Authors: Olga Sozinova
Category: Paper:Poster
Keywords: Russian poetry, metrics, graph, database, rhyme
Complex Networks-Based Approach to Russian Rhyme History Description: Linguostatistics and Database
1. Introduction
Russian rhyme was described thoroughly in the 20th century, especially by M. Gasparov (Gasparov, 2000). Though we now have a powerful tool to analyze rhymes further in the form of the poetic corpus of the Russian National Corpus (henceforth RNC), not much recent research has been carried out in this area (Orekhov, 2015). As I am particularly interested in visualizing corpus data, I applied graphs to rhyme analysis.
Rhymes are convenient entities to be described in graph terms. In a rhyming pair, words are nodes, and rhyme relationship between them is an edge between nodes. Certain properties can be assigned to the nodes and to the edges. For example, word nodes may contain grammatical information and rhyme edges may bear all the rhyme classification (meter, position, etc.).
Furthermore, nowadays, there are tools available for storing graph information in a database. Information from such databases can be retrieved easily and in several formats.
My aim was to build a graph database using the data from the poetic corpus of the RNC. I want to show that the manual research done previously can be supported and extended in a vivid graphic way.
Graphs can provide us with much information about rhyme diachrony:
- Degree of connectivity in different periods (different rhyming tendencies);
- The longest path (chain of rhymes) and clusterization (popular rhymes in different periods);
- Tendency flow from exact rhymes to inexact (requested by parameter of exactness in the different periods);
- Appearance of the dissonance rhymes;
- Tendency flow in rhyming types, position;
- Domination of a certain rhyming type within the rhymes of one poet.
2. Data
The whole poetic corpus of the RNC was used for analysis. The data covers 775 Russian authors, born between 1658—1939. Overall, the corpus contains 85,996 documents, 229,968,798 words.
3. Analysis
Technical work included the following steps:
- Transcribing words in a rhyme position;
- Retrieving rhymes from poems according to the phonetic transcription;
- Rhyme classification;
- Building new nodes and edges in the graph database.
I used Python for rhyme extraction and classification and a Neo4j database for storing the data.
As I could not find any available modules for Russian transcription, I made this module myself using the transcribing rules from [http://www.philol.msu.ru/~fonetica/index.htm]. The module takes into account almost every rule, but the exception word lists are quite small.
The rhyme extraction algorithm I used was the following. The Python program finds all the tags <rhyme-zone> (tagged everywhere except blank verse) in the XML documents with poems (last words in lines). Then the program tries to find a possible rhyming pair within 4 lines before and after the current rhyme-zone word. Afterwards comes the transcriptions comparison; if stressed vowels are the same, then the process of classification begins. If the stressed vowels are different, then the dissonance rhyming type is checked.
The classification of the rhymes was based on (Surkov, 1962), (Kvjatkovskij, 1966) and (Timofeev, 1935). I took 8 parameters into account:
- Exactness (exact or inexact);
- Richness (rich or poor);
- Depth (deep or not);
- Ending (open or closed);
- Position of the stressed vowel (male, female, dactyl, hyperdactyl);
- Rhyming type (paired, crossed, encircling);
- Assonance;
- Dissonance.
As soon as a new rhyming pair is found and classified, new nodes and edges are automatically created in the graph database. If any of the words existed in the database before, then an edge is created to the existing node; otherwise, a new node is created.
4. Results
For now, I have rendered several graph images for certain poets with approximately 30% of their rhymes. In Figure 1 there are 2570 rhymes from the poems of P. Vjazemskij. Figure 2 shows 3866 rhymes from the poetry of A. Pushkin.
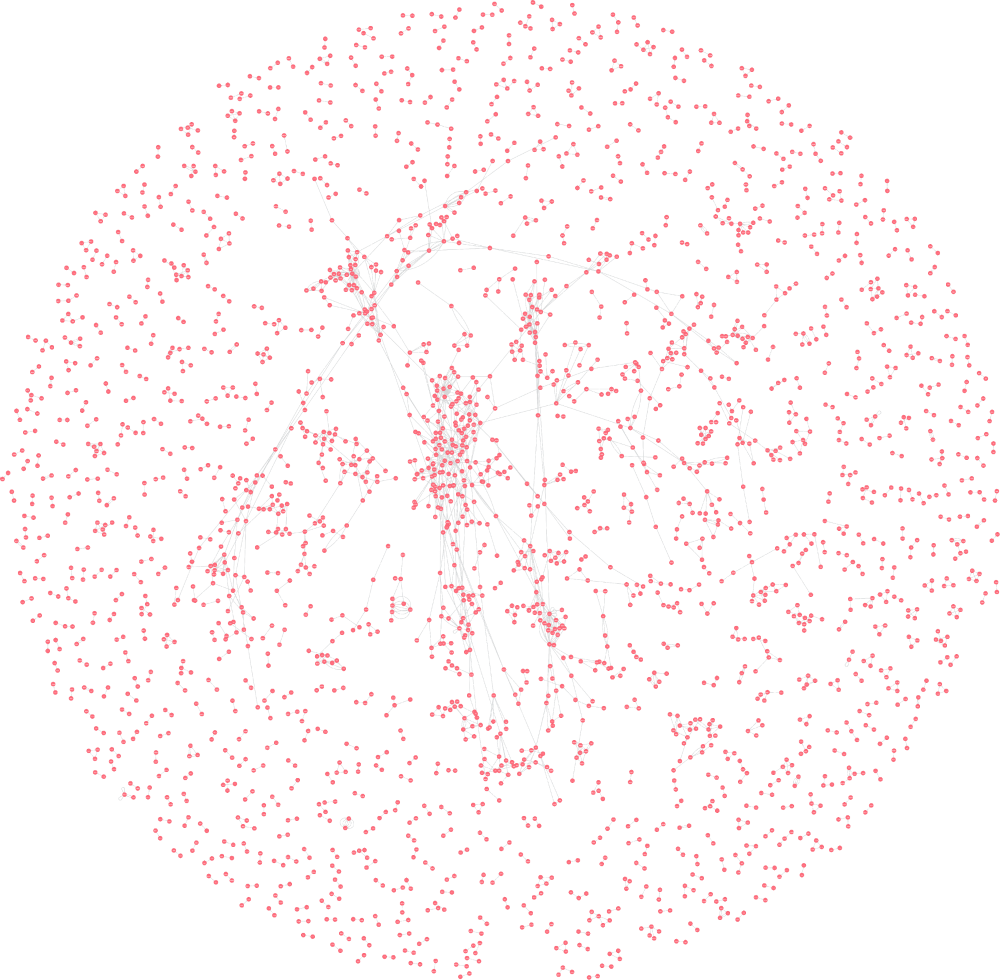

From the figures, we can see that connectivity in Pushkin's graph is much higher than in Vjazemskij's graph. Furthermore, the graph of Vjazemskij's rhymes demonstrates certain clusters which can be analyzed in detail.
I plan to continue my research and obtain other graphs for the whole epoch. I hope that further work will provide the information I listed in the introductory part, especially regarding connectivity and clusterization over different time periods. Quantitative analysis remains to be done as well. Firstly, I would like to look at the graph patterns, and then go deeper into calculations of graph characteristics and their interpretations.
- Gasparov, M. (2000). Očerk istorii russkogo stikha [Studies of the Russian verse history]. Fortuna limited.
- Kvjatkovskij, A. (1966). Poetičeskij slovar' [Poetic dictionary]. Sovetskaja Enciklopedija.
- Orekhov, B. (2015). Ešče raz ob issledovatel'skom potenciale poetičeskogo korpusa: metr, leksika, formula [One more time about the research potential of the poetic corpus: meter, lexicon, formula]. Russian National Corpus, in print.
- Surkov, A. (1962). Kratkaja literaturnaja enciklopedija [Short literary encyclopedia], 1. Sovetskaja enciklopedija.
- Timofeev, L. (1935). Literaturnaja enciklopedija [Literary encyclopedia], 9. Sovetskaja enciklopedija.