Authors: Janet Delve, Sven Schlarb, Rainer Schmidt, Richard Healey
Category: Paper:Short Paper
Keywords: Data Mining, Big Data, Faceted Search, Hadoop, Lily
Using Big Data Techniques For Searching Digital Archives: use cases in Digital Humanities
1. Background
The background for this paper is work in progress in E-ARK: an EC FP7 pilot B project 1 having as its main objective the creation of an open source, digital archiving system with attendant standards and tools to be deployed in seven pilot instances. Hence practical application is at the heart of the project, which is led by archivists, researchers, SMEs, digital preservation / archiving membership organizations and government home offices, who together seek to fill the current digital archiving lacuna. E-ARK is a wide-ranging project: we are taking and integrating existing best practices into a digital archiving system, so that it is suitable not only for national archives and government agencies, but also for regional, local, business and research archives of many shapes and sizes. A legal study taking account of varying national legal directives delineates how the archiving system can be deployed against a pan-European backdrop.
At the heart of the system is the OAIS standard (OAIS), with data arriving at an archive via Submission Information Packages (SIPs), which are then stored in the archive as Archival Information Packages (AIPs) and subsequently retrieved upon access as Dissemination Information Packages (DIPs). E-ARK is also addressing an eclectic range of sources: both structured and unstructured data, atomic and complex, including records from Electronic Records Management Systems (ERMSs); databases; geodata; and computer files.
The project stakeholders are similarly also drawn from a wide pool of varied users, and include public administrations, public agencies, public services, citizens, researchers and business. Re-use of information is a key project objective, and we are employing the latest Big Data tools / techniques / architecture such as Hadoop and Lily to present users with innovative access methods, such as the data mining showcase using geodata. We are also building on techniques used in creating an Oracle data warehouse of US 1880 census data (Healey and Delve, 2007).
Although E-ARK is being spearheaded by national archives, it is a key objective to be relevant and useful to a broad church, and to that end the paper should be of interest to many in the Digital Humanities community, not just archives, so we will be including use cases tailored to this end.
2. Scope of the Paper
E-ARK has conducted a GAP analysis that identifies user requirements for access services, which are described in project report D5.1 (Thirifays et al., 2014). The study investigates the current landscape of archival solutions regarding currently-available access components and identifies gaps and requirements from the perspective of national archives and third party users, as well as content providers. This report has identified a major gap in the identification process, where users browse and search collections to identify material of potential interest. It states that a lack of comprehensive metadata that is available and indexed in finding aids, compromises their performance and efficiency, which directly impacts the user experience and the user’s access to the archival holdings in their entirety.
To fill this gap, work on the E-ARK Faceted Query Interface and Application Programming Interface (API) aims to establish a scalable search infrastructure for archived content. It is important to note that here we are not working with the whole content ecosystem of an archive, but instead concentrating only on indexing and searching of the born-digital E-ARK Information Packages (IPs). The goal is not to replace existing systems but to augment these components (like available catalogues) with a “content repository” that can be searched based on a full text index. This content repository concentrates on search and access based on the content (ie. data/files) contained within an AIP rather than selected metadata elements. The reference implementation employs scalable (cluster) technology, as scalability issues must be taken into account when operating a detailed content-based search facility. A major task in the context of the reference implementation is the development of a faceted query interface for searching archived content that can be utilized directly by end-users or integrated with other software components like archival catalogues.
Work on Query and Indexing concerns the configuration and generation of a repository index that holds detailed information on the archives’ digital holdings. For developing a reference implementation, it is important to provide a solution that is flexible and configurable with respect to a range of requirements. The exact configuration of the faceted search interface will be driven by requirements of the access components (like DIP creation) 2 as well as individual institutional requirements and content specific aspects. As a consequence, the reference implementation developed within E-ARK must provide a configurable query interface that should be accessible via a service API. This API can be used through a web interface and/or an access component for searching the repository based on a full text index.
The reference implementation integrates this query API with a repository implementation, which in turn provides access to an application layer via its access API. The application layer implemented in E-ARK develops end user components for search, access, and display of archived records. Figure 1 provides a conceptual overview of the architecture and workflow supported by the reference implementation.
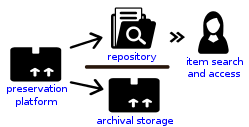
The goal of the E-ARK Faceted Query Interface and API is the establishment of a reference service that enables application components to search through the entire archived data and to link the applications with the data management layer 6 (provided through the content repository). The reference implementation will concentrate on data management functionality that supports search, access, and data mining (like providing a CRUD API and support for versioning). The implementation of a fully-fledged archival data management system, however, is out of focus for the reference implementation.
The search functionality is provided by an indexing infrastructure which generates a full-text index for data being ingested into the data management component (ie. the content repository). The goal is to enable end users to efficiently search archival records based on different aspects (or facets) extracted from the archived data and metadata. The search index includes enclosed archival descriptions (metadata) but most crucially the archived data itself (e.g. based on extracted text portions) and generated technical metadata (like file format information).
The employed indexing techniques are not intended to provide a finding aid based on archival metadata, as for example provided by archival cataloguing systems. The intention of the E-ARK Faceted Query Interface and API is to provide a complementary service that takes advantage of information retrieval techniques like full text indexing, faceted search, and ranking to improve the search through archived data. The indexing workflow is however configurable and able to extract specific information from the archival metadata. This flexibility can for example be utilized to develop specific search facets and/or to handle information related to data confidentiality.
The Faceted Query Interface and API are being developed as part of the E-ARK reference implementation which builds upon a scalable technology stack. The intention is to provide an archiving and search solution that works for different payloads. The reference implementation can therefore be scaled from a single host out to a cluster deployment that is capable of maintaining large volumes of data, e.g. in the magnitude of hundreds of terabytes of archived data organized in hundreds of millions of repository records. The indexing infrastructure is however intended to be deployed next to established archiving systems in order to extend the functionality of the available finding aids. The intention is not to replace the existing systems but rather to extend these infrastructures.
The final paper proposes to add further details of deploying the above scenario with use cases making use of geographic data integrated with the peripleo tool from the Pelagios project 7. We will describe the implementation of a complete archival workflow that includes conversion procedures necessary to support text-based search as well as geographic information retrieval and spatial browsing. We will also show how Big Data techniques such as denormalisation and dimensional modelling used in creating the AIPs can facilitate the discovery methods we outline.
- Healey, R. and Delve, J. (2007). Integrating GIS and Data Warehousing in a Web Environment: A Case Study of the US 1880 census, International Journal of Geographical Information Science, 21(6): 603-24.
- Thirifays, et al. (2014). GAP report between requirements for access and current access solutions. http://www.eark-project.com/resources/project-deliverables/3-d51-e-ark-gap-report (accessed 29 October 2015).
- Thirifays, et al.. (2015). E-ARK DIP draft specification. http://www.eark-project.com/resources/project-deliverables/31-d52 (accessed 5 March 2016).
- OAIS. (2012). Reference Model for an Open Archival Information System (OAIS). http://public.ccsds.org/publications/archive/650x0m2.pdf (accessed 29 October 2015).
E-ARK is funded by the European Commission’s FP7 PSP CIP Pilot B Programme under Grant Agreement no. 620998.
The specific access component requirements are being currently defined in E-ARK and are already partially described in (Thirifays et al., 2015), the report D5.2 “E-ARK DIP draft specification”
Here, data management refers to functionality provided by the content repository introduced by the E-ARK infrastructure, which is intended to augment the existing archival ecosystem.
https://github.com/pelagios/peripleo