Authors: Marianne REBOUL, Yuri BIZZONI
Category: Paper:Long Paper
Keywords: visualisation, translation, alignment, comparative studies, semantics
Projet Odysseus, Outil d’Etudes Comparatives Du Traductologue
1. Introduction
Le programme Projet Odysseus permet de voir immédiatement des différences et similitudes entre diverses traductions de l’ Odyssée d’Homère. Nous appliquons ce programme à un corpus français d’une centaine de traductions françaises allant de 1584 à 1934, afin de déceler les évolutions diachroniques dans les pratiques traductives. Nous constituons un corpus italien similaire, et avons aussi effectué des essais sur des traductions espagnoles, anglaises et allemandes de l’ Odyssée. Le protocole est applicable à tout corpus de traductions (Callison-Burch, 2008).
Notre programme permet donc de comparer un nombre indéfini de traductions d’un même texte source, sans dépendre des particularités linguistiques de chacune des langues cible.
2. Preprocessing : l’alignement
Pour comparer les différentes traductions entre elles, nous déterminons leurs similarités sémantiques et associons le texte source avec chaque texte cible. Nous établissons des points d’ancrage en grec et en français, qui permettent de découper les textes en séquences ayant potentiellement le même sens (Feng et Manmath, 2006) : les noms propres. Ils présentent deux avantages: ils peuvent être de très basse fréquence et sont majoritairement traduits par l’ensemble des traducteurs. Le texte grec pivot comprend toutes les leçons éditoriales établies à ce jour, afin d’assurer un alignement optimal tant avec les traductions anciennes que modernes. Le texte source pivot est découpé en séquences fixes : le programme découpe une nouvelle séquence dont le premier mot est le nom propre. Nous obtenons une série fixe de séquences. Nous appliquons le même processus aux textes cibles. Sont ainsi déterminés un ensemble de séquences sources et un ensemble de séquences cibles de nombre inégal.
Le programme aligne les séquences cibles aux séquences sources grâce à l’algorithme de Needleman-Wunsch (Needleman et Wunsch, 19 70). Il remplit une matrice de scores de similarité en comparant chaque séquence source avec chaque séquence cible. Un dictionnaire de noms propres augmente ou diminue le score. Un transformateur phonétique, transcrivant le grec en alphabet latin, augmente le score si le nom source phonétique se trouve dans la séquence cible. Le score tient compte la différence de longueur entre la source et la cible. Nous établissons dictionnaire de fréquence : si le nom pivot est à fréquence équivalente entre la source et la cible, le score augmente. Lorsque la matrice de scores est remplie, l’algorithme établit le chemin le plus probable depuis les deux dernières séquences source et cible jusqu’aux deux premières (Fig.1).
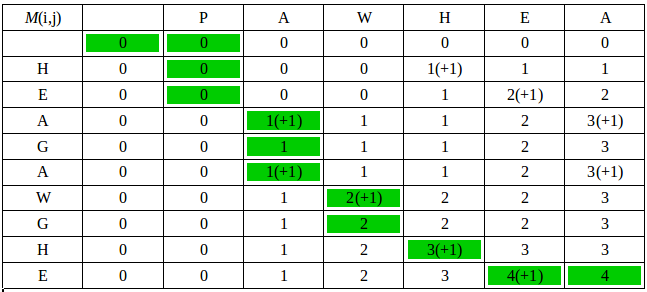
Nous constituons ensuite un dictionnaire basé sur la distribution sémantique des mots. Chaque mot est caractérisé par un vecteur de cooccurrence : sur l’ensemble des séquences, lorsque un mot apparaît dans une fenêtre constituée d’une séquence source et de sa séquence cible, la valeur du vecteur à l’indice de la fenêtre augmente. Statistiquement, des mots à usage similaire se trouvent à la fois dans les séquences sources et cibles aux mêmes indices. La similarité des vecteurs est établie avec la similarité cosinus ( Ye, 2011). Si un mot source obtient un vecteur similaire à celui d’un mot cible, la source-clé et la cible-valeur sont ajoutés au dictionnaire. Un second alignement est produit, tenant compte des scores obtenus grâce au dictionnaire de distribution. Lorsque nous effectuons plusieurs alignements en même temps, nous fusionnons les dictionnaires. Chaque séquence source comporte alors un identifiant unique auquel un identifiant cible est associé.
3. Classes comparatives
Nous pouvons comparer chacune des traductions alignées au texte source pivot, dans une interface faisant figurer autant de traductions que l’utilisateur le souhaite.
Lorsque des vides sont laissés par l’algorithme, deux interprétations sont possibles : le traducteur est extrêmement loin du texte source, ou il ne traduit pas le texte source. Dans les deux cas, cela nous renseigne sur ses pratiques traductives.
Nous comparons ensuite statistiquement les séquences alignées. Pour chaque séquence dans l’ensemble du corpus, nous déterminons la fréquence de chaque mot. Nous pouvons voir le taux d’usage d’un mot pour chaque séquence. Il est ainsi possible de visualiser les hapax produits par chaque traducteur. Il est aussi possible de déceler si un traducteur se base sur la même source que les autres : si le nombre d’hapax sur une séquence se multiplie, le traducteur ajoute probablement une séquence par rapport à ses homologues. Nous identifions les étoffements et réductions : si le nombre de mots employé par un traducteur pour une séquence est largement inférieur ou supérieur au nombre médian de mots employés dans le corpus pour cette séquence, le traducteur étoffe ou réduit le texte source. Nous décelons enfin un littéralisme fréquentiel de chaque séquence par rapport à sa source (lorsque le nombre de mots grecs est équivalent au nombre de mots français pour une même séquence), ainsi qu’un littéralisme phonétique (lemme grec retranscrit phonétiquement proche d’un mot cible).
Nous nous appuyons sur les travaux d’Henri Meschonnic ( Meschonnic, 1997) et d’Antoine Berman (Berman, 1984) pour définir des critères de comparaison entre la source et les cibles. Nous déterminons d’abord s’il y a, entre les deux, un allongement ou un appauvrissement quantitatif, en définissant une fenêtre de mots au-delà ou en deçà de laquelle nous considérons que la différence dans le nombre de mots est signifiante. Nous visualisons la tendance à la « rationalisation » : nous repérons, en comparant les patrons syntaxiques, l’inversion de la linéarisation des arborescences syntaxiques. Nous visualisons enfin la « destruction des rythmes », en recherchant la similarité entre les patrons de ponctuation ou les patrons de syntaxe profonde (juxtaposition, coordination, subordination) entre la source et la cible.
Pour comparer les traductions entre elles, l’utilisateur peut considérer dans l’étude statistique soit les traductions à l’écran, soit l’ensemble du corpus.
Nous intégrons un graphique permettant de visualiser les tendances décrites des auteurs dans la diachronie. Si un auteur a une forte tendance à l’emploi d’hapax, et que cette tendance se poursuit chez ses successeurs, cela est immédiatement visible.
4. Cas d’étude
Voici deux exemples: une utilisation unilingue dans l’interface de comparaison automatique, et une utilisation multilingue avec les résultats d’un dictionnaire de distribution. Le premier exemple est basé sur le chant I de vingt traductions françaises, de 1584 à 1935.


Dans la Fig.3, la première version est de Médéric Dufour et Jeanne Raison (Dufour et Raison, 1935), la deuxième celle d’Eugène Bareste (Bareste, 1842), la troisième celle de Victor Bérard (Bérard, >1924). Les termes en vert sont utilisés pour chaque tronçon par une grande majorité de traducteurs, ceux en orange sont fréquents, et ceux en rouge sont des hapax (utilisés une seule fois dans cette séquence par un traducteur). Le programme permet de visualiser ces captures sur une grande échelle, avec autant de traducteurs que nécessaire. En comparant le « chunk 131 » de Victor Bérard, par exemple, avec l’ensemble des « chunk 131 » du corpus, nous distinguons, toute proportion gardée, une tendance de Bérard à se démarquer de ses prédécesseurs par emploi de termes rares, phonétiquement ou syntaxiquement proches du grec.

Dans la Fig.4 Dufour et Raison (premier texte) optent pour un terme rarement associé aux yeux d’Athéna (« ballants »), produisant un hypallage, tandis que les autres termes sont consensuels. Bareste privilégie les présents d’hypotypose et de juxtaposition temporelle. Certaines expressions homériques sont rendues unanimement par les traducteurs, comme « ὕπνος ἡδύς », « le doux sommeil ».



Les Fig.5, Fig. 6 et Fig.7 sont des traductions d’une portion de texte qui tend à se traduire selon le même mode au XIXe siècle. Dans plus de vingt textes, pour l’expression « καὶ κεν τοῦτʼ ἐθέλοιμι Διός γε διδόντος ἀρέσθαι », les traducteurs imitent la ponctuation du texte source (italique), mais aussi sa syntaxe (couleur bleue).
Le programme permet de déceler les portions de texte omises par le traducteur. Par exemple, Achille de La Valterie disait traduire l’ Odyssée sans connaître le grec (à partir du latin) : sa traduction s’aligne, mais le nombre d’hapax et d’omissions est sans précédent (Fig.8).
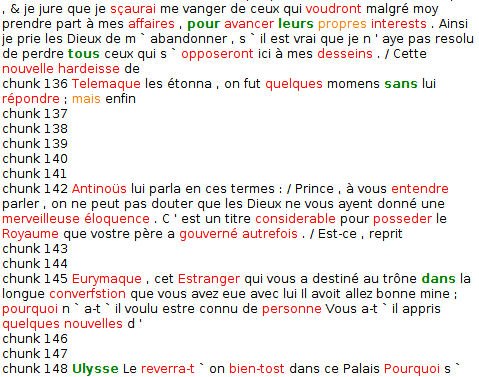
Dans cet extrait, les blancs laissés par le programme ne sont pas des erreurs d’alignement, mais des omissions du traducteur, qui choisit de ne pas traduire.

Pour une utilisation multilingue, nous pouvons mener les mêmes expériences que pour un corpus unilingue. Nous pouvons aussi visualiser le dictionnaire de distribution, qui permet de voir comment chaque langue traduit, pour l’ensemble de son corpus, chaque notion. En Fig.9, nous comparons comment chaque langue traduit « Ὀδυσσεύς » dans le chant I et quels en sont les termes sémantiquement proches, tous auteurs confondus. Nous pouvons ne choisir que certains auteurs, afin par exemple de voir l’évolution de l’emploi d’un terme en France et en Italie pour une période définie. Nous pouvons générer des dictionnaires multilingues dont le degré de sévérité dans la sélection est modifiable.
5. Conclusion
Ce programme a pour but de proposer aux comparatistes une façon simple de repérer les grandes tendances et les phénomènes notables d’une traduction à une autre, indépendamment de la langue du traducteur. Mais le programme ouvre aussi la voie à la création d’autres outils pour l’étude de corpus multilingues (dictionnaires, détection automatique de paraphrases interlinguistiques), à de nombreuses analyses statistiques (fréquence des mots, « type / token ratio », etc.) qui représenteront un apport substantiel à l’étude de l’Histoire des traductions.
- Bareste, E. (1842). Odyssée: traduction nouvelle, (Lavigne).
- Bérard, V. (1924). L’Odyssée. Texte établi et trad. par Victor Bérard, (Les Belles Lettres).
- Berman, A. (1984). L'épreuve de l'étranger: Culture et traduction dans l'Allemagne romantique Vol. 226: 67-81, Gallimard.
- Berman, A. (1995) Pour une critique des traductions: John Donne. Paris, Éditions Gallimard, "Bibliothèque des idées".
- Bignan, A. (1853). L’Odyssée traduite en vers français, (Hachette).
- Callison-Burch, C. (2008). Paraphrasing and translation (Doctoral dissertation, University of Edinburgh).
- Dufour, M., Raison, J. (1941). Homère. L’Odyssée: traduction de Médéric Dufour et Jeanne Raison, illustrée de vingt-quatre compositions en couleurs par Benito... ,(Le Vasseur).
- Feng, S. and Manmatha, R. (2006, June). A hierarchical, HMM-based automatic evaluation of OCR accuracy for a digital library of books. In Digital Libraries, 2006. JCDL'06. Proceedings of the 6th ACM/IEEE-CS Joint Conference on , IEEE, pp. 109-18
- Froment, J. B. F. (1883). Odyssée d’Homère, Vol. 2: in-8e (Plon et Cie)
- La Valterie, A. (1681). L’ Odyssée, (Barbin)
- Meschonnic, H. (1999). Poétique du traduire. Paris: Verdier.
- Ye, J. (2011). Cosine similarity measures for intuitionistic fuzzy sets and their applications. Mathematical and Computer Modelling, 53(1), 91-97.