Authors: Stefano Perna, Raffaele Guarasci, Alessandro Maisto, Pierluigi Vitale
Category: Paper:Short Paper
Keywords: linguistics, music, text-mining, data-visualization, rap
RAPSCAPE – un’esplorazione dell’universo linguistico del rap attraverso il text-mining e la data-visualization
In questo lavoro descriviamo un progetto di ricerca, attualmente in corso, dedicato all’analisi dell’universo linguistico e semantico della musica rap, con particolare attenzione rivolta alla realtà italiana. L’obiettivo del lavoro è quello di arrivare ad offrire una mappatura panoramica, una “distant reading” della lingua usata dal rap italiano.
La scelta di questo genere è motivata dal fatto che il rap è tra i fenomeni più vitali e dal maggiore impatto socioculturale della musica e delle sottoculture giovanili degli ultimi decenni (Lena, 1995; Toop, 1999; Forman and Neal, 2004; Pinkney, 2007), esteso ormai ben oltre gli originari confini statunitensi per divenire fenomeno globale (Androutsopoulos and Arno 2003; Osumare, 2007; Alim et al., 2008) e all’interno del quale è possibile riscontrare una ricchissima produzione testuale ed un alto tasso di innovazione e sperimentazione di forme linguistiche (Cutler, 2007; Bradley, 2009; Terkourafi, 2010).
L’idea alla base del lavoro è quella di ottenere una “cartografia” della lingua del rap, che permetta di osservare e analizzare nel suo complesso un settore della produzione culturale contemporanea estremamente diffuso e popolare anche in Italia (Pacoda 1996; Filippone and Papini, 2002; Attolino, 2003; Scholz, 2005). In questo lavoro focalizziamo l’attenzione principalmente sulla dimensione testuale del rap piuttosto che su quella musicale, pur trattandosi di un genere in cui il rapporto tra parola e ritmo è inestricabile (Bradley, 2009). In ogni caso, è possibile affermare che la componente testuale nel rap occupa un ruolo centrale e che la specificità del vocabolario, dei temi, della capacità di invenzione linguistica nonché l’importanza dell’aspetto narrativo (Attolino, 2012) fanno dei testi del rap un corpus linguistico interessante da analizzare in sè.
A tal fine, piuttosto che soffermare l’attenzione su di un numero limitato di testi da analizzare in profondità, mettiamo in campo una metodologia di lavoro multidisciplinare - in cui convergono web data-mining, linguistica e information design – con l’obiettivo di giungere alla costruzione di un database testuale molto ampio da sottoporre ad analisi mediante strumenti di text-mining e di linguistica computazionale e da rendere esplorabile mediante una serie di visualizzazioni interattive elaborate ad-hoc.
In una prima fase si è proceduto all’individuazione di alcune web-repository contenenti le trascrizioni dei testi delle canzoni rap in lingua italiana. Non essendo le fonti ufficiali (siti personali degli artisti, siti delle etichette, libretti dei CD, ecc.) particolarmente ricche di informazioni, sono stati individuati alcuni popolari siti di text-sharing, dove fan e ascoltatori forniscono spontaneamente le proprie trascrizioni dei testi degli artisti.
Sulle fonti selezionate è stato addestrato uno script di web-scraping, sviluppato appositamente, in grado di estrarre, per ogni brano presente sul sito, il testo e i meta-dati di riferimento (titolo brano, nome autore, collaborazioni, album). Una volta addestrato lo script si è passati alla fase di estrazione dati vera e propria che ha portato alla costruzione di un database di circa quindicimila brani. Il risultante database è stato poi sottoposto ad una prima fase di pre-processing e data-wrangling per renderlo disponibile all’analisi successiva. Sul testo estratto dal web è stata effettuata una profonda ripulitura con metodi semi-automatici in modo da ottenere un corpus omogeneo di testi trattabili computazionalmente.
Alla fase di estrazione e standardizzazione del dataset segue la fase di analisi linguistica. In questa fase teniamo conto di alcuni studi precedenti condotti nell’ambito del MIR - Music Information Retrieval, in particolare quelli rivolti all’analisi automatica dei testi delle canzoni (Mahedero et al., 2005; Kleedorfer et al., 2008; Hu et al., 2009) e dei testi rap in particolare (Hirjee and Brown, 2009; Hirjee and Brown, 2010; Malmi et. al, 2015).
Il corpus è processato usando l’intera pipeline di analisi linguistica (Manning and Schütze, 1999) già ampiamente nota nei task di NLP: tokenizzazione, lemmatizzazione e pos tagging. Successivamente si è passato ad un’analisi statistica per ottenere le frequenze assolute dei termini, le frequenze relative per autore, le collocazioni, i bigrammi e i trigrammi ricorrenti e la forza di associazione tra le parole espressa in termini di PMI (Pointwise Mutual Information). Gli strumenti utilizzati per effettuare queste analisi sono basati sulla libreria NLTK in Python (Loper and Bird, 2002). Una volta estratti i Lemmi con le rispettive frequenze, viene calcolato il valore di Term Frequency/ Inverse Document Frequency (TF/IDF) per ogni lemma in modo da estrarre le parole più significative per ciascun autore. Una matrice di co-occorrenza, precedentemente costruita su un corpus di circa 3 milioni di parole, attraverso l'applicazione di un algoritmo di Distributional Semantics chiamato HAL - Hyperspace Analogue to Language (Burges and Lund, 1995), è utilizzata per estrarre le parole con valori di similitudine semantica maggiori per ogni lemma, allo scopo di creare un network di significati che identifichi lo spazio semantico di ciascun autore e permetta la loro classificazione attraverso algoritmi di machine learning (clustering).
I dati risultanti dall’analisi linguistica sono strutturati in un database adatto all’elaborazione dei software e dei processi di data visualization. L’obiettivo di questa parte del progetto è quello di costruire un tool interattivo che utilizzi tecnologie web (html, css, javascript) per rendere il dataset esplorabile, comunicabile e analizzabile ulteriormente. Per l’elaborazione del sistema di visualizzazione prendiamo in esame le specifiche problematiche poste dalla visualizzazione di grandi corpora testuali (Wise et al., 1995; Fortuna et al., 2005; Alencar et al., 2012; Sinclair et al., 2013; Kucher, 2014; Brath and Banissi, 2015) e le soluzioni approntate da alcuni lavori precedenti sulla visualizzazione di database composti da testi di canzoni (Labrecque, 2009; Baur et al., 2010; Oh, 2010; Sasaki et al., 2014).
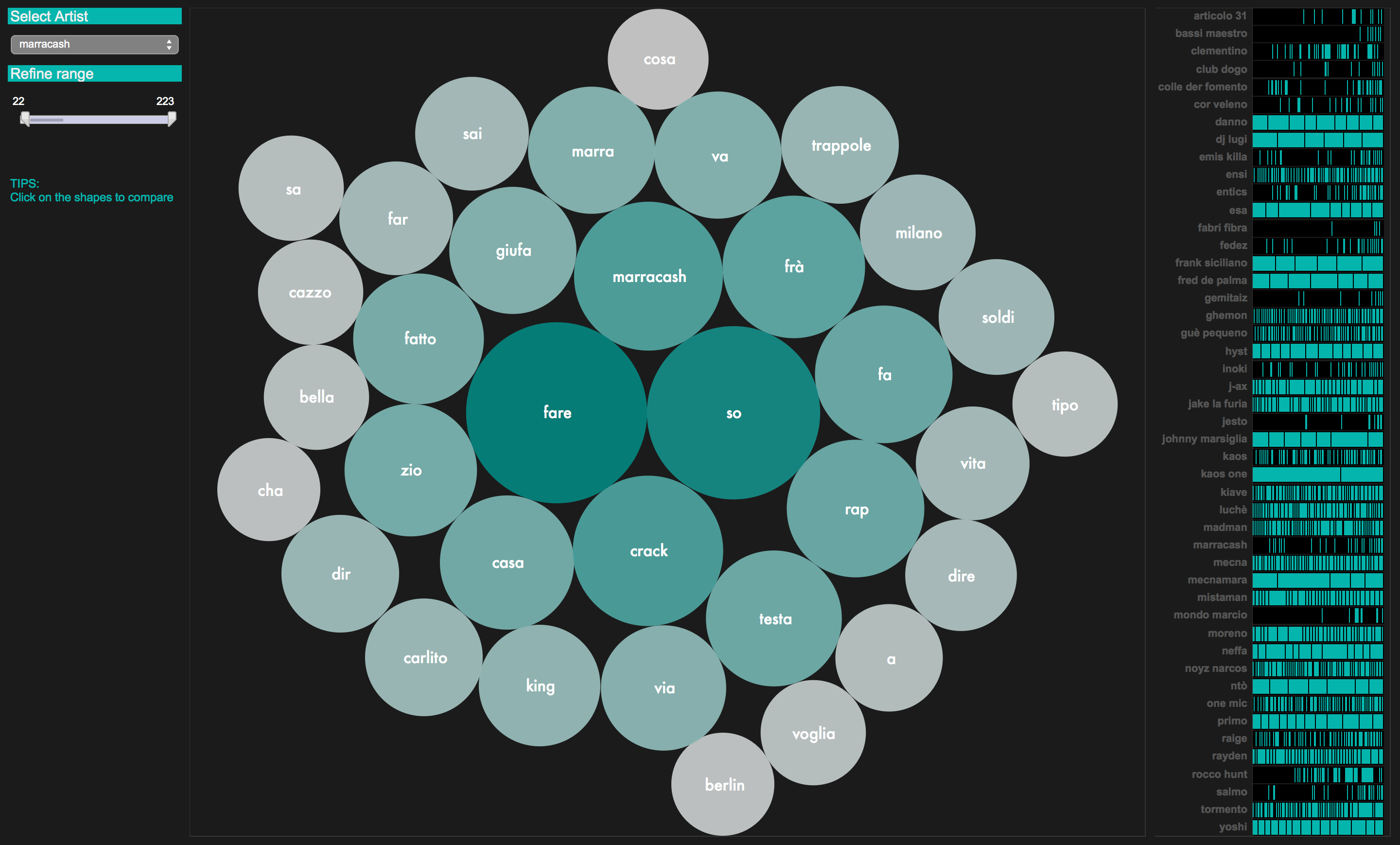
Il tool di visualizzazione si compone di una serie di “viste” e di filtri di navigazione che permettono di osservare il dataset da più angolazioni e attraverso diversi livelli di dettaglio, secondo il classico pattern Overview first, zoom and filter, then details-on-demand (Shneidermann, 1996). Oltre agli approcci classici dell’Information Visualization, la progettazione delle visualizzazioni tiene conto dell’approccio maturato dal design della comunicazione nell’ambito delle Digital Humanities (Uboldi and Caviglia, 2015) in paritcolare per quanto riguarda la definizione della user experience.
Una serie di layer di visualizzazione sono combinati in delle viste panoramiche che offrono uno sguardo complessivo su diversi aspetti del database: statistiche di base come le frequenze e le distribuzioni dei termini più utilizzati; la varietà complessiva del vocabolario; una serie di ranking; reti bipartite tra autori e termini; reti tra parole e relativi cluster semantici più evidenti.
Filtri e viste secondarie sono progettati invece per muoversi rapidamente tra diversi livelli e prospettive sul dataset e di scendere nel dettaglio per analizzare i dati relativi al singolo autore (termini più frequenti, temi dominanti, ecc) o al singolo brano. E’ inoltre possibile operare comparazioni tra autori (o gruppi di autori), o tra brani (o gruppi di brani). La visualizzazione è progettata dunque principalmente come strumento esplorativo in modo tale da rendere possibile l’analisi dell’universo testuale del rap a diversi livelli di profondità e granularità.
- Alencar, A. B., Oliveira, M. C. F. de and Paulovich, F. V. (2012). Seeing beyond reading: a survey on visual text analytics. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 2 (6): 476–92.
- Alim, H. S., Ibrahim, A. and Pennycook, A. (2008). Global Linguistic Flows: Hip Hop Cultures, Youth Identities, and the Politics of Language. Routledge.
- Androutsopoulos, J. and Scholz, A. (2003). Spaghetti Funk: Appropriations of Hip-Hop Culture and Rap Music in Europe. Popular Music and Society, 26(4): 463–79.
- Attolino, P. (2003). Stile ostile, CUEN.
- Attolino, P. (2012). Iconicity in Rap Music The challenge of an anti-language. Testi e Linguaggi, 6: 17–35.
- Baur, D., Steinmayr, B. and Butz, A. (2010). SongWords: Exploring Music Collections Through Lyrics. In ISMIR, pp. 531-36.
- Bradley, A. (2009). Book of Rhymes: The Poetics of Hip Hop. Basic Books.
- Brath, R., and Banissi, E. (2015). Using Text in Visualizations for Micro / Macro Readings. Proceedings of the IUI Workshop on Visual Text Analytics. Retrieved from http://vialab.science.uoit.ca/textvis2015/papers/Brath-textvis2015.pdf
- Burgess, C., and Lund, K. (1995). Hyperspace analog to language (hal): A general model of semantic representation. In Proceedings of the annual meeting of the Psychonomic Society, 12: 177-210.
- Church, K. W. and Hanks, P. (1990). Word Association Norms, Mutual Information, and Lexicography. Comput. Linguist., 16(1): 22–29.
- Cutler, C. (2007). Hip-Hop Language in Sociolinguistics and Beyond. Language and Linguistics Compass, 1 (5): 519–38.
- Filippone, A. and Papini, L. (2002). La parola e il suo potere: Il linguaggio del rap italiano. Rassegna italiana di linguistica applicata, 33(3): 71–86.
- Forman, M. and Neal, M. A. (2004). That’s the Joint!: The Hip-Hop Studies Reader. Psychology Press.
- Fortuna, B., Grobelnik, M. and Mladenić, D. (2005). Visualization of text document corpus. Informatica, pp. 497–502.
- Hirjee, H. and Brown, D. G. (2009). Automatic Detection of Internal and Imperfect Rhymes in Rap Lyrics. Proceedings of the 10th International Society for Music Information Retrieval Conference, pp. 711–16.
- Hirjee, H. and Brown, D. G.(2010). Rhyme Analyzer: An Analysis Tool for Rap Lyrics. Proceedings of the 11th International Society for Music Information Retrieval Conference.
- Hu, X., Stephen, J., Andreas, D. and Ehmann, F. (2009). Lyric text mining in music mood classification. Proceedings of the International Society for Music Information Retrieval Conference.
- Kleedorfer, F., Knees, P. and Pohle, T. (2008). Oh Oh Oh Whoah! Towards Automatic Topic Detection In Song Lyrics. Proceedings of the 9th International Conference on Music Information Retrieval (ISMIR 2008), pp. 287–92.
- Kucher, K., and Kerren, A. (2014). Text Visualization Browser: A Visual Survey of Text Visualization Techniques. In IEEE Information Visualization (InfoVis' 14), Paris, France.
- Labrecque, A. (2009). Computer Visualization of Song Lyrics. Doctoral dissertation: Worcester Polytechnic Institute.
- Lena, J. C. (2006). Social Context and Musical Content of Rap Music, 1979–1995. Social Forces, 85(1): 479–95.
- Loper, E. and Bird, S. (2002). NLTK: The Natural Language Toolkit. Proceedings of the ACL-02 Workshop on Effective Tools and Methodologies for Teaching Natural Language Processing and Computational Linguistics - Volume 1. (ETMTNLP ’02). Stroudsburg, PA, USA: Association for Computational Linguistics, pp. 63–70
- Mahedero, J. P. G., MartÍnez, Á., Cano, P., Koppenberger, M. and Gouyon, F. (2005). Natural Language Processing of Lyrics. Proceedings of the 13th Annual ACM International Conference on Multimedia. (MULTIMEDIA ’05). New York, NY, USA: ACM, pp. 475–78.
- Malmi, E., Takala, P., Toivonen, H., Raiko, T. and Gionis, A. (2015). DopeLearning: A Computational Approach to Rap Lyrics Generation. arXiv:1505.04771 [cs] http://arxiv.org/abs/1505.04771 (accessed 5 March 2016).
- Manning, C. D., and Schütze, H. (1999). Foundations of statistical natural language processing. Cambridge: MIT press.
- Oh, J. (2010). Text Visualization of Song Lyrics. Center for Computer Research in Music and Acoustics, Stanford University.
- Osumare, H. (2008). The Africanist Aesthetic in Global Hip-Hop: Power Moves. Palgrave Macmillan US.
- Pacoda, P. (1996). Potere alla parola: antologia del rap italiano. Feltrinelli.
- Pinckney, C. (2007). The Influence of Hip-Hop Culture on the Perceptions, Attitudes, Values, and Lifestyles of African-American College Students. ProQuest.
- Sasaki, S., Yoshii, K., Nakano, T., Goto, M., and Morishima, S. (2014). LyricsRadar: A Lyrics Retrieval System Based on Latent Topics of Lyrics. In ISMIR, pp. 585-90.
- Scholz, A. (2005). Subcultura e lingua giovanile in Italia: hip-hop e dintorni. Aracne.
- Shneiderman, B. (1996). The eyes have it: a task by data type taxonomy for information visualizations. IEEE Symposium on Visual Languages, 1996. Proceedings, pp. 336–43.
- Sinclair, S., Ruecker, S., and Radzikowska, M. (2013). Information Visualization for Humanities Scholars. Literary Studies In The Digital Age.
- Terkourafi, M. (2010). The Languages of Global Hip Hop. A&C Black.
- Toop, D. (2000). Rap Attack 3: African Rap to Global Hip Hop. Serpent’s Tail.
- Uboldi, G. and Caviglia, G. (2015). Information Visualizations and Interfaces in the Humanities. In Bihanic, D. (Ed), New Challenges for Data Design. Springer London, pp. 207–18 http://link.springer.com/chapter/10.1007/978-1-4471-6596-5_11 (accessed 5 March 2016).
- Wise, J. A., Thomas, J. J., Pennock, K., Lantrip, D., Pottier, M., Schur, A. and Crow, V. (1995). Visualizing the non-visual: spatial analysis and interaction with information from text documents. Information Visualization, 1995. Proceedings. pp. 51–58.