Authors: Peggy Bockwinkel
Category: Paper:Short Paper
Keywords: computational stylistics, narratology, deictics, quantative analysis, character speech
Does Character Speech Matter? A Quantitative Approach
1. Introduction
Character speech is an elementary part of novels. When calculating with German-speaking novels, the question arises, if there is a stylistic difference between character and narrator speech. Given the presupposition that character speech imitates authentic communication, I will answer these questions with a structured series of experiments on deictic expressions, based on statistic and linguistic knowledge.
Theoretical background
Character speech is defined here as direct or cited/quoted speech, the words and sentences one finds between quotation marks. By drawing on these distinct punctuation markers, it can be separated automatically from the rest of the text. With the beginning of modernism, however, these formal structures have started to dissolve. Between the clear marking of character speech and no marking at all, gradual stages are possible. In these cases, a considerable effort is required to automatically separate character speech from the rest of the novel. An examination of the differences between character and narrator speech therefore can be useful to assess the necessity of such a costly separation.
Deictics are necessary in communication situations to refer to a point in time, space or to certain objects or persons like the speaker or the addressee. In the sentence
Tomorrow I will be there.
every word is deictical. Deictics are context-dependent, which means that in different situations they have different meanings. They belong to different lexical categories – but most of them are function words. The presented approach implies the following premises:
1. Different (non-fictional) texts types show a different frequency of deictic terms. These basic text types have been categorised according to three criteria of communication (dialogical, face-to-face and oral by Diewald, 1991).
2. Character speech imitates a dialogue – which is one of these basic text types.
Transferring the first premise on fiction, literary genre-categorisation has to stand back: character speech in novels and plays would belong to one basic text typ.
2. Previous Work
Previous research on character speech in the humanities shows, that it seems to be a subject mainly in the philosophy of language (see Pafel and Dirscherl, 2015). In literary studies, only one monograph on direct speech exists (Müller, 1981). Recently Brunner (2015) showed that the automated tagging of different kinds of speech in German-speaking novels with computerlinguistic methods is possible, but still has weak results – except for direct speech. Her corpus consisted of 13 different novels, which is a rather small corpus. In computational stylistics it appears that most approaches tend to use smaller corpora (e.g Burrows, 1987; van Dalen-Oskam, 2014).
3. Method
For the corpus, German-speaking plays and novels from the 18 th to the 20 th century are selected randomly. They are separated into several subcorpora consisting of 25 plays and 75 novels, including the Brunner corpus with 13 novels (Fig. 1).

The subcorpus with the plays serves as a benchmark/reference value: Since plays consist mostly of character speech, they can be compared with the plays and novels_character speech only-subcorpus. Gries 2008 serves for the statistical basis. Eder’s structured experiments in “Does size matter?” (2013) serve as a template for the presented analyses. That means parameters are changed in a consistent and transparent way through the experiment:
The experiment – counting the deictic terms – is run several times (Fig. 1): At first, the whole corpus is tested. For the second run the novels are separated from the plays and for the third run character speech is separated from the rest of the text. Finally, the Brunner corpus is run a forth time with the other categories of speech, e.g. free indirect speech, separated as well.
Since there is no common definition of deictics, nothing like a deictic lexicon exists. In my analyses, I will use a rather straightforward approach: An expression will be regarded as deictic, if it belongs to one of the main deictic categories like time, space, or person and if the deictic reference is its main function. This definition excludes verbs, but includes all function words like temporal and spatial adverbs and a small group of personal pronouns.
4. Results sample corpus
As a starting point for upcoming research I will present temporary results that are generated by drawing on a small sample corpus of novels in which character speech is separated from the rest of the text and the frequency of deictic terms is analysed (Fig. 2). Then the results are compared with Diewald’s results for the basic text types in non-fiction (Fig. 5).
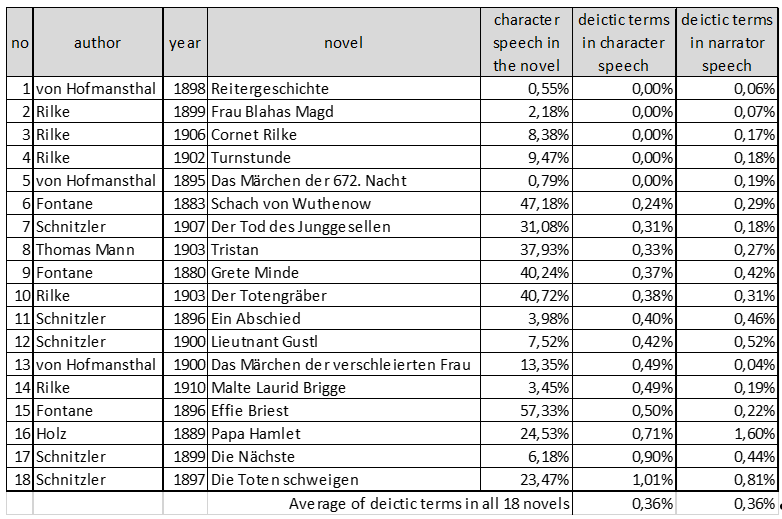
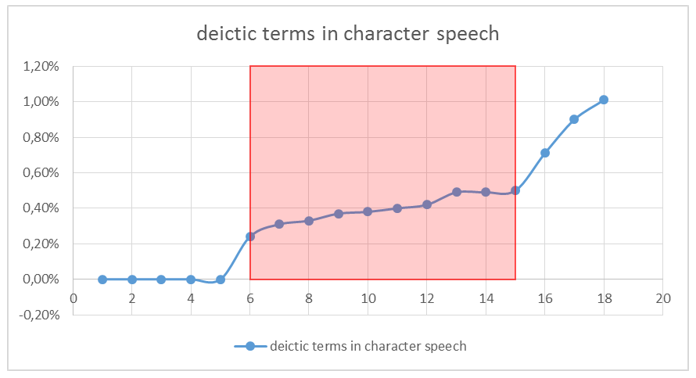
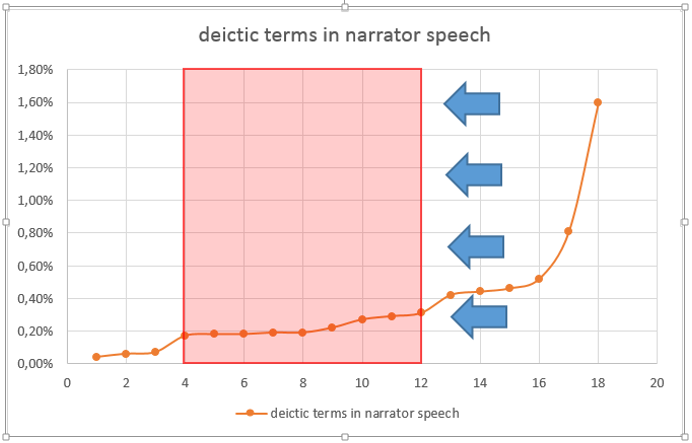
The average values for character and narrator speech (0.36% in either case) show no difference at all (Fig. 2). However, a closer look on the frequency distribution draws another picture: Figure 2 shows that most of the novels (novels 6 to 14) range around 0,4% deictic terms in character speech. In figure 3 the results seen in figure 2 are visualised: in contrast half of the deictic terms in the narrator speech of the novels range a bit higher than 0,2%. This shift is marked by the blue arrows (Fig. 3 + 4). The stability of these results will be evaluated on the complete corpus (see “Methods”).
5. Conclusions
According to Diewald’s results the deictic frequency of basic text types is lowest in letters and written monologues. Dialogue and oral monologue present a higher frequency of deictic terms, but still topped by telephone conversation (Fig. 5). Regarding their principle structure, character speech can be assigned to the basic text types, dialogue and oral monologue, whereas narrator speech resembles written monologue and letters.
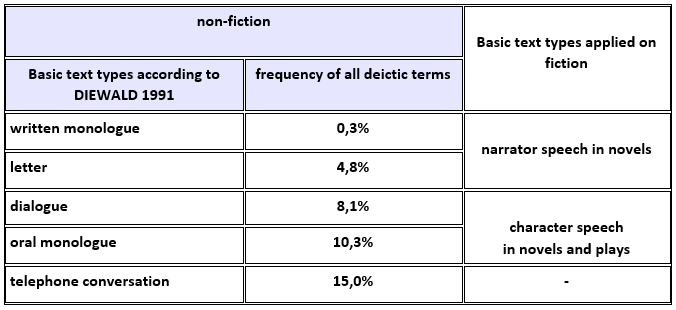
Accordingly, the results of the sample corpus indicate a lower deictic frequency in narrator speech compared to character speech, which matches DIEWALD’s results on deictic frequency in the basic text types.
Still, for the sample corpus, it is quite problematic to compare these numbers with DIEWALD’s results, because in the non-fictional discourses all deictic terms are analysed instead of only two prototypic ones ( here, now). Since it seems that there is a difference between both types of speech in novels, it nevertheless has to stand the test of the broader experiments with the bigger 100 texts corpus. In addition, for further research another series of this experiment should be run with the same corpus scheme, but set up as a stylometric analysis to see if similar patterns can be found. If the results show a significant difference between character and narrator speech, it is necessary to have character and narrator speech separated in all novels as part of the preparation for digital text analyses.
- Brunner, A. (2015). Automatische Erkennung von Redewiedergabe: Ein Beitrag zur quantitativen Narratologie, Band 47. Berlin/Boston: de Gruyter.
- Bühler, K. (1934/1965). Sprachtheorie. Die Darstellungsfunktion der Sprache. Stuttgart: Lucius and Lucius.
- Burrows, J. F. (1987). Computation into criticism: a study of Jane Austen's novels and an experiment in method. Oxford: Clarendon Press.
- Diewald, G. M. (1991). Deixis und Textsorten im Deutschen. Tübingen: Niemeyer.
- Eder, M. (2013). Does size matter? Authorship attribution, small samples, big problem. In Digital Scholarship in the Humanities Nov 2013, DOI: 10.1093/llc/fqt066 http://dx.doi.org/10.1093/llc/fqt066 .
- Gries, S. T. (2008). Statistik für Sprachwissenschaftler. Göttingen: Vandenhoeck and Ruprecht.
- Müller, A. (1981). Figurenrede. Grundzüge der Rededarstellung im Roman. PhD, Göttingen: Georg-August-Universität.
- Pafel, J., Dirscherl, F. (2015). Die vier Arten der Rede- und Gedankendarstellung: Zwischen Zitieren und Referieren. Linguistische Berichte, 241: 3–47.
- Dalen-Oskam, K. van. (2014). Epistolary voices. The Case of Elisabeth Wolff and Agatha Deken. LLC: The journal of digital scholarship in the humanities. 29(3): 443-51. First published online: May 21, 2014. http://llc.oxfordjournals.org/content/29/3/443.full.pdf?keytype=ref&ijkey=aRCuD3n825cEkmP