Authors: Deborah Anderson, Carlos Pallán Gayol
Category: Paper:Long Paper
Keywords: encoding, Unicode, Mayan, hieroglyphs
Unlocking The Mayan Script With Unicode
1. Problem
At present, three hieroglyphic scripts are encoded in the Unicode Standard: Egyptian, Anatolian, and Meroitic. The historic Mayan hieroglyphic script is not yet in Unicode, in part because its complex clustering poses special encoding problems.
Besides the difficulties inherent in the Mayan script, writing a Unicode proposal for Mayan involves additional challenges, requiring significant time commitment and travel. Early meetings between with Unicode experts are a desideratum in order to identify the best technical approaches to handle Mayan text issues. Then the proposal needs to be written – complete with all the required details for the entire character repertoire. When the proposal goes before the two standards committees, the authors need respond to any questions, and make revisions to the proposal as needed. In addition, proposers need to commit to seeing the process through to the end, which can take between two to five years, or longer.
In short, the twin challenges of representing and displaying Mayan clusters on computers and writing a Unicode proposal (especially for anyone new to the process) present a huge hurdle.
2. Background on Mayan clustering
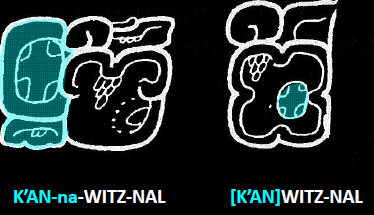
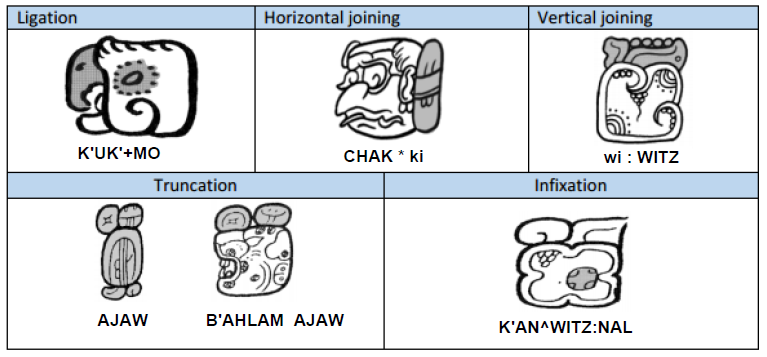
Mayan signs appear in clustered glyph-blocks or "collocations,” which could be modified by the masterful Mayan scribes with advanced “tools,” such as ligatures, conflation, infixation, superimposition, pars pro toto and full-figure variants (see Fig s. 1 and 2). The visual complexity of Mayan requires mechanisms that go beyond standard script encoding approaches.

3. Solution
A recent multidisciplinary collaboration established between UC Berkeley's Script Encoding Initiative (SEI) and the MAAYA Project aims to employ new methods combining linguistics, Mayan epigraphy, digital palaeography and computer vision to overcome some of the major challenges preventing the encoding of Mayan hieroglyphs in the Unicode Standard. Some of the strategies envisioned rely on already existing MAAYA-Project resources. Such resources include datasets with annotated database records for all individual glyphs and possible sign-combinations attested in Mayan hieroglyphic books and an advanced concordance functionality, that cross-references Mayan signs across existing glyph-catalogues (Gatica-Perez et al., 2014 and Hu et al., 2015).
In addition, SEI's experience in overseeing the encoding over 70 of the world script systems means Mayan experts will have a front-line guide to help the proposal through the entire encoding process – providing Unicode expertise, assisting on the authoring and review of a proposal, and presenting the proposal at standards meetings. Having direct involvement of Unicode specialists means the proposal can draw on Unicode experience to identify successful methods that can adapted and expanded to account for the extraordinary variability of Mayan signs clustered in glyph blocks.
4. Specific encoding issues: Egyptian format characters
In Unicode 8.0, the default display for the three encoded hieroglyphic scripts (Egyptian, Anatolian and Meroitic Hieroglyphs) is a linear listing of the characters, as shown by the example in Fig. 3.
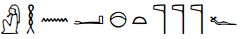
According to the Unicode Standard, display of the characters in a non-linear manner (i.e., in clusters) should be handled by a higher-level protocol (Unicode Consortium 2015: 430-31, 437), and is outside the scope of Unicode. However, clustering is more typical of the layout for most hieroglyphic scripts.
Although Egyptian hieroglyphs were encoded in Unicode in 2009, Egyptologists are currently prevented from interchanging data easily, because they have had to rely on non-standard software to handle character grouping. According to Richmond 2015, hieroglyphs need to be capable of being grouped together in plain-text - without proprietary software - in order to be truly useful.
In 2015, a new proposal was put forward for three format characters that allows basic clustering (Richmond, 2015, see Fig. 4). The characters indicate placement of a character, either above another character or alongside it, or, for the third character, identify it as forming a ligature with the following character. The three characters are based upon the conventions of the Manual de Codage, which uses ASCII characters to indicate the placement of the hieroglyphs. (Note: Since the mirroring of glyphs is handled by line direction, as specified by markup or bidirectional characters, no format characters are not proposed for that.)
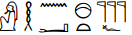
The three Egyptian format characters were approved by one of the two standards committees in January 2016 (Unicode Consortium, 2016). The characters have been tested and shown to display as expected in the Universal Shaping Engine, a rendering engine in Windows 10 and recent versions of Android, Chrome, LibreOffice and Firefox.
If the characters successfully complete the approval process, simple clustering in Egyptian hieroglyphs should be capable of plain-text representation in the future, meaning that scholars would not have to rely on an ad hoc, non-standard solution. At this point, Egyptian hieroglyphs appear to only require the three format control characters for clustering, and need no other mechanisms.
Evidence from the MAAYA project suggests that Mayan will require three script-specific format characters that serve the same functions as Egyptian, and at least two additional characters: one for truncation and another for infixation (see Fig. 5).
Hence, it appears that Egyptian and Mayan can share a common model, using format characters for clustering (with at least two additional ones needed for Mayan). In addition, advances in text display of Egyptian hieroglyphs, which have been tested successfully on the Universal Shaping Engine, may well be applicable to Mayan.
5. Specific encoding issues: Ideographic Description Characters
Unicode contains a mechanism to describe Chinese-Japanese-Korean (CJK) ideographs, called Ideographic Description Characters (IDCs). These characters are used to describe the layout of CJK characters, but is not used for rendering. The IDCs have been defined as capable of being extended to other scripts (Unicode Consortium 2015, pp. 679-80). (See Fig. 6.)
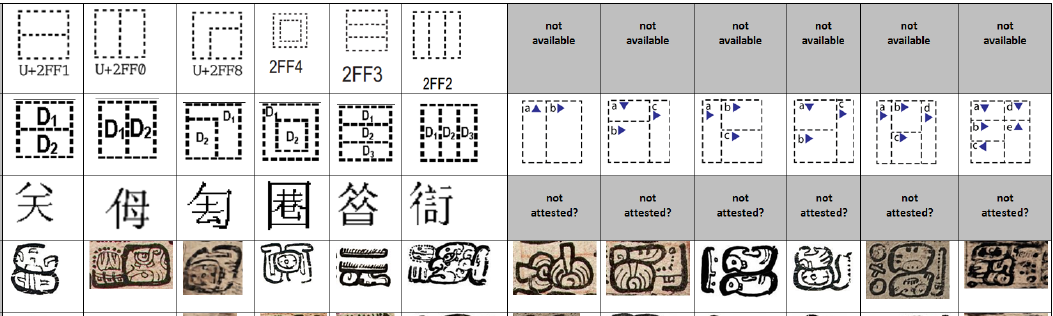
In April 2015, Unicode experts met with the co-author, Mayan expert Carlos Pallán Gayol, and recommended the MAAYA project identify the structural patterns of Mayan characters, and use Ideographic Description Characters (IDCs) to describe them. Such a mechanism will help in defining Mayan characters (in Unicode terms), and help “unlock” the script.
6. Next steps
At a meeting in January 2016 with the co-author Pallán Gayol, unicode experts noted progress on the encoding model issues and suggested the MAAYA project continue to define the base set of characters, identify the structural patterns of IDCs, and verify the number of format characters needed.
7. Expected results
Encoding the Mayan hieroglyphs in the Unicode format will allow creation of vast open-access Mayan hieroglyphic text repositories and libraries, upon which advanced search and query functionalities relying i.e. on Optical Character Recognition (OCR) and text-mining could be applied. (Once a script is in Unicode, an OCR engine can be trained to read the script, though the text needs to be consistent).
Thus, we argue that the ability to render any Mayan hieroglyphic text in an encoded digital format could impact on the overall accessibility, reproduction, visualization and long-term preservation of the sum of ancient knowledge recorded by the Mayan scribes on thousands of texts and inscriptions produced between ca. 250 B.C. and 1520 AD in Central America. It could also act as a model for the encoding of other hieroglyphic scripts of the Americas, including Aztec.
8. Funding
This work was supported by the National Endowment for the Humanities [PR-50205-15] and by the DFG (Deutsche Forschungsgemeinschaft, German Scientific Association).
- Gatica-Perez, D. C., Pallán Gayol, S., Marchand-Maillet, J.-M. et al. (2014). The MAAYA Project: Multimedia Analysis and Access for Documentation and Decipherment of Mayan Epigraphy. In Proc. Digital Humanities Conference (No. EPFL-CONF-202571). http://publications.idiap.ch/downloads/papers/2014/Gatica-Perez_DH_2014.pdf (accessed 2 March 2014).
- Hu, R., Can, C., Pallán Gayol, G. et al. (2015). Multimedia Analysis and Access of Ancient Mayan Epigraphy. Signal Processing Magazine, IEEE, 32(4): 75-84. http://publications.idiap.ch/index.php/publications/show/3093 (accessed 2 March 2014).
- Richmond, B. (2015). Proposal to encode three control characters for Egyptian Hieroglyphs. http://www.unicode.org/L2/L2015/15123r-egyptian.pdf (accessed 2 March 2014).
- Richmond, B. and Glass A. (2016). Proposal to encode three control characters for Egyptian Hieroglyphs. http://www.unicode.org/L2/L2016/16018r-three-for-egyptian.pdf (Accessed 2 March 2014).
- Unicode Consortium. (2015). The Unicode Standard, Version 8.0.0.. Mountain View, CA: The Unicode Consortium. http://www.unicode.org/versions/Unicode8.0.0/ (accessed 2 March 2014).
- Unicode Consortium. (2016). Draft Minutes of UTC Meeting 146. San Jose, CA. http://www.unicode.org/L2/L2016/16004.htm (accessed 2 March 2014).