Authors: Neven Jovanović, Alexander Simrell
Category: Paper:Short Paper
Keywords: linked data, citation scheme, Greek literature, automatic validation
Implementing Canonical Text Services in the Croatiae Auctores Latini Digital Collection
1.
The Canonical Text Services (CTS) protocol (Blackwell and Smith, 2014) offers the scholarly community a way to use URNs for referring to two categories of propositional objects commonly called texts: to their ideal representations, works, and their specific realizations, expressions (International Working Group on FRBR and CIDOC CRM Harmonisation, 2015). CTS URNs point to complete texts and their subdivisions. CTS has a potential to transform scholarly practices. It supports the migration of our interpretations and knowledge from print to digital. It also forces us to reconsider what exactly we are doing when we refer or cite. It could, eventually, integrate into our referring and citing machine-driven comparisons across multiple versions of texts.
The CTS protocol is currently implemented in two projects: the Homer Multitext (Dué and Ebbott, 2015) and the Perseus Digital Library (Crane et al., 1987-). Both focus on texts which have traditionally been considered classical. Centuries, in some cases millennia, of appreciation and careful study have provided us with slightly different, but well-established citation schemes for such texts, and the main challenge to CTS up to now has been to reproduce these schemes. We put the protocol to a new test, by applying it to a non-canonical corpus of Latin texts published in the digital collection Croatiae auctores Latini, CroALa (Jovanović et al., 2009-).
CroALa collects and enables research of texts from a rich tradition of writing in Latin in Croatia. Latin was written through the Medieval and Early Modern periods up to modern times (our latest title is from 1984). The corpus includes a number of translations of Homeric poems into Latin, such as the partial one – an episode from the Iliad - by Janus Pannonius (1447), and a complete Iliad by Rajmund Kunić (1776). We wanted to connect CroALa manifestations (digital editions) of these expressions to the Iliad as work, thus making possible a connection to manifestations of its other expressions, published elsewhere – in our case, to the Greek editions published by the Homer Multitext.
The process involved three stages: making the CroALa texts canonically referable through XML catalog records, validating and verifying the prepared editions, and establishing connections between editions prepared by different projects.
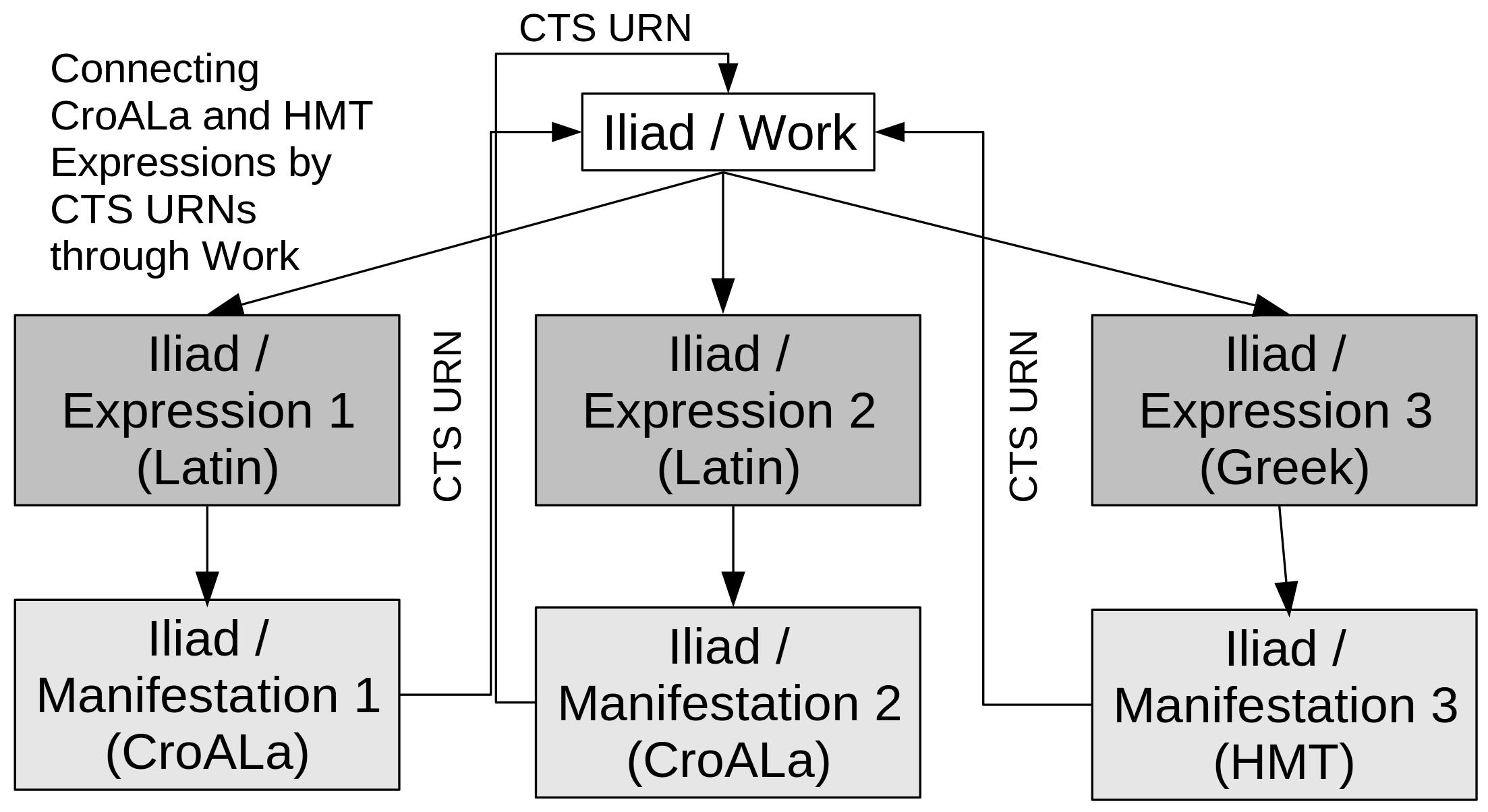
Homer Multitext have produced URNs for each line of the Iliad as work; e. g. book 6, line 119 is described by urn:cts:greekLit:tlg0012.tlg001:6.119. A RDF triple connects this to URN of a line in the edition of the Venetus A codex (urn:cts:greekLit:tlg0012.tlg001.msA:6.119). Something similar is done for CroALa; you can see t he work URN implied in the URN of a line our edition of Janus Pannonius’ Latin translation (which is an expression fragment): urn:cts:greekLit:tlg0012.tlg001.croala-lat01:6.119. The same work URN is also implied by a line in the edition of Rajmund Kunić's complete Latin expression of the Iliad: urn:cts:greekLit:tlg0012.tlg001.croala-lat02:6.119.
The referencing happens through CTS Text Inventory (CTS TI), an XML catalog file. There Janus Pannonius' text is described by the following fragment:

The TEI XML guidelines allow multiple ways of marking up text structures (Schmidt, 2014). Therefore the most important sections in the fragment above are the XPaths which describe locations of individual books and linesin our editions. Books and lines can be encoded in a different way, represented by different XML elements, but through CTS URNs we are still able to connect the corresponding points, just as we refer to the same verse in the Iliad-as-work regardless of the fact that it is realised (printed or written) on different pages in different editions (Manifestation Product Types).
Our descriptions have also to be checked for correctness. Here the Homer Multitext project also can help; they have developed an excellent system for automated validation of editorial descriptions. We are adapting this to ensure that everything works in CroALa CTS, that no errors are introduced during the encoding process.Validation happens in a Virtual Machine which ensures that the entire process is replicable (Smith, 2015). But, since faithful replication of the process will only faithfully replicate systematic errors, a validation system was developed to assess our work in a different method, independent of how it was created.
The system first tokenizes all of the words. Parsley, a parsing machine for Latin morphology (Schmidt, 2015), checks that all tokens are valid Latin forms. Personal and geographic named entities do not parse automatically, so the system analyzes these separately. Named entities are checked for consistent markup and for compliance with our authority lists. The tokens that do not parse at either of these stages are analyzed by a researcher.
What has been validated has also to be verified as correct; our validation system ensures that all the tokens are acceptable Latin forms, but researchers have to ultimately decide whether the forms were correctly used.
Forms that are identified as being invalid are analyzed further for encoding errors, incorrect entries, problems with the parsing machine. One of recurring problems is that neo-Latin vocabulary is missing from the classical Latin dictionary used by the parser, so new words should be added to the lexicon. Even more numerous are neo-Latin forms that orthographically (sometimes morphologically too) violate classical Latin rules. Such forms have to be matched with the classical equivalents so that they can be accepted when the machine comes across these forms again. A similar approach would be required for all editions in which language differs markedly from the standard modern variant - e. g. for the Early Modern English as used in Shakespeare.
Once we have a text referenced by canonical URNs and tested as validated and verified CTS, we can serve the URNs and retrieve them from wherever we want. Connecting different editions - for example, linking Croatian Latin translations of Homer to editions of manuscripts prepared by the Homer Multitext project - is then a question of aligning the two sets of URNs. These aligned sets will enable us later, for example, to display in parallel the texts served behind each of them.
Though clear and simple in principle, the actual application of CTS to CroALa texts opened up a series of practical questions with certain theoretical implications. We mention only two.
First, a text and its translation are not always in a 1 : 1 relationship. A verse of the original can be rendered by verse and a half, or by a half verse, in the translation; a description ("Peleiades") can be glossed ("Achilles"). This had to be taken into account during the process of editorial verification. We had to introduce additional checks for translation alignments and establish a procedure for marking places where translation "shifts" equivalents forward or back in the textual structure (Latin equivalent of a Greek word appears elsewhere in the sentence, and therefore may appear in a different line).
Second, Croatian Latin translations of the Iliad are expressions of the Homeric work, but at the same time they themselves are of potential interest as authorial works, and they themselves exist in multiple manifestations (Kunić's translation was published in Rome 1776, Venice 1784, Vienna 1784, Firenze 1831 and 1838). To enable detailed scholarly study of translation as a work, the system has to take into account this additional level of multiplicity too: not only Homer Multitext, but also a Kunić Multitext (with the same underlying work).
Among the grand visions of digital humanities there is a dream of a world - or a space - in which different digital editions, carefully prepared, annotated and interpreted, mesh easily together, thus providing an especially rich and detailed groundwork for further annotations and interpretations. This space of interchangeability is today attained only rarely and with difficulty. The level of difficulty can be significantly lowered, as shown by CroALa's successful implementation of CTS and its automated validation and verification processes. A further step towards interchangeability will be wider acceptance of a digital canonical reference system such as CTS. For this to happen, a series of applications and "recipes" for specific usage cases is needed. We hope to have offered one such recipe here.
- Blackwell, C. and Smith, N. (2014). Homer Multitext. Canonical Text Services protocol specification (accessed 4 March 2016).
- Crane, G., Beaulieu, M.-C., Almas, B., Babeu, A. and Cerrato, L. (1987-). Perseus Digital Library (accessed 4 March 2016).
- Dué, C. and Ebbott, M. (2015). The Homer Multitext project (accessed 4 March 2016).
- International Working Group on FRBR and CIDOC CRM Harmonisation (2015). Definition of Object-Oriented FRBR (accessed 4 March 2016).
- Jovanović, N., Haskell, Y., Lonza, N., Lučin, B., Marinova, E., Novaković, D. and Tunberg, T. O. (2009-). CroALa: Croatiae auctores Latini (accessed 4 March 2016).
- Schmidt, D. (2014). Towards an Interoperable Digital Scholarly Edition. Journal of the Text Encoding Initiative(Issue 7) doi:10.4000/jtei.979. (accessed 4 March 2016).
- Schmidt, H. (2015). goldibex/parsley-core GitHub (accessed 4 March 2016).
- Smith, N. (2015). homermultitext/vm2015 GitHub (accessed 4 March 2016).