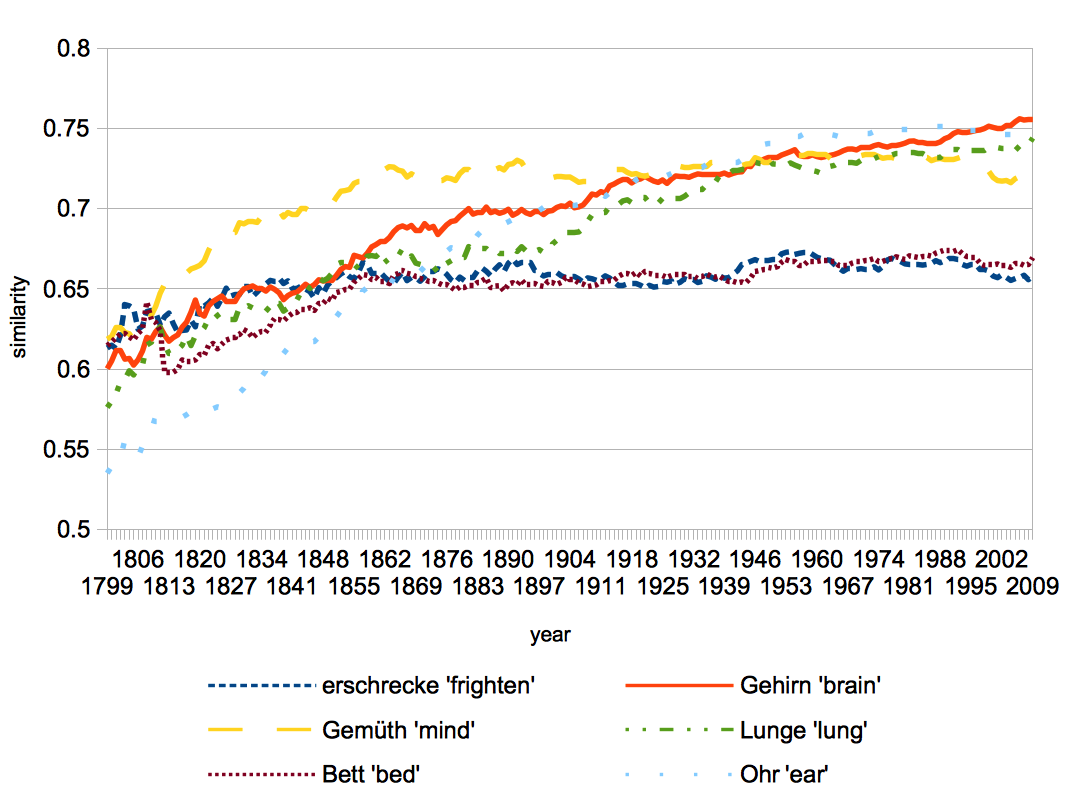
The cosine similarity between the 1798 and the 2009 vector representation of the ten test words is rather high, ranging from 0.72 for Mann to 0.84 for Wein, thus showing only minor semantic changes. Manual interpretation of their most similar words revealed an interesting change for Herz (see Fig. 1) that is nowadays more similar to other anatomical terms (such as Gehirn [‘brain’], Lunge [‘lung’], or Ohr [‘ear’]) and less likely to be used metaphorically (such as indicated by erschrecke [‘frighten’], or Gemüth [archaic for ‘mind’]). As this change predates Google Books’ tendency to overrepresent scientific texts (at least for English, cf. Pechenick et al., 2015) this finding can be assumed to be an example of true lexico-semantic change. The example also demonstrates a need for a metric incorporating frequency information and normalization of input, since Gemüth is an archaic form for Gemüt non-conformant with modern German spelling conventions, although it is rated as currently similar to Herz.
Fig. 1 Lexical semantics of Herz [‘heart’] as expressed by its similarity with six other words; similarity-axis not depicting whole range of possible values (0–1)
5. Conclusion
This research note has gathered preliminary evidence for the feasibility of corpus-driven studies into German diachronic semantics. We advocate a computational, neural network-based approach where the evolution of lexico-semantic changes is traced by similarities of distributional patterns in the context of words over time.
Looking backwards for semantic changes is, however, constrained by the quality and quantity of linguistic data available. While the primary corpus we use for determining semantic evolution patterns, the Google Books Ngram corpus, is remarkably large, it suffers from a idiosyncratic sampling policy, as well as OCR shortcomings and even more advanced issues, such as the absent normalization of historic orthographic variants. Other historic corpora dealing with the latter quality issues (such as the Deutsches Textarchiv) are plagued by their comparatively minuscule size.
Future research in Digital Humanities, besides dealing with these issues, will exploit the similarity data in order to make proper use of them under a humanities’ perspective and, thus, hopefully determine the added value of such computational results. This can be achieved by incorporating complementary types of data (e.g. historical, economic ones) to render additional evidences to change patterns. Since this is a huge and complex task, we plan to make our similarity data publically available on a website, together with an easy-to-use interface, as a humanities tool for comparative, diachronic lexico-semantic studies, with several user-adjustable parameters (e.g. different grain sizes of time intervals, alternative ranking metrics, etc.). From a methodological perspective, we plan to focus our research on protocols for training models covering long timespans, a metric to measure the quality of historic language models (probably including the need for a manual evaluation) and a way to include frequency information–a word which is no longer used cannot be said to be unchanged in its semantics. Such a system would ideally be tested by an in-depth study of the semantics of carefully selected words, including a comparison with prior, hermeneutically guided work in the humanities as a rich, yet completely informal background theory.
6. Funding
This work was supported by the DFG-founded Research Training Group "The Romantic Model. Variation - Scope - Relevance" [grant GRK 2041/1].
- Arnim, A. von and Brentano, C. (1806-1808). Des Knaben Wunderhorn 1(3), (Annotated TCF version provided by the Deutsches Textarchiv).
- Baroni, M., Dinu, G. and Kruszewski, G. (2015). Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors. Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics,1: 238–47.
- Firth, J. R. (1957). A synopsis of linguistic theory, 1930-1955. Studies in Linguistic Analysis, pp. 1–32.
- Gulordava, K. and Baroni, M. (2011). A distributional similarity approach to the detection of semantic change in the Google Books Ngram corpus . Proceedings of the GEMS 2011 Workshop on Geometrical Models of Natural Language Semantics @EMNLP 2011, pp. 67–71.
- Kim, Y., et al. (2014). Temporal analysis of language through neural language models . Proceedings of the ACL 2014 Workshop on Language Technologies and Computational Social Science, pp. 61–65.
- Kulkarni, V., et al. (2015). Statistically significant detection of linguistic change. Proceedings of the 24th International Conference on World Wide Web, pp. 625–35.
- Lin, Y., et al. (2012). Syntactic annotations for the Google Books Ngram Corpus . Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pp. 169–74.
- Michel, J.B., et al. (2011). Quantitative analysis of culture using millions of digitized books . Science, 331(6014): 176–82.
- Mihalcea, R. and Nastase, V. (2012). Word epoch disambiguation: Finding how words change over time . Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, 2: 259–63.
- Mikolov, T., et al. (2013). Distributed representations of words and phrases and their compositionality. Advances in Neural Information Processing Systems 26 (NIPS2013), pp. 3111–119.
- Pechenick, E. A., Danforth, C. M. and Dodds, P. S. (2015). Characterizing the Google Books Corpus: Strong limits to inferences of socio-cultural and linguistic evolution. PLoS ONE 10(10): e0137041.
- Riedl, M., Steuer, R. and Biemann, C. (2014). Distributed distributional similarities of Google Books over the centuries . Proceedings of the 9th International Conference on Language Resources and Evaluation (LREC’14), pp. 1401–405.
- Schnabel, T., et al. (2015). Evaluation methods for unsupervised word embeddings. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP ’15), pp. 298–307.
An n-gram is a sequence of n words plus information on their frequency/probability of occurrence for a given corpus. The available version of the corpus does not consist of running text, but of n-grams instead.
The Deutsches Textarchiv (DTA) can be considered as a counter example, at least, as far as the quality of OCR is concerned. Yet, DTA suffers from tremendous size limitations in comparison with the (German portion of the) Google corpus, since this corpus for historic German texts contains only about 2.4k texts ( http://www.deutschestextarchiv.de/list).