Authors: Christoph Schindler, Basil Ell
Category: Paper:Short Paper
Keywords: qualitative methods, research environment, semantic graph, apparatus design
Linking Qualitative and Quantitative Research by Thin Descriptions through Semantic Graphs. Experiments in Apparatus Design with Semantic CorA.
1. Introduction
The use of Semantic Web Technologies in Digital Humanities projects has increased over the years, but only recently annotation tools and research environments have started to create and use semantic graphs (e.g. Pundit 1, Grassi et al. 2013, or CWRC 2, Rockwell et al., 2012). While the sharing of annotations and data into a formalized Web of Data is a central part of these projects, in this paper we would like to focus on capacities for qualitative research by using semantic graphs and linking these with quantitative data. Qualitative research approaches have thus far not been positioned at the core of Digital Humanities (Drucker, 2012). However, recent discussions about close and distant reading e.g., (Moretti, 2013) point out a manifestation of a strict opposition between qualitative and quantitative research on the level of data. We would like to reconfigure this separation between qualitative and quantitative data by taking into account its epistemological practices and apparatuses. Qualitative and quantitative data can be regarded as “thin descriptions”. Both need an interpretative act to become “thick descriptions” (Love, 2013). This involves a broad range of research capacities, whereby a semantic graph addresses parts of it and creates a link between both paradigms by connecting the different data. This main argument of the paper will be demonstrated through examples from ongoing Digital Humanities research projects based on the semantic research environment Semantic CorA 3, where we experimented with epistemological apparatuses which were developed through participatory design approaches and collaborative ontology engineering.
Re-Configuring the apparatus of qualitative and quantitative research
The recent focus in Digital Humanities on epistemological apparatuses, including their materiality, performativity and relation to theory, offers the possibility to sharpen the respective analytical concepts for data and research apparatuses. Ramsey and Rockwell (2012) describe tools as a “telescope for the mind” and offer a materialistic epistemology. Concerning the opposition of qualitative and quantitative research, Manovich (2011) describes the potentials of big data by contrasting quantitative methods (i.e., statistical, mathematical, computational) with qualitative methods (i.e., as used in History, Literature Studies, Anthropology, qualitative Social Sciences and Psychology) and the different kinds of underlying data. While quantitative approaches commonly rely on surface data, qualitative data are described as deep data. Manovich posits equivalent epistemological depth of both kinds of data but hints to the different scale of contact points with the object of interest.
Venturini and Latour (2010) point to the micro/macro distinction in Social Sciences, which corresponds to the qualitative/quantitative separation at the methodological level. The new capacity of digital, computerized methods, they point out, are quali-quantitative methods, which do not rely on the opposition of statistical analysis and ethnographic observation. Love (2013) concretizes this link between qualitative and quantitative approaches as well and takes into account the epistemological apparatus by comparing Literature Studies and ethnographic research. Instead of placing thin description in opposition to “thick description” (Geertz, 1973), Love (2013: 403) argues for the significance of thin description, which she considers as an integral part of thick description, and demands for a reflective engagement with the full range of empirical methods. In this sense the epistemological apparatuses are per se boundary-making practices, which “enact what matters and what is excluded from mattering” (Barad, 2007: 148) and demand an accountability of this material-discursive practice of epistemological apparatus design.
2. Designing Semantic CorA
The realization of Sematic CorA was driven by a participatory design and agile development approach of both the software components as well as the ontology. A main goal was to enable classical qualitative researchers to realize their research by using the potentials of a semantic graph. The design followed the research practice though an evolutionary process, which was initiated by an analysis of needs and requirements (i.e., site visit, artefact analysis, interviews) and was followed by nearly weekly meetings with requirement articulations and prototype testings. Semantic MediaWiki 4 was used as a technological platform, which was extended with newly developed tools (extensions) to address the needed research capacities.
3. Linking qualitative and quantitative Research with Semantic CorA
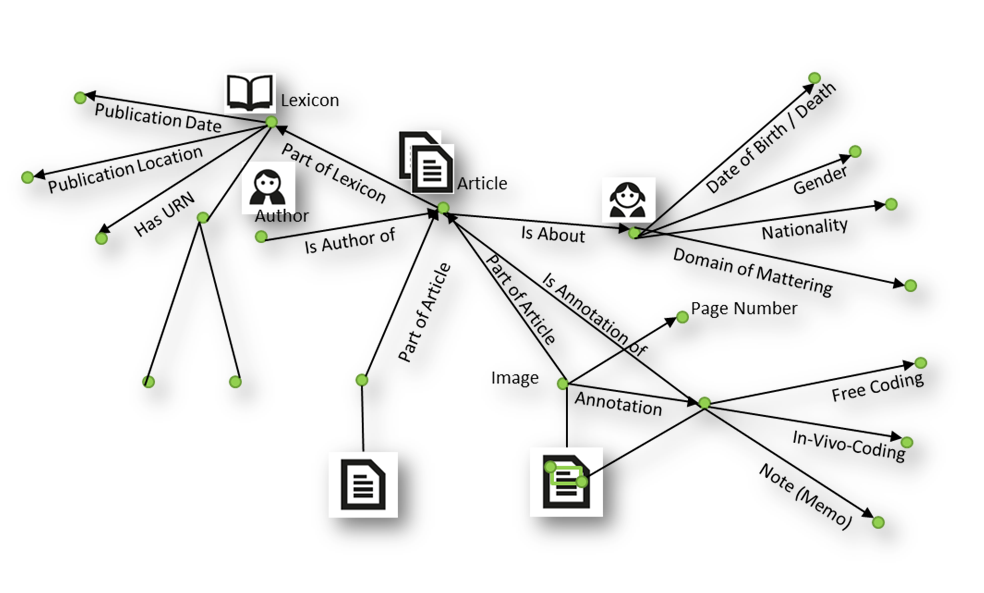
Openness and flexibility: In qualitative research, the openness of the research object and the flexibility to adjust the knowledge base play a central role in grasping the complexity of the phenomenon of interest (Bauer, Aarts, 2007). Using a semantic graph as an epistemological tool offers the possibility to create new entities, add properties or relate these to other entities. In this way, a network is created step by step based on the research material, which can be extended and re-arranged in the research process. So an all-encompassing fixed schema is not a precondition when starting a research project. The semantic graph consists of pages (representing entities), which are described by properties or links. Figure 1 demonstrates the schema of the semantic graph for exploring historical educational lexica (ranging from 1774 to 1945). Integrated bibliographic data (e.g., lexicon, article, author) and digital images of the lexica from a digital library 5 build the data basis for the graph, whereby the syntax supported by the SMW platform and data edit forms offer to enrich the graph. For example, a researcher establishes the relation `Is About´ between the article and a person and adds further properties (date of birth/death, gender, nationality, domain of mattering). In this respect, a thin description has been created, indicating a network of the phenomenon with more than 6 million values and 100,000 pages. 6
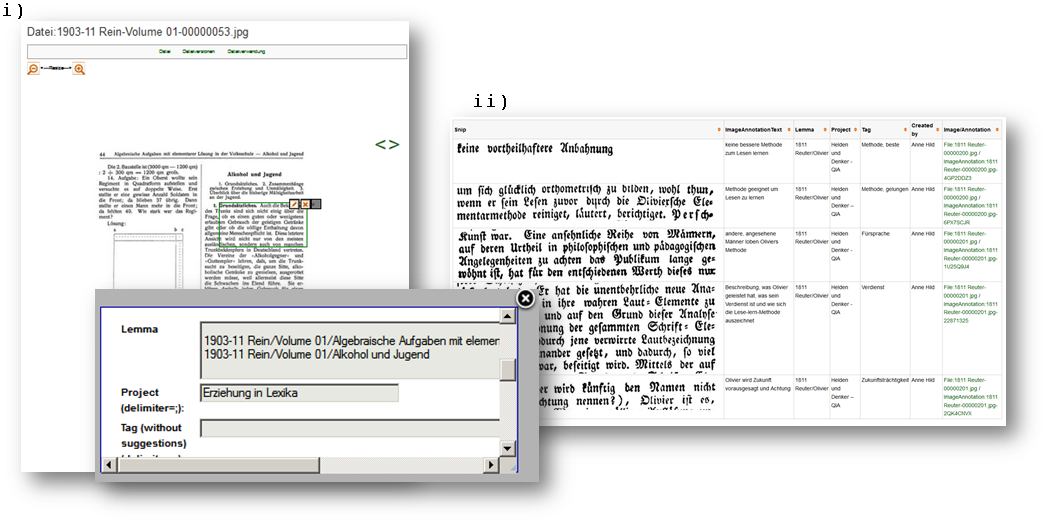
Balancing particularities and formalizations: In qualitative research it is necessary to balance formalization with respect to the particularities of the phenomenon of interest and the research material. Star describes this balance as achieved through facetted classifications in the methodological approach of the grounded theory (Star, 1998: 227). As previously described, a semantic graph offers the possibility to create a network, which calls for formalization and sets the boundaries of the phenomenon. To enable a more `fuzzy´ or qualitative thin description, each node and property of the graph can be described in an unformalized way using the classical text tools of a wiki. Additionally, an open approach for qualitative content analysis is followed to enable annotations of the text (Figure 2). In this way, the annotation is connected to the article on the basis of the semantic graph (Figure 1), providing links between the annotations of the qualitative content analysis and the further network of the semantic graph. This constitutes a thin description based on qualitative data (e.g., through close reading and annotations) and quantitative data (e.g., bibliographic data), where an interpretative act is needed for the description to become a thick description.
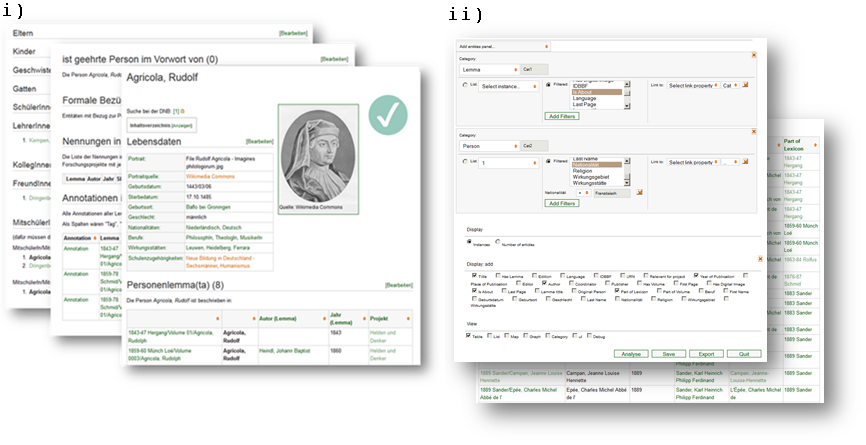
Ongoing data analysis and graph creation: Another main aspect of qualitative research is the ongoing iteration between grasping the research material and creating new connections or qualities. This intensive work with research data can be done by comparing, following associations, close reading, or – as previously described – by distant reading of aggregated or related elements. While using a semantic graph as a network of the phenomenon, two different examples can be demonstrated which use the linkage between qualitative and quantitative data: Semantic browsing and querying the network. To represent relevant parts of the graph, aggregations and inferences are created for main entities (e.g. 1,200 aggregated descriptions of persons) to thickening the research data and browsing through the network (Figure 3, i). Additionally, a query tool enables to query and aggregate the semantic graph (Figure 3, ii).
4. Discussion and outlook
This paper demonstrates the possibility of linking qualitative and quantitative data by using semantic graph technologies to create thin descriptions. Therefore, the advantages of the interpretative act of thick descriptions are considered by allowing for ongoing iterations of analyzing the research material and creating the semantic graph in a formalized and unformalized way (enrichments, annotations, text descriptions). With semantic browsing, aggregations of information, annotation and querying the semantic graph, aspects of close and distant reading are addressed, thus offering new techniques for grasping the research material for qualitative research.
For the Digital Humanities, the focus on mattering of apparatuses offers the possibility to open the design space for digital tools to the diversity of epistemological practices in Humanities. Thereby, an engagement with the diversity of the Humanities comes to the front, enhancing the accountability of boundaries and possibilities of epistemological apparatuses in Digital Humanities.
Acknowledgements
The authors would like to thank the research group around Semantic CorA, especially Marc Rittberger, Lia Veja, Kendra Sticht, Anne Hild, and Anna Stisser. The initial realization of the research environment Semantic CorA was supported by the German Research Foundation (DFG) and its further development is supported in the context of CEDIFOR by the eHumanities program of the German Federal Ministry of Education and Research (BMBF) no. 01UG1416C.
- Barad, K. (2007). Meeting the Universe Halfway: Quantum Physics and the Entanglement of Matter and Meaning. Duke University Press.
- Bauer, M. W. and Aarts, B. (2007). Corpus Construction: a Principle for Qualitative Data Collection. In Bauer, M. W. and Gaskell, G. (Eds.), Qualitative Researching with Text, Image and Sound: A Practical Handbook. London: Sage, pp. 19–37.
- Drucker, J. (2012). Humanistic theory and digital scholarship. Debates in the Digital Humanities, pp. 85–95.
- Geertz, C. (1973). The Interpretation of Cultures: Selected Essays. Basic books.
- Grassi, M., Morbidoni, C., Nucci, M., Fonda, S. and Piazza, F. (2013). Pundit: augmenting web contents with semantics. Literary and Linguistic Computing: fqt060 doi:10.1093/llc/fqt060.
- Love, H. (2013). Close Reading and Thin Description. Public Culture, 25(371): 401–34.
- Manovich, L. (2011). Trending: the promises and the challenges of big social data. Debates in the Digital Humanities, pp. 460–75.
- Moretti, F. (2013). Distant Reading. Verso Books (accessed 31 October 2015).
- Ramsey, S. and Rockwell, G. (2012). Developing Things: Notes toward an Epistemology of Building in the Digital Humanities. In Gold, M. K. (Ed), Debates in the Digital Humanities. Minneapolis: University of Minnesota Press, pp. 75–84.
- Rockwell, G., Brown, S., Chartrand, J. and Hesemeier, S. (2012). CWRC-Writer: An In-Browser XML Editor. Poster Presented at Digital Humanities.
- Star, S. L. (1998). Grounded Classification: Grounded Theory and Faceted Classification. Library Trends, 47(2): 218–32.
- Venturini, T. and Latour, B. (2010). The social fabric: Digital traces and quali-quantitative methods. Proceedings of Future En Seine, pp. 30–15.
Additionally, the technological platform itself offers the possibility to link elements of the graph to established Semantic Web vocabularies (i.e., BIBO or DC); this has been performed for a large part of the data.