Authors: Peter Robinson, Barbara Bordalejo
Category: Paper:Poster
Keywords: collaboration, scholarly editing, crowd-sourcing
Textual Communities
This poster presents the public version of the Textual Communities scholarly editing environment, describing its underlying principles, its innovative structure, and its functionality. It updates the presentation of Textual Communities given as a poster at DH 2013 in Lincoln, Nebraska.
Study of literary works that exist in many different forms is one of the most important and difficult tasks in the humanities. The number of forms a work may have —eighty-four fifteenth-century manuscripts and printed texts of Chaucer’s Canterbury Tales, more than eight hundred manuscripts of Dante’s Commedia, and five thousand manuscripts of the Greek New Testament — is both testimony to their significance and a challenge to scholars. In order to understand these texts and how they relate, we have to discover as much as we can of how they came to be written and disseminated. Only then can we seek to establish how they might best be read and prepare texts (in the form of scholarly editions) for scholars to use. The work of building archives of primary materials for this work is daunting and prohibitive in the old lone scholar method. Many large editing projects have opted for a team approach, exploring the possibilities of crowd-sourcing for processing large amounts of textual data. The challenge is to coordinate this work in a way that produces high-quality, useful results. The Textual Communities workspace enables every aspect of the scholarly process: defining, transcribing, and linking textual materials for a digital archive or edition; collating the witnesses and adjusting the collation for optimal scholarly use; analyzing the results of the collation to create an understanding of the relations among the manuscripts; and for marshaling and managing a community of participants with an array of community building tools.
There are many editorial tools under development and a few that are already functional. There are two defining features that make Textual Communities different from the rest: its integrated participant and document management systems, and its mapping of fundamental document-entity structure. These features correspond to two underlying principles: that the work of amassing large corpora of textual materials is best accomplished by a well-managed community of interested participants from within, but also potentially from outside the academy; and that for the resulting materials to be useful, their relationships must be clearly articulated.
As its name suggests, Textual Communities is designed for gathering and organizing multiple participants around a common editorial project. It supports a wide range of relational structures, from a carefully crafted team to ad hoc community built on crowd-sourcing. Crucially, it enables definition of roles in the project with varying degrees of access to project materials and of authority to do the work of processing these materials, and oversight over other participants. It is also built on an ontology of text, document and communicative act to identify and relate the produced transcriptions (“texts”), the exemplars they derived from (“documents,” usually in the form of a digital image of a particular witness), and the intellectual construct they instantiate (the communicative act or “work”, or our preferred term, “entity”). Thus anyone interested in John Donne’s poem “The Good Morrow” will find various “texts” (transcriptions) of this work as found in the extant “documents” (the poem as it is found in each of the manuscripts and printed books that contain it).
Textual Communities itself enables uploading of digital images of primary and linkage of these images with a transcription space. The user supplies information for each document, which defines the text that is to be transcribed and its relationship to the source document and entity. The user also defines the structure of the document, which is rendered behind the visible transcription in TEI conformant XML. The transcription area, which is automatically linked to the source image, can also support any XML markup that is desired or required for intelligent transcription of the source document. The collation area (based on CollateX) offers full regularization and editing facilities, to enable creation of optimal collations for scholarly use.
This open-source tool is available free of charge for use and adaptation by anyone anywhere. Development of this tool is funded by a generous grant from the Canadian Foundation for Innovation with the support of the Digital Research Centre at the University of Saskatchewan.
This poster will be accompanied by a live demonstration of the editorial workspace.
Figure 1: opening screen of Textual Communities
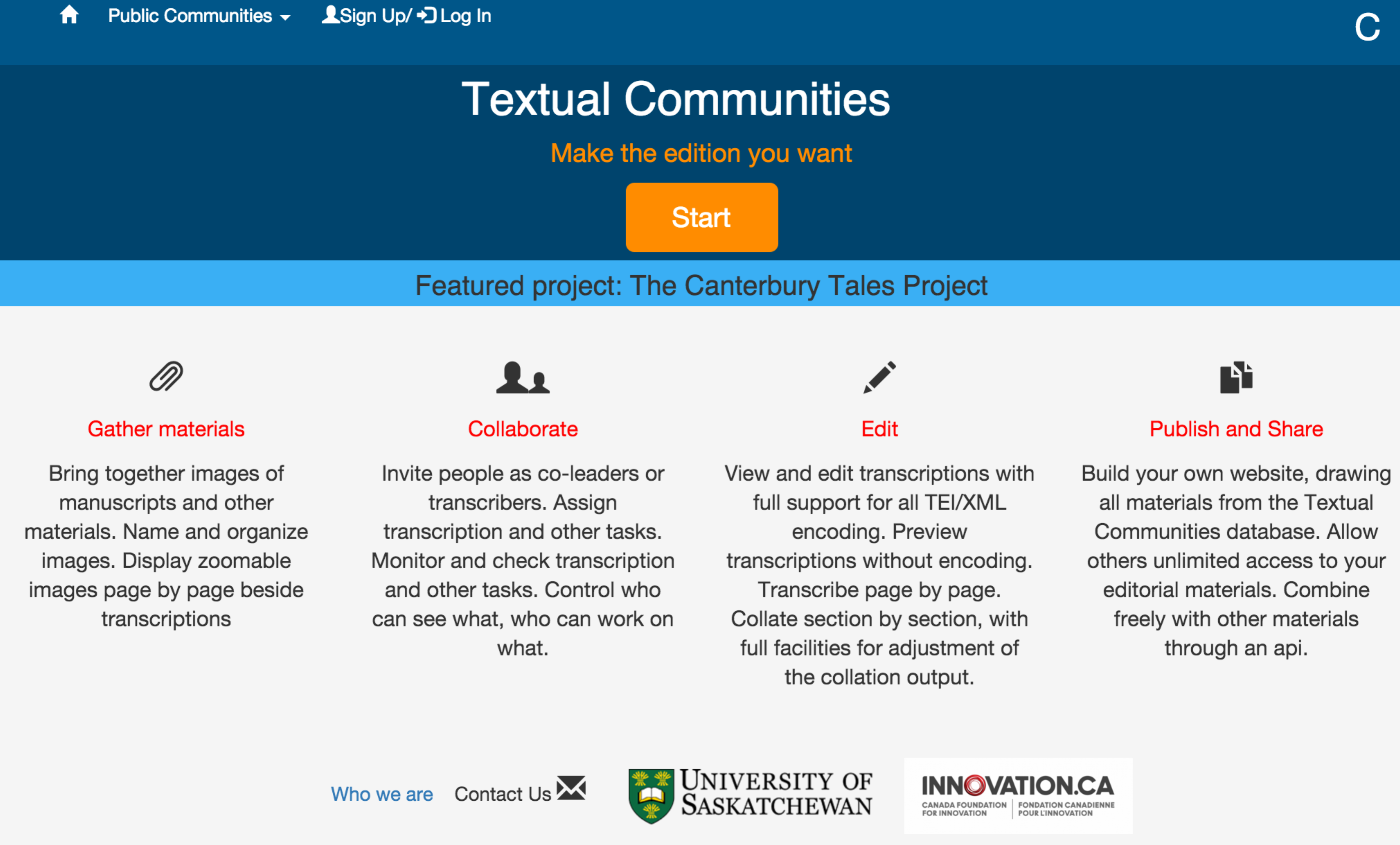
Figure 2: transcription interface