Authors: Robert Casties
Category: Paper:Short Paper
Keywords: islamic manuscripts, network database, data modeling
An Islamic Manuscript Database as a Network of Objects
1. The ISMI project
The Islamic Scientific Manuscripts Initiative (ISMI) is a project by the Max Planck Institute for the History of Science and the Institute of Islamic Studies at McGill University in Montreal to collect and make accessible information on all Islamic manuscripts in the exact sciences (astronomy, mathematics, optics, mathematical geography, music, mechanics, and related disciplines), whether in Arabic, Persian, Turkish, or other languages ranging in time from the 8th to the 19th century. Since 2007 the project has collected information on over 4000 texts existing in 14500 witnesses in 7500 codices, as well as information on over 2000 persons. A preliminary website with a subset of information on 130 codices is already available online ( https://ismi.mpiwg-berlin.mpg.de).
The project's goal is to create a catalogue database of all relevant manuscripts and record as much information on these manuscripts as available. The collected data contains basic bibliographic information but also paleographic and codicological information, and also information about the content of the texts and information about the uses of the manuscript and its users.
The manuscripts sometimes and notes and colophons providing information about the reading of a text or the use of a text in teaching, about sponsors and the acquisition and ownership of the manuscripts over time. With this information the database not only provides a powerful bibliographical research tool for scholars in the field, but also helps to answer questions pertaining to the historical and social context of knowledge like: Was the author working as an isolated individual or as part of a scientific group? Was this a well-known text? Did it influence subsequent workers in the field? Was it studied at a court or in a school?
2. A manuscript database
Cataloging old manuscripts is already a task that overwhelms standard bibliographical databases. There is the problem of anonymous authors at the same time as a proliferation of authors with the same or similar names. The integration of information from different sources is made difficult by libraries changing the names of their collections and their numbering systems or libraries themselves being incorporated or centralized into other institutions. Adding to that are the problems of handling of Arabic writing and the multitude of slightly different Arabic romanization systems.
Other requirements also arose in the project early on: for example the need to record and present outdated information. In many cases authorship information has been misattributed widely and for long times so that scholars coming to the database looking for specific information may search under a wrong name or assume the database to be in error unless the common misattribution is also presented with arguments of why the old information is superseded.
3. Manuscripts as network of objects
The database development started in 2006 with a new data model based on the idea of a network of flexible objects and relations. Objects can have arbitrary attributes which are text strings. The relations between objects are also like objects and also have attributes.
The objects are things like an abstract TEXT, a concrete WITNESS and a real or imaginary PERSON while relations like is_exemplar_of connect a text and its witnesses and was_created_by connects the texts and a person as its author. The same person can at the same time also be connected to other witnesses as a copyist or as a sponsor.
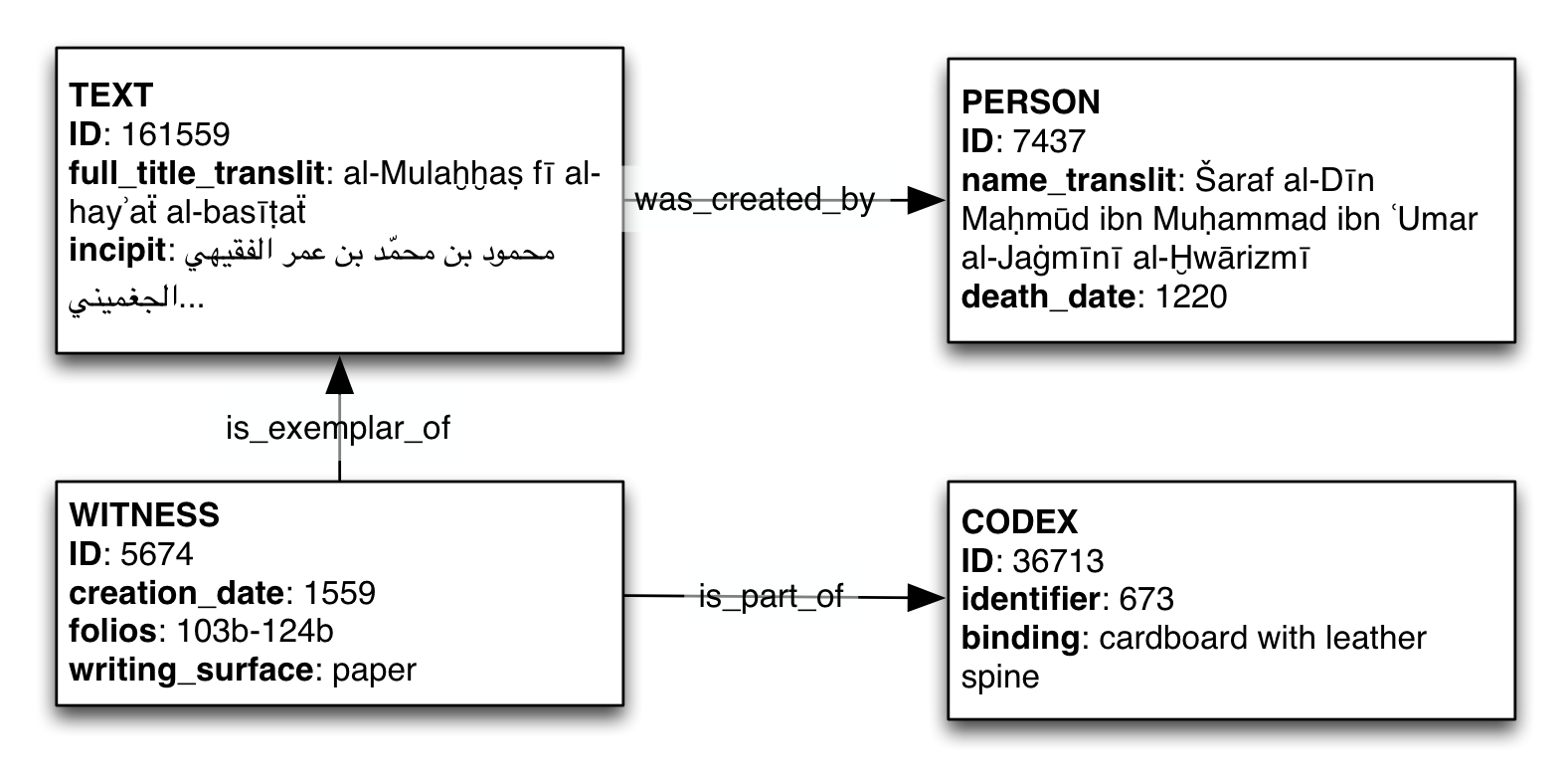
The flexible nature of the relations made it easy to introduce new relation types as it became necessary in the research process, for example to record the documented reading of a manuscript or the misattribution of authorship.
This concept of a network of objects with flexible relations, also called an attribute-graph exists in database products like Neo4J today but those were not available in 2006 which led to the development of a custom database called "OpenMind". The database software is Open Source, written in Java, uses a conventional SQL database backend and a Web-based frontend.
4. Challenges of networked data
The network-like structure of data in the database makes it easy to add new relation types or new attributes to objects while at the same time making it more difficult to create simple forms for entering data for things that are composed of multiple objects in the data model. A form for a manuscript for example not only creates a witness object but also creates relations to a text object, multiple person objects, codex, collection, library and place objects, creating those objects if they do not exist.
Visualising and querying such networks of data objects is also a new challenge where few established tools and concepts exist. Data can be projected into conventional tools like tables and spreadsheets researchers may be familiar with but these do not exploit the full potential of existing relations. Network visualisation tools and methods on the other hand make if often difficult to browse and search for specific items and require a careful selection of semantically relevant relations for the application of standard graph-theoretical measures.
The project currently explores different tools and methods and gathered input from expert scholars in the field in a workshop in February 2016 to be presented at the conference.
- Ragep, Jamil F., and Sally P. Ragep. (2008). The Islamic Scientific Manuscript Initiative (ISMI) Towards a Sociology of the Exact Sciences in Islam. In Calvo E., Comes M., Puig R., and Rius M. (eds.), A Shared Legacy: Islamic Science East and West. Homage to Professor J. M. Millàs Vallicrosa, Barcelona: University of Barcelona, pp. 15–21. https://www.rasi.mcgill.ca/ISMI_SharedLegacy.pdf