Authors: Francesco Beretta
Category: Paper:Long Paper
Keywords: data modelling, digital history teaching, personal information system, semantic annotation of texts, data visualization and analysis
From Index Cards to a Digital Information System: Teaching Data Modeling to Master's Students in History
For the last five years I’ve taught a course on “computer science for historians” at University Lyon3 Jean Moulin. The course includes 20 hours in ten sessions and has attracted twenty to forty students each year. It addresses history students during the first semester of their master studies: they start at this stage with information collection in archival sources and bibliography, which they can later exploit to write their master's thesis. Thus, the aim is to provide them with methods and digital tools for modeling and storing information, and then for subjecting it to interrogation, visualization and analysis. This is a great challenge because many students still use paper for taking notes when they analyze historical sources and are not used to working with software that is not completely self-installing. Furthermore, students will receive from their tutors all kinds of research subjects, from Ancient to Modern history, and they often want to analyze quite complex information which one cannot store in a simple spreadsheet. For this reason, the pedagogical challenge is also a challenge for the digital humanist: how can the students be provided with a generic and flexible information system of ready use for their research but sophisticated enough to store any sort of data?
In this paper I will treat some theoretical and practical aspects of the digital information system I devised to cope with this problem, and will present some issues raised by recourse to the information system that concern both students and teacher. The manuscript of the course is publicly available on a dedicated website 1: anyone interested can download the tools I developed and test the methods proposed to the students, or employ them for their own teaching. As I teach in French the documentation, interfaces, etc. are written in this language. The information system I propose in the course combines the experience acquired in developing the symogih.org project 2, a collaborative platform for storing and sharing structured historical data, with the method of semantic annotation of texts adopted in our platform for digital editions 3 in accordance to the Text encoding initiative's guidelines (TEI). These data production practices, both as structured data and encoded texts, must be radically simplified to cope with the pedagogical need exposed above and this requires working on a high level of abstraction.
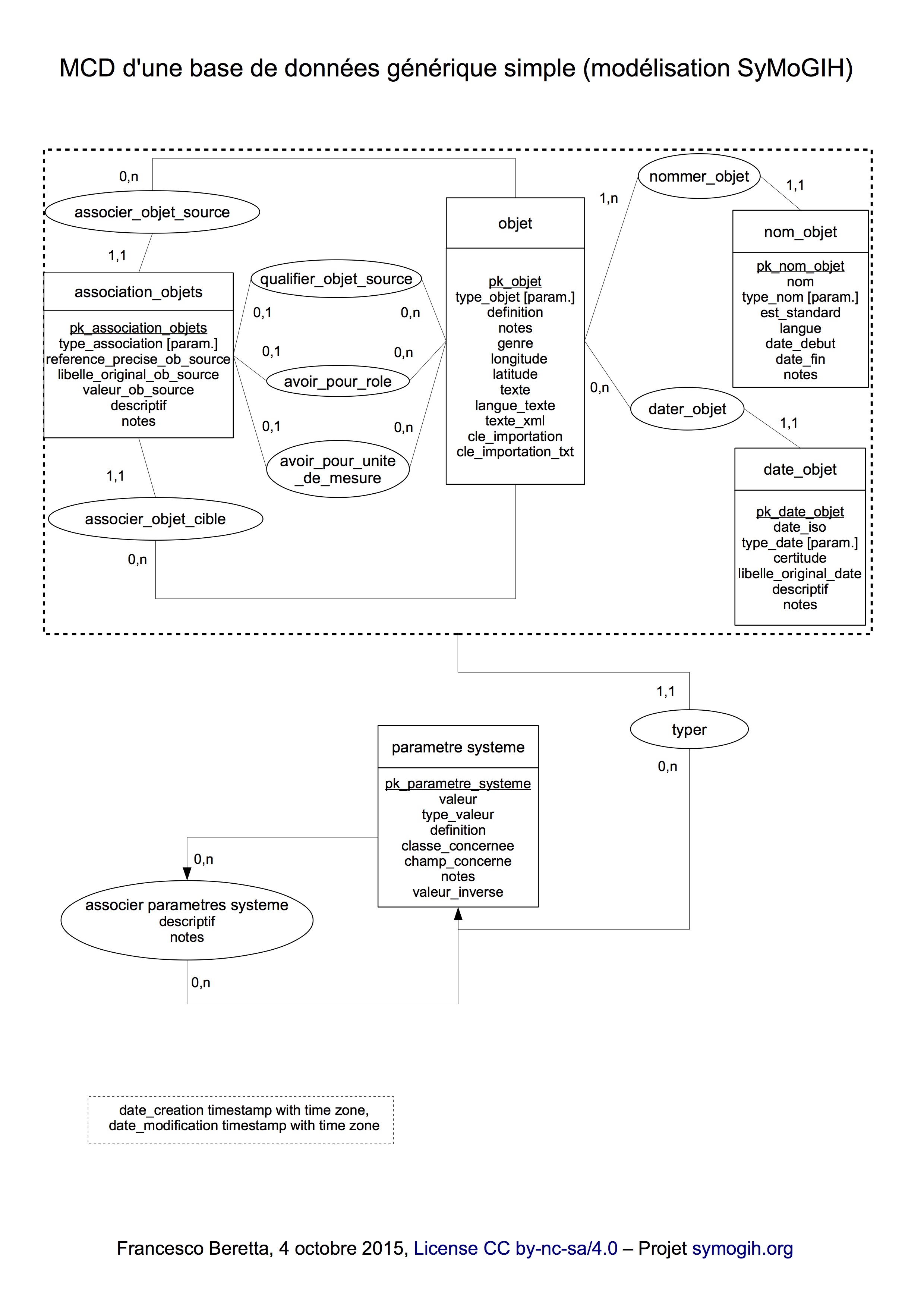
The first component of the information system provided to the students is a relational database designed using a generic data model 4. In the center of the model (Figure 1), the object class, having the same sense as the "Endurant" class in DOLCE 5, or the "Persistent Item (E77)" class in CIDOC-CRM 6, comprises individual actors, institutions, places, concepts, etc. about which students will be collecting information. The function of this class is to provide an identifier for each individual, in turn characterized by one or more names, a time span of existence, a type and an accurate textual definition. The database also allows treatment of some basic associations between objects defined in a class "system parameter" – a typical component of a generic data model – whose instances are predefined by the teacher. This simplifies the use of the database by students and guides them in their first steps of data production, but if needed parameters can be extended to other kinds of relationships. A simple PHP interface is added to facilitate data capture.
The database is implemented using PostgreSQL because this open-source database provides extended features in datatype treatment (namely XML) and comes along with a procedural language (PL/pgSQL) allowing data treatment in a SQL context without having to learn a different programming language 7. The teacher can thus write predefined functions to help the student prepare, transform and code the data before further treatment. A spatial extension is also available (PostGIS) which permits working with geo-referenced data if needed 8. PostgreSQL is therefore a kind of "Swiss Army knife" for historical data storage and treatment.
If the "Objects" ("Endurants" or "Persistent items") are identified in the database, where then is collected information about them? According to the symogih.org semantic data model 9, a "Knowledge Unit" is an atomized portion of information that expresses a relationship among objects situated in space and time, established on critical analysis of documents. The class "Knowledge Unit" is therefore equivalent to the "Temporal entity (E2)" class in CIDOC-CRM or "Perdurant" class in DOLCE: “An endurant lives in time by participating in some perdurant(s). For exemple, a person, which is an endurant, may participate in a discussion, which is a perdurant” 10.
In former years, "knowledge units" were also stored in the database, as the "objects" are presently 11. Pedagogical experience has shown that the degree of abstraction required for modeling information in form of structured data is generally too steep for training digital historians, although some students used this method with ease. The newly proposed information system comprises therefore a second component which consists in a text encoding method using some specific TEI tags and attributes. These allow semantic text encoding: "knowledge units" can be directly annotated into the text, thus marking up named entities with the database identifiers of the related objects and then encoding their properties and relationships in the text with specific tags and attributes 12.
But this method raises the question of the XML editor to adopt for text semantic encoding, meaning the addition of a further software component to the workflow of data production providing XML schema validation and also tools for querying the encoded text. XML text encoding is more suitable and I prefer it for PhD student and researcher training, but this demands a supplementary specific instruction that it impossible to provide in the limited master's course time. I therefore conceived a way of semantically tagging the text in a simple text editor or word processing program using curly brackets instead of angle brackets and replacing XML-attributes by predefined codes. This method is described on the course wiki that also furnishes instructions for using regular expressions for proper encoding 13. Regular expressions are then used in a PL/pgSQL script in the database to transform the curly brackets and their content into real XML tags and attributes: the encoded tag “{en2ai_10}Johannes Kepler{/en}” becomes “<en type=“ai” ref=“2” ana=“10”>Johannes Kepler</en>” (belonging to a course-specific namespace). This transformation allows storage of the encoded text in a PostgreSQL XML field and consequently benefit of the full power of the XPath and SQL queries, and programming capabilities of PL/pgSQL, to extract information from the texts.
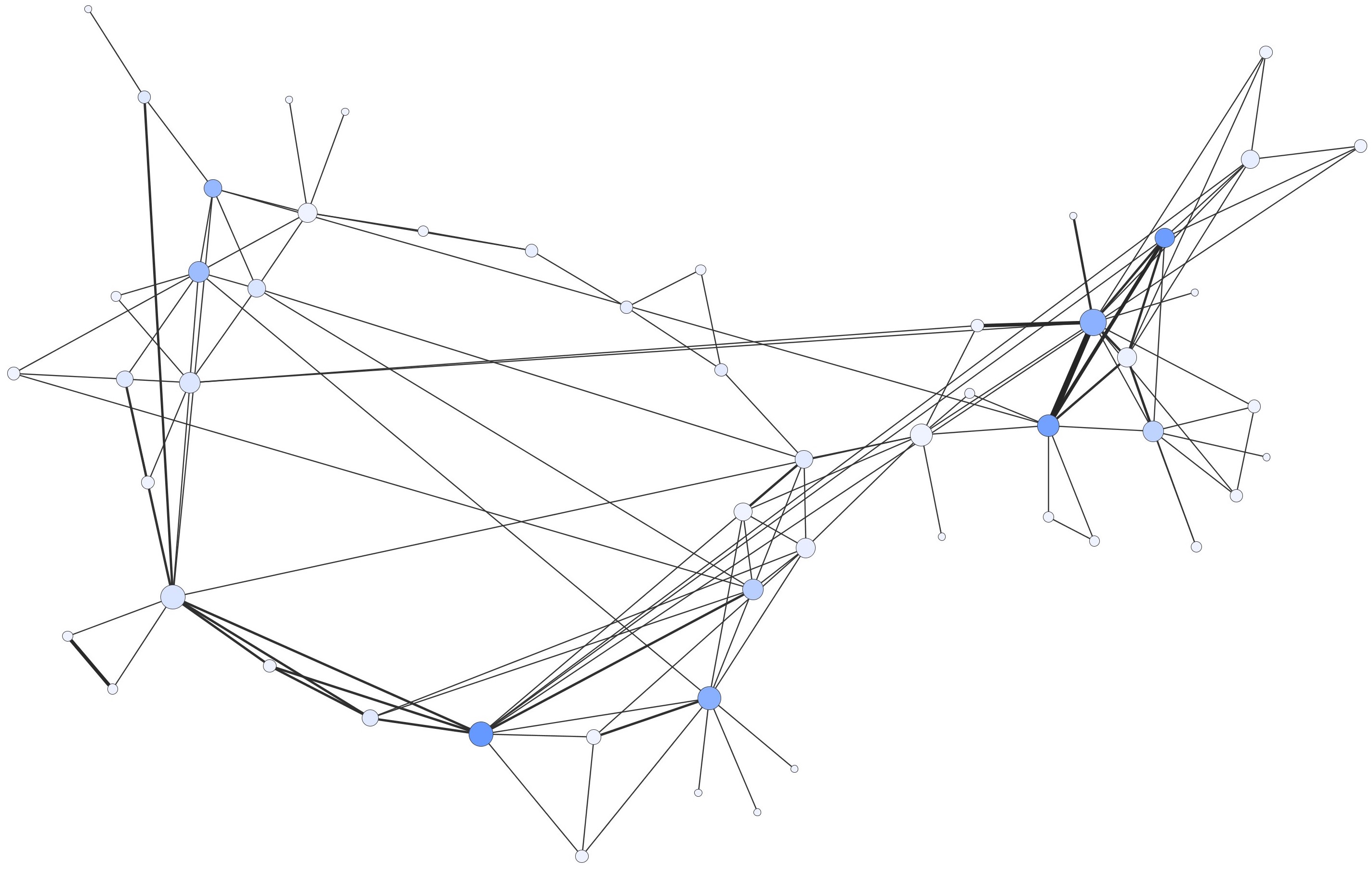
The workflow of data production and treatment ends with the phase of data analysis and visualization. For this purpose I adopted the R software that can be directly connected to a PostgreSQL database and provides many useful libraries. For instance, a former student produced data about relationship between persons attested by medieval charters that can be used for network analysis (Figure 2).
The students can send the teacher a dump of their database and formulate the research questions that the latter will transcribe into SQL, XPath or procedure language queries for extracting data, before sending this back to the students. Building upon these examples the students can themselves adapt the queries and scripts to new research questions. A wiki dedicated to each student's project can be created to document the specific workflow of each research project: it is not public but it is accessible to all other students participating in the process of data production and analysis. The students can use the results of data analysis and visualization to formulate new research hypotheses or they can integrate them into their master's thesis.
In this paper I will present the essential conceptual and technical aspects of the whole workflow and consider three major advantages of this pedagogical approach for the disciplinary domain of digital history. First, students gain the experience of managing a workflow going from installation and personal practice on a solid community maintained open-source software, to reflection on data modeling concerning their own research agenda, to collaborative data and project management through a wiki, to an introduction in data mining and visualization techniques. Secondly, the abstraction level of the data model and text encoding practice proposed to the students implicitly introduces them to knowledge management and data production according to present-day standards like CIDOC-CRM and Text encoding initiative: from this perspective historical knowledge is modeled as a graph of objects situated in time and space and linked to the texts from which they derive. Thus —and this is the third advantage— the course acquaints students with the basic principles of linked data and of semantic text encoding, introducing them to the concepts and practice of resource sharing and data curation: the datasets I use for the exercises come from the French national library (BNF) SPARQL endpoint and DBPedia, and the texts from Wikipedia. In a final part, I will discuss the issues that this pedagogical approach raises for master's students in history.
- Alerini, J. and Lamassé, S. (2011). Données et statistiques. L'avenir du travail en ligne de l'historien. In: Genet, J.-P. and Zorzi, A. (eds), Les historiens et l'informatique. Un métier à réinventer. Rome: Ecole française de Rome, pp. 171-187.
- Beretta, F . (2015). The symogih.org project and TEI : encoding structured historical data in XML texts. In: Text Encoding Initiative Conference and Members’ Meeting 2015. Connect, Animate, Innovate, Lyon, France: https://halshs.archives-ouvertes.fr/halshs-01251915v1 .
- Cellier, J. and Cocaud, M. (2001). Traiter des données historiques : méthodes statistiques, techniques informatiques. Rennes: Presses universitaires de Rennes.
- Eide, Ø. (2014-2015). Ontologies, Data Modeling, and TEI. Journal of the Text Encoding Initiative, 8: Selected Papers from the 2013 TEI Conference. http://jtei.revues.org/1191.
- Erickson, A. T. (2013). Historical Research and the Problem of Categories. In: Dougherty, J. and Nawrotzki, K. (eds), Writing History in the Digital Age. Ann Arbor: University of Michigan Press, pp. 133-145.
- Gast, H., Leugers, A. and Leugers-Scherzberg, A. H. (2010). Optimierung historischer Forschung durch Datenbanken. Die exemplarische Datenbank "Missionsschulen 1887-1940". Bad Heilbrunn: Verlag Julius Klinkhardt.
- Jordanous, A., Stanley, A. and Tupman, C. (2012). Contemporary transformation of ancient documents for recording and retrieving maximum information: when one form of markup is not enough. Proceedings of Balisage, 8: The Markup Conference 2012, http://www.balisage.net/Proceedings/vol8/html/Jordanous01/BalisageVol8-Jordanous01.html.
- Masolo, C., Borgo, S., Gangemi, A., Guarino, N., and Oltramari, A. (2003). WonderWeb Deliverable D18 Ontology Library (final). Trento: Laboratory For Applied Ontology. PDF version: http://wonderweb.man.ac.uk/deliverables.shtml .
Some pages of the symogih.org project's user manual provide the encoding specification for XML/TEI semantic annotated texts using the symogih.org ontology: https://groupes.renater.fr/wiki/symogih/symogih_manuel/edition_de_textes_en_xml-tei.
This method was presented at the TEI 2015 conference in Lyon, cf. Beretta 2015. The Special Interest Group Ontologies in the TEI Consortium is devoted to this approach. See the GIS Ontologies wiki : http://wiki.tei-c.org/index.php/SIG:Ontologies and Eide, 2014-2015. A similar approach is represented by Jordanous, Stanley and Tupman, 2012.