Authors: Stefan Jänicke, David Joseph Wrisley
Category: Paper:Long Paper
Keywords: visualization, text alignment, textual variance, medieval French
Visualizing Mouvance: Towards an Alignment of Medieval Vernacular Text Traditions
Poetry in the Middle Ages changed as it was recopied, recited and passed along. Mouvance is a term used by late Swiss medievalist Paul Zumthor to designate the high degree of instability in medieval text traditions. Zumthor qualifies this instability as an “interplay between variant readings and reworkings,” balancing both the textual, literary elements of written works with oral, performative ones (Zumthor, 1992; p.44). Twentieth-century text editing came to grips with this instability in large text traditions in different ways. For complex text traditions with a high degree of variance in medieval French, editors sometimes compiled one edition containing all the witnesses in successive chapters, as in the cases of La vie de sainte Marie l’Egyptienne (Dembowski, 1977) and L’Evangile de Nicodème (Ford, 1973) or they arranged them in a synoptic-style parallel edition as in the case of the fabliaux (Rychner, 1960). The alignment of such synoptic editions, although not discussed explicitly by the editors, was no doubt hand-ordered and its page layout was based on rough narrative equivalence of passages.
Cerquiglini has argued that, faced with such variance, the medievalist’s “analysis must be comparative, not archeological” (Cerquiglini, 1999; p.44). Such parallel print editions provide readers with a visual frame for comparative reading of variant texts, inviting exploration and giving insight into processes of textual change. There are a number of problems in text traditions with oral influence. There are not only different kinds of variance (single word/string variance, half-line or hemistich variance, transposition and reorganization of rhyming verse lines or interpolation of entirely new lines), but patterns of variance are also not uniform across a text, making the desired comparative visualization of texts difficult. Alignments can also mix and confuse kinds of variance. What are ways of visualizing textual variation in a digital environment? This is the question our paper intends to explore.
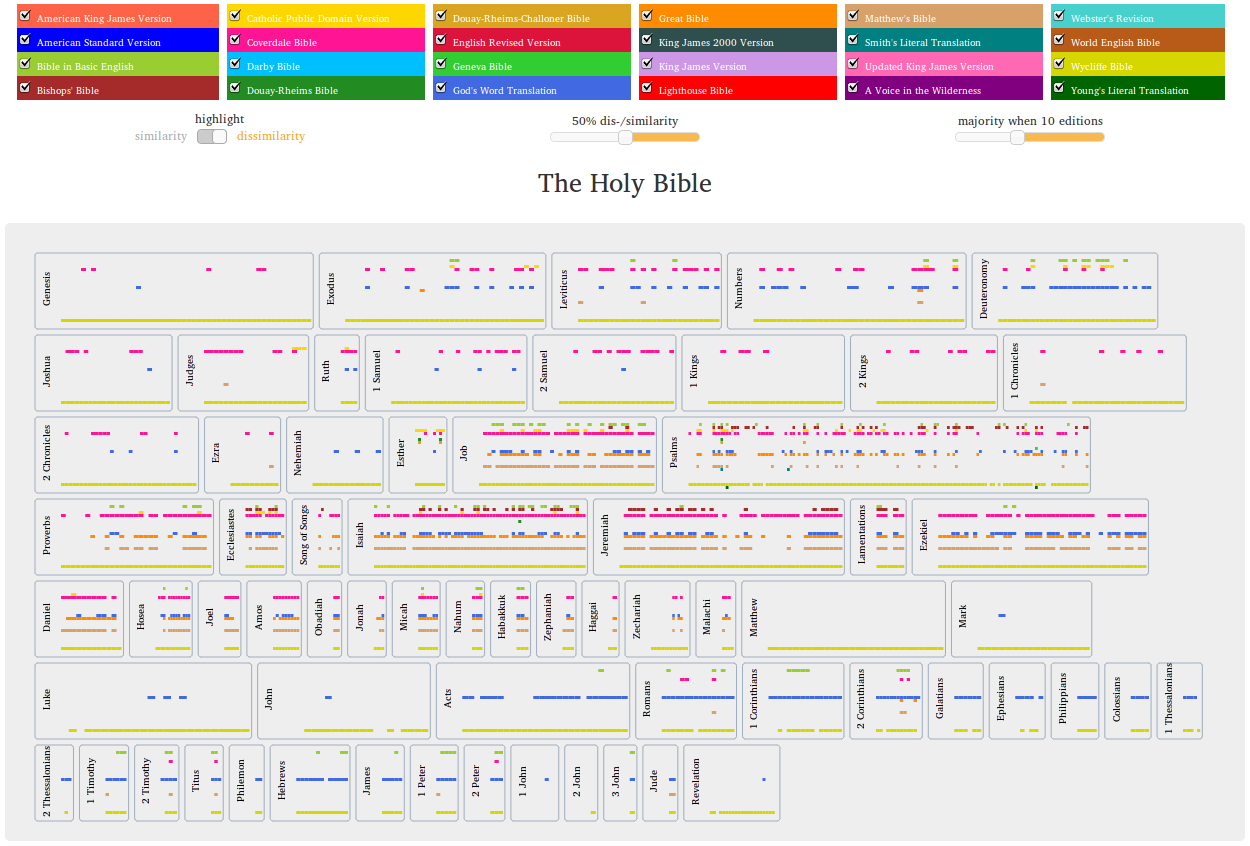
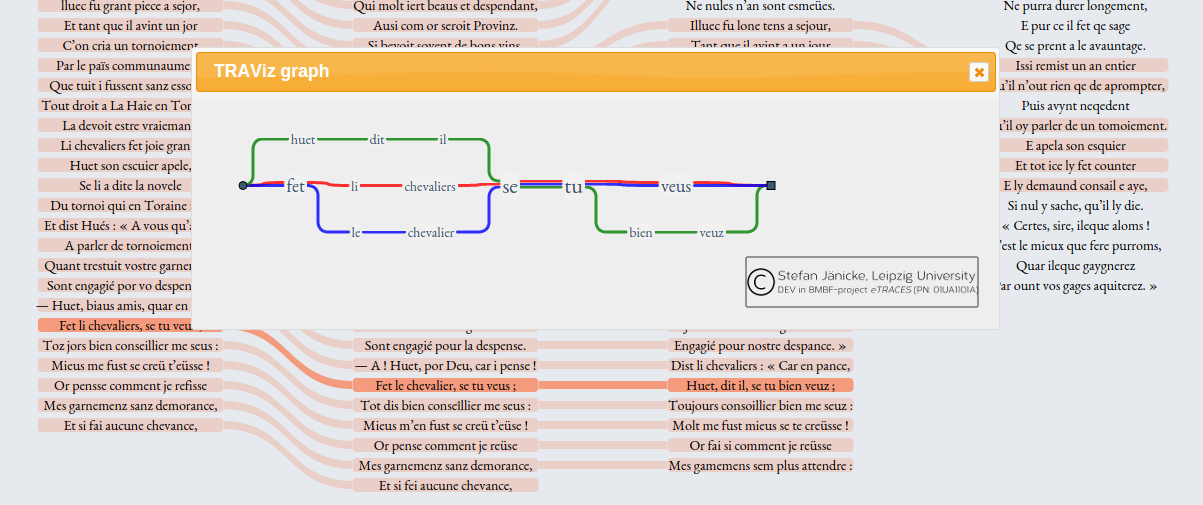
Visualization strategies for historical text reuse vary according to the scale of the phenomenon and the nature of the texts involved (Franzini et al., 2015). Sophisticated visualizations for alignment exist at the micro-level, that is, at the level of the word such as the graph visualizations of TRAViz (Jänicke et al., 2015). They facilitate comparative readings of word-level variance in manuscript witnesses or translations. The text in such alignments is fully legible. A clean example of this can be found in the TRAViz alignments of English translations of the Bible (Figure 1), a textual use case in which units and sub-units of text are already commonly agreed upon by tradition (e.g. book, chapter, verse). On the other hand, solutions exist for macro-level text reuse, such as fingerprinting techniques (Jänicke and Geßner, 2015), creating distant patterns of textual similarity without showing the text (Figure 2).

A critical discussion of the description and design of meso-level visualization of complex text traditions is missing. Not only are these text traditions large, but they are highly influenced by orality, that is, in Zumthor's words, they present a combination of textual and performative variance. Textual reworking at multiple scales (whole chunks of text, groups of lines, individual lines, sub-line strings) are challenges for both alignment and visualization. Our design attempts to translate the insights of Zumthor and Cerquiglini into an environment for visual exploration using two medieval text traditions: a tradition of short baudy tales known as the fabliaux , and in versions of the well-known epic the Chanson de Roland . These two traditions have been chosen for the kinds of complex variance they exhibit. Our paper focuses on so-called meso-level alignments that visualize patterns of textual variance higher than the word and verse line level, and stress both legibility and human interaction in visualizing patterns.
Existing methods for text alignment in digital environments, generally speaking, favor relatively stable texts with small variance. The Versioning Machine accepts texts encoded “according to TEI's Parallel Segmentation method” and “interprets the encoding, parsing out the text into its constituent parts” (Versioning Machine, 2015). The authors of the Versioning Machine offer a sample alignment of a medieval “Prophecy of Merlin” (Figure 3). The line-to-line alignment has been encoded by the textual scholar. Similar lines are visually connected using customary mouse behavior, however, variance within the line or across lines is not visualized.

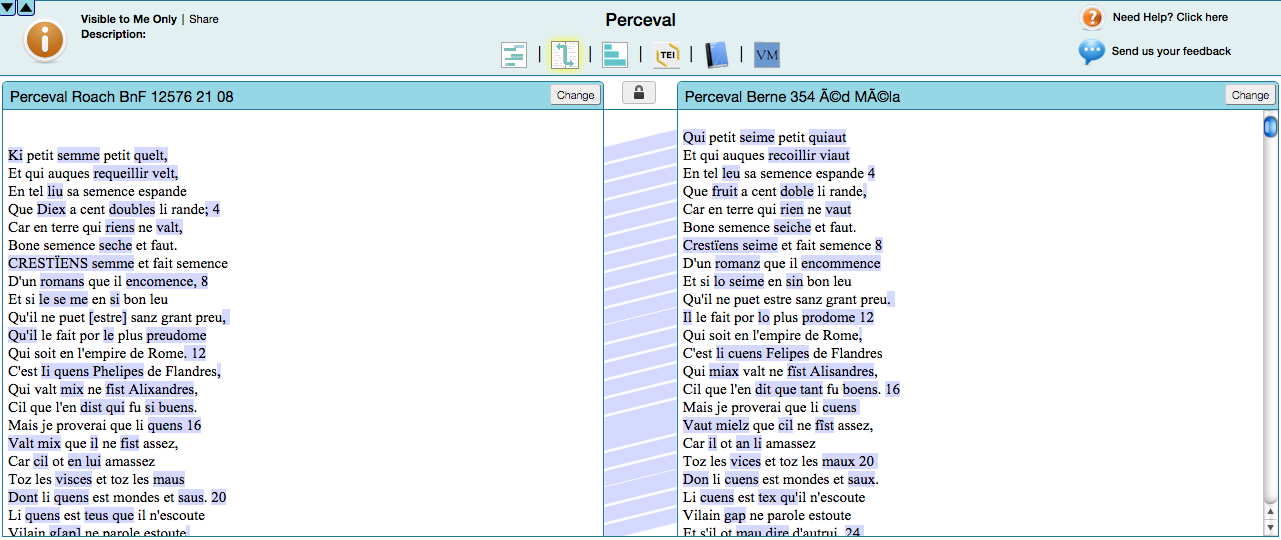
Another environment for the collation of raw text and visualization of textual differences is JuxtaCommons (Wheeles and Jensen, 2013). The example in Figure 4 uses two editions of Chretien de Troyes’ medieval romance Perceval , one based on BnF, ms. français 12576 (Roach, 1959) at left, and the other Bern, Burgerbibliothek ms. 354 (Méla, 1990) at right. There is basic alignment of the verse line and minor lexical or dialectal variance, and mouse over in JuxtaCommons allows basic comparative reading of word- and string-level variants. In their out-of-the-box implementation, both tools allow for easy comparison of two versions of the text, although the Versioning Machine has been implemented for larger comparison sets.
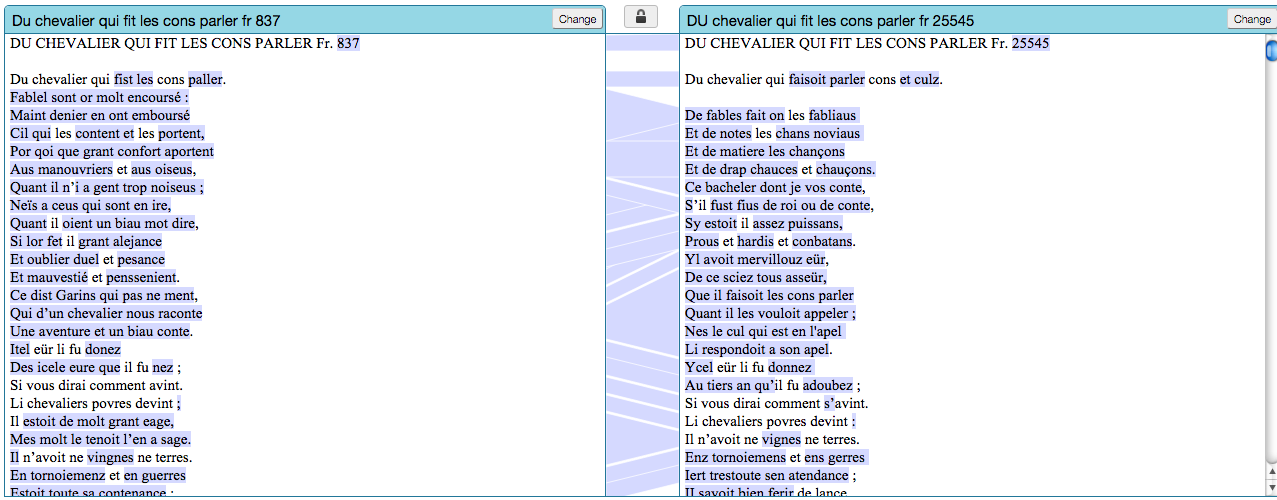
When complex text traditions containing more than just variant readings, but also interpolations, extra or missing lines or a significant amount of orthographic variance are collated automatically in JuxtaCommons, their results, however, are nearly illegible. Figure 5 shows two witnesses of the same old French fabliau ; the visual alignment, however, does an insufficient job at expressing the performative element of their mouvance .
Our design for a sufficient representation of variance in the fabliaux is shown in Figure 6. We use the intuitive quality of stream graphs (Byron et al., 2008) in order to support the analysis of aligned verses and to illustrate the transmission of one fabliau in four versions. The text editions are juxtaposed in columns in order to minimize edge crossings, in other words, we order the editions according to their similarity.

The visualization is available at http://informatik.uni-leipzig.de:8080/Fabliaux/ . Clicking on a specific verse line produces a TRAViz micro-view of the line-level variance (Jänicke et al., 2015), whereas the larger meso-view of this portion of the fabliau allows patterns between and across verse lines to be clearly ascertained. V ariance in this genre maintains prosody and avoids hypermeter; mouvance is characterized here by the interpolation of larger narrative multi-line fragments of text. The exception to this general rule is manuscript Harley 2253 in the column at far right where the narrative is reconstituted almost completely around sparse line re-use, illustrating what Rychner calls in the subtitle of his book “deteriorization” [dégradation] (Rychner, 1960). Mouvance occurs in multi-line “chunks,” visible in highly legible streams of text re-use. This provides much more insight into textual transformation than reading Rychner’s hand-aligned synoptic edition, with the streams here drawing our attention to patterns of re-used text. In his edition, blank spaces and horizontal lines in the page layout effect a more uncertain alignment.
Another example of what we are calling meso-level alignment is the visualization of one stanza from the Chanson de Roland tradition contained in six manuscripts. Figure 7 illustrates laisse 1 of the Lavergne fragment, absent from Oxford, Bodleian Library manuscript Digby, 23. An interactive version of the alignment is available at http://informatik.uni-leipzig.de:8080/roland/index2.html?ftsize=11 .

To indicate how often lines recur across the whole manuscript tradition, we use streams colored with varying saturation. Highly saturated colors indicate frequently repeated passages, whereas less saturated colors indicate less repeated ones. Such a feature allows for a “consensus” visualization of the tradition at this meso scale. It is easy to see the more complex, transpositional variance of lines in the Chanson de Roland . This compositional feature of French epic visualized here needs to be studied across the entire corpus of seven manuscripts and three fragments. It is perhaps on this point, however, that a principle of visualization clashes with the visual expectations of a medieval textual scholar. As in the above example, we ordered the editions to reduce the number of crossing streams and to maximize legibility. This is potentially at odds with readers who expect to see temporality of manuscript dating represented in the visualization. More thinking needs to be done about the visual semantics of such a large tradition. In such a case, a perfect order that produces less clutter might be hard to determine, and we will be required to extend our proposed design.
We began with the alignment of the fabliaux and Chanson de Roland since they are traditions where editors have indexed alignment manually, either using page layout or by numerical cross referencing of the stanzas . As the example shown in Figure 8 illustrates, lin es are not identical word for word, but rather our alignment has asserted basic diegetical equivalence.
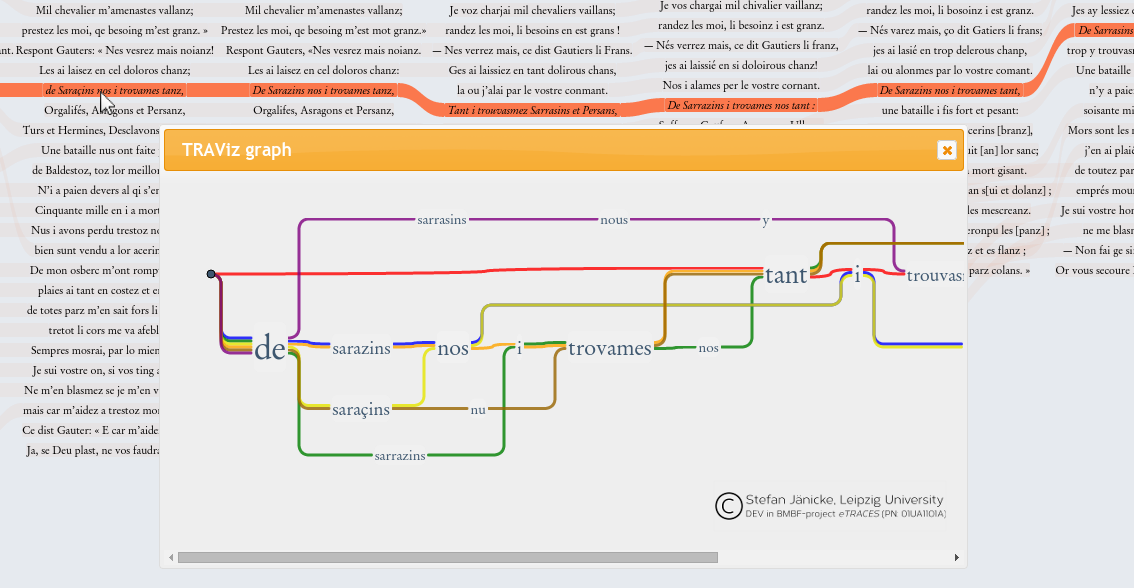
In the example portrayed in Figure 9, performative mouvance is reflected in the recombination of words in the line.
In developing our research on this topic, we intend to pursue more granular alignment using computational means, down to the line and perhaps the hemistich. Based on the Relative Edit Distance of strings (Jänicke et al., 2015), we aim to determine spelling variants and rhyme sets automatically. Combined with an n-gram analysis, we will support the discovery and alignment of similar text passages. Due to the high degree of orthographic variance of the medieval French language, a purely computational approach might lead to a high number of false positive alignments. Therefore, we will design a visual analytics system that includes the human in the alignment process in order to configure appropriate settings that maximize the alignment of re-used text passages. This visual analytics process includes the supervised training of a classifier that supplies the parameters steering the alignment. Iteratively, computationally aligned text fragments are scored by the textual scholar according to their relevance. After each scoring session, the alignment will be recomputed taking the scholar's justifications into account.
In contrast to the manual alignment illustrated in the visualizations above (Figures 6-9), such a semi-automated process will potentially yield a very different picture in particular with respect to the degree of difference the human allows in string matching and the presence of shared n-grams required to align certain text passages. A further opportunity of this generic visual analytics approach is its straightforward adaptability to editions in other languages than medieval French. With such a user-centered approach, alignment is not to be understood as a final product, but rather a process, for understanding variant text traditions, exploring their intricacies and supporting generation of hypotheses about textual behavior.
- Byron, L., and Wattenberg, M. (2008). Stacked graphs–geometry & aesthetics. In Visualization and Computer Graphics, IEEE Transactions. 14.6 (2008): 1245-1252.
- Cerquiglini, B. (1999). In Praise of the Variant: A Critical History of Philology . Baltimore/London: The Johns Hopkins Press.
- Dembowski, P. (1977). La vie de sainte Marie l’Egyptienne, versions en ancien et en moyen français . Geneva: Droz.
- Ford, A.E. (1973). L’Evangile de Nicodème: les versions courtes en ancien français et en prose . Geneva: Droz.
- Franzini, G., Franzini, E., Büchler, M. (2015). Historical Text Reuse: What Is It?. Available at: http://etrap.gcdh.de/?page_id=332 [accessed 3 March 2016].
- Jänicke, S. and Geßner, A. (2015). A Distant Reading Visualization for Variant Graphs. In Proceedings of the Digital Humanities 2015 .
- Jänicke, S., Geßner, A., Franzini, G., Terras, M., Mahony, S. and Scheuermann, G. (2015). TRAViz: A Visualization for Variant Graphs. In Digital Scholarship in the Humanities , 30(suppl.1): i83–i99. Available at: http://www.informatik.uni-leipzig.de/~stjaenicke/TRAViz.pdf [accessed 27 October 2015]
- Méla, C. (1990). Le Roman de Perceval. Édition du ms. 354 de Berne, traduction critique, présentation et notes . By Chrétien de Troyes. Paris, Librairie générale française.
- Moffat, M. (2014). The Châteauroux Version of the “Chanson de Roland”: A Fully Annotated Critical Text . Berlin/Boston: De Gruyter.
- Roach, W. (1959). Le roman de Perceval ou le Conte du Graal publié d'après le ms. fr. 12576 de la Bibliothèque nationale . By Chrétien de Troyes. Geneva, Droz.
- Rychner, J. (1960). Contribution à l’étude des fabliaux: variantes, remaniement, dégradations . Geneva: Droz.
- Versioning Machine. (2015). http://v-machine.org/samples/prophecy_of_merlin.html [accessed 27 October 2015]
- Wheeles, D. and Jensen, K. (2013). Juxta Commons. In Proceedings of the Digital Humanities 2013 .
- Zumthor, P. (1992). Toward a Medieval Poetics . Minneapolis: University of Minnesota Press.