Authors: Martin Reckziegel, Stefan Jänicke, Gerik Scheuermann
Category: Paper:Poster
Keywords: close reading, visualisation, user interface, citation
CTRaCE: Canonical Text Reader and Citation Exporter
1. Motivation
“Citation is the core of scholarship” Neel Smith and Chris Blackwell state in their paper on the CTS/CITE Architecture (Smith et al., 2012). A citation like “Athenaeus, Deipnosophists, edition of Kaibel (1887), book 1, chapter 3” can refer to only one string of Greek words and it is valid for every printed copy of Kaibel’s edition. Such a citation identifies an object of study uniquely, and it is “independent of any implementing technology”. But such a citation scheme is hardly machine readable, and the digital processing of citations becomes more and more important in the humanities. To support this task, the CITE Architecture 1 was designed. Adopting the international standard of URNs 2, unique, complete and machine readable scholarly citations, so called CTS URNs can be generated.
Although the CITE Architecture is a substantial basis, it does not provide an interface to intuitively make this capability accessible to humanities scholars. This paper aims to fill this gap. We designed the web-based application CTRaCE that first of all allows the browsing and reading of texts provided in the corresponding canonical format. With basic interaction functionality, CTRaCE supports easy creation of a digital citation of an arbitrary text passage as a CTS URN. As it can also be used to resolve existent CTS URNs, CTRaCE fulfills the major requirements for the processing of manually generated digital citations necessary for digital scholarship.
2. Technical Basis
CTRaCE is based on Canonical Text Services (CTS), which – part of the CITE architecture – addresses two fundamental needs in digital scholarship: (1) the citation of textual units, and (2) their retrieval. To accomplish the transition between classical and digital citations, CTS use Uniform Resource Names (URNs). The top-level structure of a CTS URN 3 has the following format:
cts:urn:namespace:work:passage
As URNs are organized hierarchically from left to right, each component increases the precision of the corresponding reference. The namespace component is the top level division of the system. As we use the Perseus Digital Library 4 as demonstration corpus, one of the namespaces is “greekLit”, which identifies works in ancient Greek that are preserved through manuscript tradition (Smith et al., 2012). The work component specifies the document the URN refers to. It is divided into textgroup.work.version.exemplar from which the last two parts are optional. For example, the URN
cts:urn:greekLit:tlg0008.tlg001.perseus_grc3:
refers to Kaibel’s edition of “Deipnosophists” (tlg001), located in the textgroup that contains works by Athenaeus (tlg0008). Generating a URN representation for each text, the CTS architecture organizes the whole corpus in the form of a tree with inner nodes representing the hierarchical structure among the texts, which are the leaf nodes of the tree.
Each individual text further has a canonical citation scheme assigned. As the hierarchy of texts varies depending on genre – a play might be arranged by acts and scenes while a poem uses verses –, this scheme is flexibly designed. Additionally, the URN can be further refined with the passage component that specifies a continuous part of the text – even on character granularity if necessary.
cts:urn:greekLit:tlg0008.tlg001.perseus_grc3:1.2@καὶ[2]-1.3@δρ
refers to the “Deipnosophists” part that ranges from the second occurrence of the string “καὶ” in the second chapter of the first book until the first occurrence of “δρ” in the third chapter.
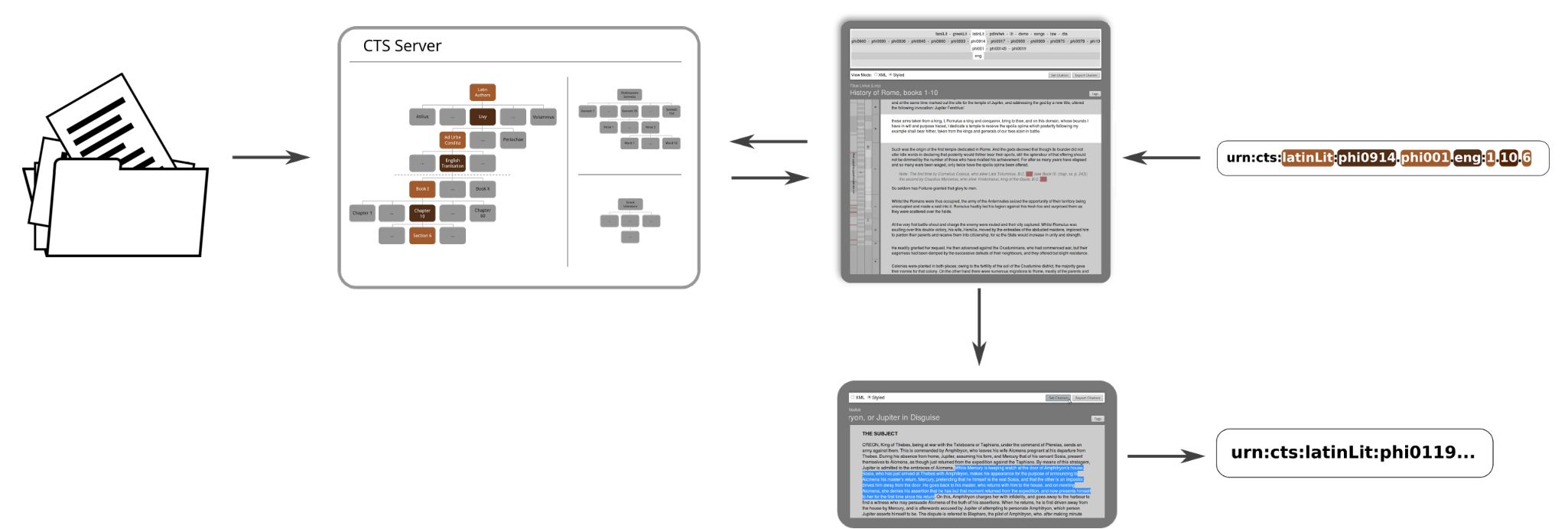
Figure 2 displays an overview of our CTS based architecture. Though the scalable CTS implementation (Tiepmar et al., 2014) we use as server infrastructure supports any text in Unicode, we built our application with the idea to operate with texts in TEI 5 format that often include styling markup, which can be used for visualization purposes. CTRaCE is a client side web application communicating with the CTS server using the CTS protocol 6. In the following section, we explain the design and the functionality of CTRaCE in detail.
3. User Interface
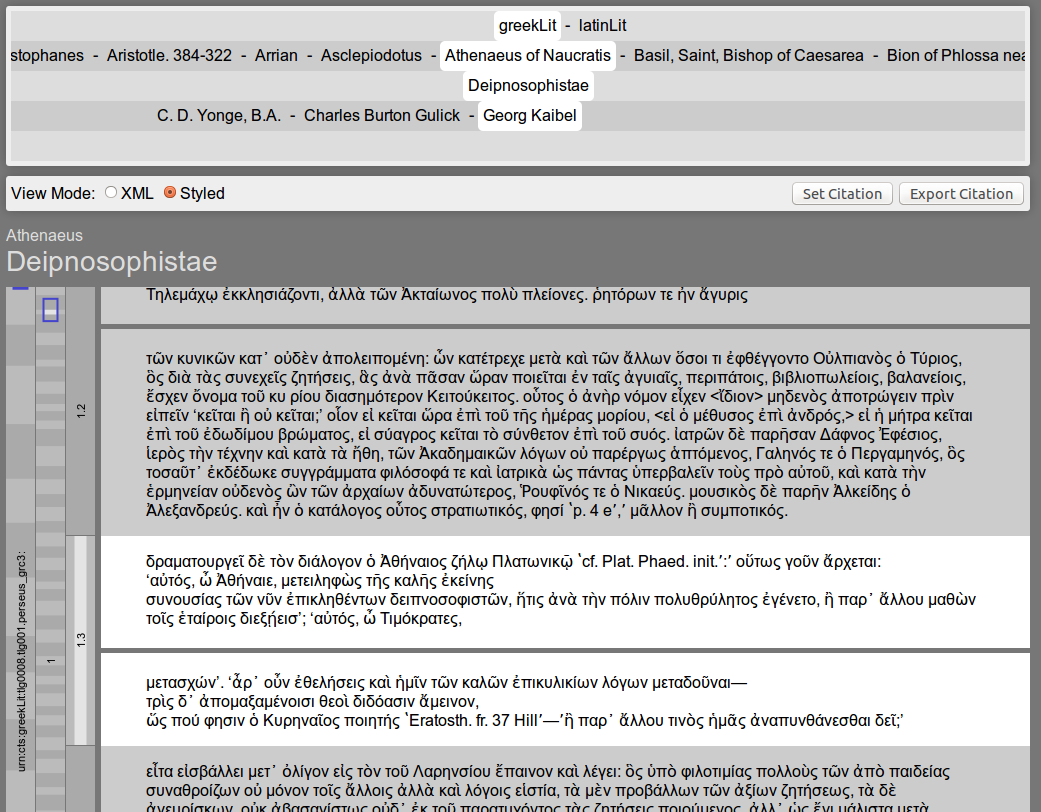
The CTS architecture is a robust basis for digital citations, but due to its technical nature, tools need to be built upon the architecture to leverage its functionality in an intuitive way to humanities scholars. We present CTRaCE for that purpose, an example screenshot is shown in Figure 1. It focuses on supporting the following three tasks:
- browsing and reading texts in the CTS system
- creating and exporting citations using CTS URNs
- resolving CTS URNs by visualizing the cited text and its surrounding context
CTRaCE is designed to display the content of a single URN, always shown as parameter in the address bar of the internet browser. Everything related to the citation this URN points to is drawn with a white background in three view components, which we explain below.

The navigation component shown in Figure 3 is placed in the header section of the user interface and can be used to browse through all available documents. It is derived from the ontology of the CTS system described above. Each row represents one level of the URN parts that identify a text. If appropriate metadata such as authors or titles are available, we display these labels instead of URN identifiers as fallback. Each text in this tree can be selected via mouse click for close reading.
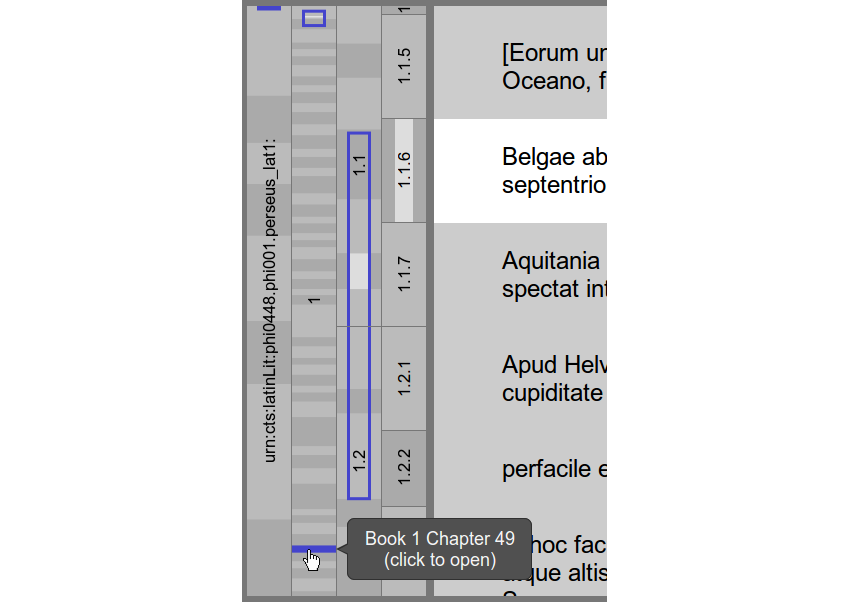
CTRaCE displays texts as one continuous scrollable block, which for optimal performance is loaded in chunks. To the left of the text, we implemented a distant view component showing the citation structure in relation to the visible portion of the text. We therefore adopt a visualization method called Icicle Plot (Kruskal et al, 1983) that shows hierarchical relations in a compact way. Figure 4 shows a screenshot of this view. The underlying text uses a three level hierarchy to create a citation: book, chapter and section. Each gray-bordered rectangle in the view represents a node within the citation structure. The leftmost rectangle labeled with the URN of the document represents the root. Inside each node’s rectangle, we provide information about their direct children regarding the citation tree. Since the document contains eight books, the same number of alternating shaded rectangles is drawn inside the root node. We provide quick navigation through the document using mouse clicks on these inner rectangles. Depending on the document position, the corresponding citation nodes are drawn in the remaining columns with the leaf nodes aligned to the text. As the text shown in Figure 4 is only part of the first chapter, there is only one node rectangle in the second column. Additionally, the white rectangles depict which part of a node is defined by the current URN, and the blue rectangles represent the visible portion of a node.
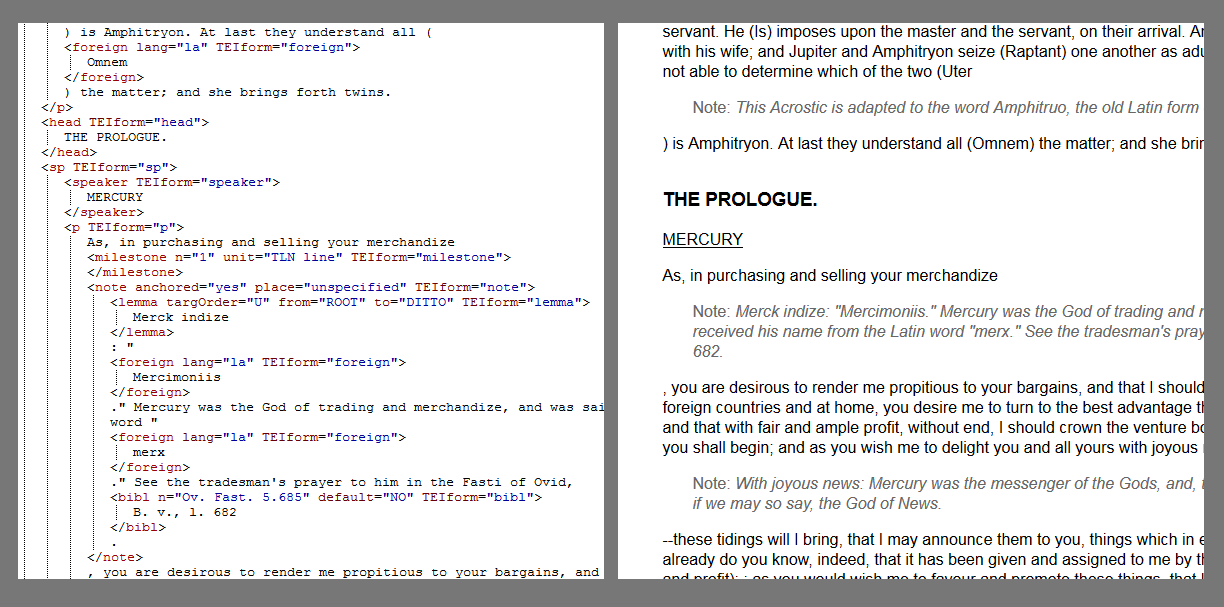
The text of the document is shown in the text reader component in main area of the screen. As the text chunks are loaded from the server, they are transformed into HTML code. So far we implemented two rendering methods as shown in Figure 5. The XML view mode displays the text including its markup in a syntax highlighted, indented fashion. The Styled view mode only displays the text using the markup information to style it appropriately. For example, <head> tags will be rendered bold, <note> tags indented, etc. The user can switch between both modes while viewing the document.
When generating a new digital citation with our application, basically the current URN is changed. There are two possibilities to do so. First, the scholar can click on one of the labels of the nodes in the distant view component. This selects the corresponding entire citation node. Second, the user can mark the desired text passage in the text reader component with the mouse, and then click the “Set Citation” button. The updated URN then represents the selected text passage. Finally, a popup dialog helps to export the URN or the text it is referring to. This includes the possibility to generate a link pointing to our web application showing the generated citation.
4. Conclusion
The proposed CTRaCE interface is based on Canonical Text Services in order to provide an online service to generate citations of digital text editions. Such a front-end allows humanities scholars not only to close read texts, but also to identify and retrieve text passages of interest. The interface offers the possibility to generate and export citations of textual works down to the character level. Moreover, CTRaCE is a service that is capable of resolving existent or with CTRaCE generated citations by opening the referenced text passage.
As of now, CTRaCE is a very helpful tool for humanities scholars who want to produce machine readable citations. Future steps in the development of CTRaCE include visualizations of different kinds of annotations on a CTS passage produced by different scholars to facilitate the collaborative work on a shared text of interest.
5. Acknowledgments
Parts of the work presented here is the result of the project “Die Bibliothek der Milliarden Wörter” funded by the European Social Fund. We additionally want to thank Monica Berti for the valuable input and discussion about use cases for our application.
6. Notes
1. http://www.homermultitext.org/hmt-doc/cite/
2. https://www.ietf.org/rfc/rfc2141.txt
3. https://github.com/cite-architecture/ctsurn_spec/blob/master/md/specification.md
4. https://github.com/PerseusDL/canonical
5. http://www.tei-c.org/index.xml
6. https://github.com/cite-architecture/cts_spec/blob/master/md/specification.md
- Smith, D. N. and Blackwell, C. (2012). Four URLs, Limitless Apps: Separation of concerns in the Homer Multitext Architecture. In Muellner, L. (ed.), Donum natalicium digitaliter confectum Gregorio Nagy septuagenario a discipulis collegis familiaribus oblatum, Washington, DC: The Center for Hellenic Studies of Harvard University.
- Tiepmar, J., Teichmann, C., Heyer, G., Berti, M., and Crane, G. (2014). A New Implementation for Canonical Text Services. In Proceedings of the 8th Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities (LaTeCH), Association for Computational Linguistics.