Authors: Martijn Kleppe, Otte Marco
Category: Paper:Short Paper
Keywords: media studies, online news, web tracking, multi method, automated content analyses
Tracking Online User Behaviour With A Multimethod Research Design
Understanding users’ online behaviour is of growing interest to academic researchers in a variety of fields. Traditionally, in the marketing domain commercial research companies map consumer behaviour to understand when and where customers decide to buy products. For this purpose, web metrics of individual websites serve as detailed source of information on when, how and at which section a user enters a website. Recently this type of data is also being used by cultural heritage institutes to understand the interest of their visitors (De Haan and Adolfsen, 2008), to track where their digital content is being reused (Navarrete Hernández, 2014) or to understand the query’s users perform in search systems by analysing the log files (Batista and Silva, 2002; Huurnink, 2010). In this type of research, the website is the central research object providing traces that Menchen-Trevino (2013) calls ‘Horizontal Data sets’. These contain data that are ‘organized around a specific type of trace, for example search terms, web browsing log files, tweets, hashtags, likes or friend and follower ties’ (Menchen-Trevino, 2013: 331). An advantage of using this type of data is that they are not obtrusive to the respondents since they are created automatically as users are surfing the web. However, this also leads to an ethical disadvantage since users are not aware that their online behaviour is being examined, nor could they give their consent to have their data being analysed. While Horizontal Data Sets are organized around one type of trace, Vertical Data Sets are organized around research participants that deliberately ‘give permission for researchers to collect their digital traces’ (Menchen-Trevino, 2013: 331).
Since mid-1990s, commercial research agencies have started to collect these types of vertical data by building tools and panels of respondents whose online behaviour is monitored 24/7 to provide data on usage across media and purchase behaviour (Coffey, 2001; Napoli, 2010; Taneja and Mamoria, 2012). Similar to television viewing rates, these lists are mainly created to gain more insight in the background of website visitors in order to provide potential advertisers with information on how to reach their online target audience in the best possible manner. Obviously these commercial research data contain very rich information, also for academics who are interested in collecting real-world Web use data. However, apart from lists of the most popular domains that are published as open data by companies such as Alexa and Similarweb 1, data containing information about visits to each individual page and information about the background of the panel is not available. Main arguments of commercial agencies to not collaborate with scholars is to ensure the confidentiality of their respondents’ identity and to prevent scholars to gain insight into the techniques applied by the companies.
Nevertheless, researchers in a variety of disciplines are interested in tracking online behaviour in a real-world situation. Especially in the communications science realm, scholars experimented with several techniques of tracking people’s online behaviour (Ebersole, 2000; Tewksbury, 2003; Findahl et al., 2013; Findahl, 2009; Munson et al., 2013; Damme et al., 2015; Menchen-Trevino and Karr, 2012). Striking about these pioneering monitoring studies is its multi-method approach. By default each does not only monitor web use but also compares its outcome with either survey, diary or interview data. By triangulating the results, these researchers try to overcome the critique on classic studies on media consumption that often deploy either surveys or diaries registering self-reported media behaviour (e.g. Van Cauwenberge, d’Haenens and Beentjes, 2010; Schrøder and Kobbernagel, 2010; Taneja et al., 2012; Reuters Institute for the Study of Journalism, 2015). These methods strongly rely on the memory of the participants while several scholars found respondents often overestimate their media use (Ebersole, 2000; Prior, 2009; Robinson, 1985). Furthermore, since filling in diaries and surveys on news consumption is very labour-intensive, its outcomes mainly focus on when media have been consumed or on which devices, while it remains unclear what has been consumed. One way to gain insight in the consumed news content is focus on metrics of individual news organisations (Batista and Silva, 2002; Boczkowski et al., 2011; Lee et al., 2012; Usher, 2013) or the most clicked items (e.g. Boczkowski et al., 2011; Karlsson and Clerwall, 2013; Lee et al., 2012; Nederlandse Nieuwsmonitor, 2013). However, given the focus of these studies on individual websites or most-clicked articles it remains unknown which genres of news websites constitute users’ 24/7 news menu. Do they e.g. visit news about sports mainly in the morning and news on politics mainly during the evening? Taneja at el. (2012) tried to overcome this problem by literally following 495 users throughout an entire day. However, even with this labour-intensive fieldwork it proved not to be possible to incorporate the genres of consumed news items.
Web monitoring tools such as the above mentioned examples, now offer a less labour-intensive and more precise way of registering digitally consumed news items. By deploying these techniques, we could overcome the knowledge gap of the 24/7 news consumption menu. Therefore, we created the Newstracker, a custom built system that collects web activities of specified and authenticated users, cleans the data by removing non-relevant data, extracts the associated content and stores this as a new dataset to be used for analysis. While most existing online tracking studies mainly report the visited websites, our set-up goes two steps further. We did not only monitor the website titles but also the actual visited URLs and crawled all textual and visual contents of the visited websites. Since one of the problems when monitoring a person’s online behaviour is the magnitude of the data that is being collected (Batista and Silva, 2002; Manovich, 2012; Vicente-Marino, 2013: 43), we deployed automated content analyses techniques (Atteveldt, 2008; et al., 2012) to detect the topics that are being discussed in the news items. This enabled us to calculate the topical online news consumption during the day.
In this paper we will describe the set-up of ‘The Newstracker’ in a study on the online news consumption of a group of young Dutch news users and its applicability for other types of Digital Humanities research such as user studies focussing on formulating requirements based on existing user behaviour. We will demonstrate the workflow of the Newstracker and how we designed the data collection and pre-processing phase (see figure 1).
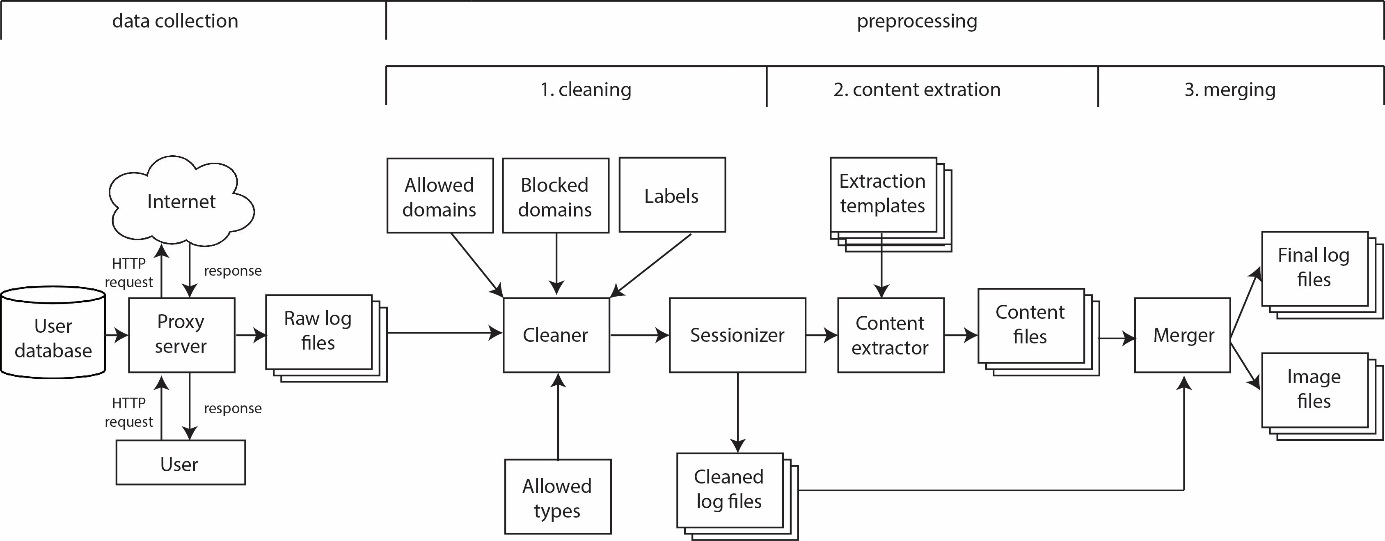
By reflecting on the technical, methodological and analytical challenges we encountered, we will illustrate the potential of online monitoring tools such as the Newstracker. We will end our paper with discussing its limitations by stressing the need for a multimethod study design when aiming not only to register but also to understand online user behaviour.
- Batista, P. and Silva, M. (2002). Mining Web Access Logs of an On-line Newspape. Proceedings of the 2nd International Conference on Adaptive Hypermedia and Adaptive Web Based Systems http://xldb.di.fc.ul.pt/xldb/publications/rpec02.pdf.
- Bhulai, S., Kampstra, P., Kooiman, L., Koole, G. and Kok, B. (2012). Trend visualization on Twitter: What’s hot and what’s not?. IARIA. (Data Analytics). Barcelona, pp. 43–48.
- Boczkowski, P. J., Mitchelstein, E. and Walter, M. (2011). Convergence Across Divergence: Understanding the Gap in the Online News Choices of Journalists and Consumers in Western Europe and Latin America. Communication Research, 38(3): 376–96 doi:10.1177/0093650210384989.
- Coffey, S. (2001). Internet Audience Measurement: A Practicioner’s View. Journal of Interactive Advertising, 1(2): 10–17.
- Damme, K. V., Courtois, C., Verbrugge, K. and Marez, L. D. (2015). What’s APPening to news? A mixed-method audience-centred study on mobile news consumption. Mobile Media & Communication, 3(2): 196–213 doi:10.1177/2050157914557691.
- De Haan, J. and Adolfsen, A. (2008). De Virtuele Cultuurbezoeker. Den Haag: Sociaal en Cultureel Planbureau http://www.scp.nl/dsresource?objectid=19697&.
- Ebersole, S. (2000). Uses and Gratifications of the Web among Students. Journal of Computer-Mediated Communication, 6(1): 0–0 doi:10.1111/j.1083-6101.2000.tb00111.x.
- Findahl, O. (2009). The Swedes and the Internet 2009. Gävle: World Internet Institute.
- Findahl, O., Lagerstedt, C. and Aurelius, A. (2013). Triangulation as a way to validate and deepen the knowledge about user behavior. A comparison between questionnaires, diaries and traffic measurement. Audience Research Methodologies: Between Innovation and Consolidation. New York, pp. 54–69.
- Huurnink, B. (2010). Search in Audiovisual Boradcast Archives Amsterdam: University of Amsterdam http://dare.uva.nl/document/2/83234.
- Karlsson, M. and Clerwall, C. (2013). Negotiating Professional News Judgment and “Clicks”. Nordicom Review, 34(2): 65–76 doi:10.2478/nor-2013-0054.
- Kleinneijenhuis, J. and Atteveldt, W. van (2006). Geautomatiseerde inhoudsanalyse, met de berichtgeving over het EU-referendum als voorbeeld. Inhoudsanalyse: Theorie En Praktijk. Kluwer, pp. 227–50.
- Lee, A. M., Lewis, S. C. and Powers, M. (2012). Audience Clicks and News Placement: A Study of Time-Lagged Influence in Online Journalism. Communication Research: 0093650212467031 doi:10.1177/0093650212467031.
- Manovich, L. (2012). How to Follow Software Users? http://lab.softwarestudies.com/2012/04/new-article-lev-manovich-how-to-follow.html (accessed 28 January 2014).
- Menchen-Trevino, E. (2013). Collecting vertical trace data: Big possibilities and big challenges for multi-method research. Policy & Internet, 5(3): 328–39 doi:10.1002/1944-2866.POI336.
- Menchen-Trevino, E. Tracing our every move: Big data and multi-method research The Policy and Internet Blog http://blogs.oii.ox.ac.uk/policy/tracing-our-every-move-big-data-and-multi-method-research/ (accessed 30 April 2015).
- Menchen-Trevino, E. and Karr, C. (2012). Researching Real-World Web Use with Roxy: Collecting Observational Web Data with Informed Consent. Journal of Information Technology & Politics, 9(3): 254–68 doi:10.1080/19331681.2012.664966.
- Munson, S. A., Lee, S. Y. and Resnick, P. (2013). Encouraging Reading of Diverse Political Viewpoints with a Browser Widget. Seventh International AAAI Conference on Weblogs and Social Media http://www.aaai.org/ocs/index.php/ICWSM/ICWSM13/paper/view/6119 (accessed 25 September 2015).
- Napoli, P. M. (2010). Audience Evolution: New Technologies and the Transformation of Media Audiences. New York: Columbia University Press http://cup.columbia.edu/book/audience-evolution/9780231150347.
- Navarrete Hernández, T. (2014). A history of digitization: Dutch museums Amsterdam: University of Amsterdam http://dare.uva.nl/record/1/433221 (accessed 25 September 2015).
- Nederlandse Nieuwsmonitor (2013). Seksmoord Op Horrorvakantie: De Invloed van Bezoekersgedrag Op Krantenwebsites Op de Nieuwsselectie van Dagbladen En Hun Websites. Amsterdam: Nederlandse Nieuwsmonitor http://www.nieuwsmonitor.net/d/244/Seksmoord_op_Horrorvakantie_pdf.
- Prior, M. (2009). The Immensely Inflated News Audience: Assessing Bias in Self-Reported News Exposure. Public Opinion Quarterly, 73(1): 130–43 doi:10.1093/poq/nfp002.
- Reuters Institute for the Study of Journalism (2015). Digital News Report 2015. Oxford http://www.digitalnewsreport.org/.
- Robinson, J. P. (1985). The validity and reliability of diaries versus alternative time use measures. Time, Goods, and Well-Being.
- Schrøder, K. C. and Kobbernagel, C. (2010). Towards a typology of cross-media news consumption: a qualitative-quantitative synthesis. Northern Lights: Film and Media Studies Yearbook, 8(1): 115–37 doi:10.1386/nl.8.115_1.
- Taneja, H. and Mamoria, U. (2012). Measuring Media Use Across Platforms: Evolving Audience Information Systems. International Journal on Media Management, 14(2): 121–40 doi:10.1080/14241277.2011.648468.
- Taneja, H., Webster, J. G., Malthouse, E. C. and Ksiazek, T. B. (2012). Media consumption across platforms: Identifying user-defined repertoires. New Media & Society, 14(6): 951–68 doi:10.1177/1461444811436146.
- Tewksbury, D. (2003). What Do Americans Really Want to Know? Tracking the Behavior of News Readers on the Internet. Journal of Communication, 53(4): 694–710 doi:10.1111/j.1460-2466.2003.tb02918.x.
- Usher, N. (2013). Al Jazeera English Online. Understanding Web metrics and news production when a quantified audience is not a commodified audience. Digital Journalism, 1(3): 335–51 doi:10.1080/21670811.2013.801690.
- Van Cauwenberge, A., Haenens, L. S. J. d’ and Beentjes, J. W. J. (2010). Emerging consumption patterns among young people of traditional and internet news platforms in the Low Countries. Observatorio, 4(3): 335–52.
- Vicente-Marino, M. (2013). Audience research methods. Facing the challenges of transforming audiences. Audience Research Methodologies: Between Innovation and Consolidation. New York, pp. 37–53.