Authors: Krzysztof Nowak, Bruno Bon, Renaud Alexandre
Category: Paper:Poster
Keywords: Latin, mashup, human-oriented integration
Medialatinitas.eu. Towards Meaningful Integration and Retrieval of Resources for Medieval Latin
Latin was one of the most widely used languages in European history. In its spoken and written it was the language of daily communication, law, literature, and science for over fifteen centuries on the territory stretched from Spain to Germany to Poland and from Sweden to Croatia to Italy. The geographical, chronological and functional variation is reflected in a large number of texts which, in turn, gave rise to a vast body of secondary literature. These multifarious resources, though, even if by now partly available in digital form, remain still widely dispersed and do not easily lend themselves to integrated search.
medialatinitas.eu (Nowak and Bon, 2015) is a web mashup which aims at meaningful integration of textual, lexicographic and encyclopaedic resources for Latin. Apart from improving access to the data, the main goal of the presented application is to challenge the separation of linguistic competence and real-world knowledge in vocabulary description, as both components should effectively cooperate in comprehension of the Medieval Latin text and culture. The medialatinitas.eu may also compensate for major deficiencies of the resources (separate electronic text collections, for instance, covering only small proportion of the texts preserved etc.), as well as of the poorly designed interfaces and query engines they are made available through.
The heterogenous content (both academic and community-based dictionaries, thesauri, gazetteers; corpora and text collections; encyclopedias, document and image repositories, library catalogues etc.) has been interlinked only to the degree needed for its unified query. As a result, the data integration takes place mainly at the level of the web interface which thus constitutes presentational layer and a point of access to the services running in the background. When first visiting the page, users (be it lexicographers, linguists, historians etc.) come across a basic autocomplete search field: here, they can ulate the query phrase (as for now only lemma search has been implemented) which is next processed and despatched to both locally and distantly running services. The results are subsequently returned and displayed on the main page as a set of separate widgets, each of which may contain a concordance, a table, or another of data visualisation (timelines, charts, maps, lists etc.). As a whole, the widgets contribute to extensive description of linguistic and cultural properties of the lexical units.
The medialatinitas.eu attempts to address the drawbacks of popular dictionary aggregators in which the very fact of juxtaposing multiple resources seems often to suffice as their raison d’être. Destined for scholarly users, the medialatinitas.eu will make a heavy use of graphical hints and narrative devices such as interpretative notes and explicative commentaries which will accompany visual data representations in particular. On click, every widget will provide an interested user with fuller description of selected semantic or distributional properties of the word and constitute an entry point to an instance of CQPWeb (corpora), eXist-db (dictionaries), or R dashboard.
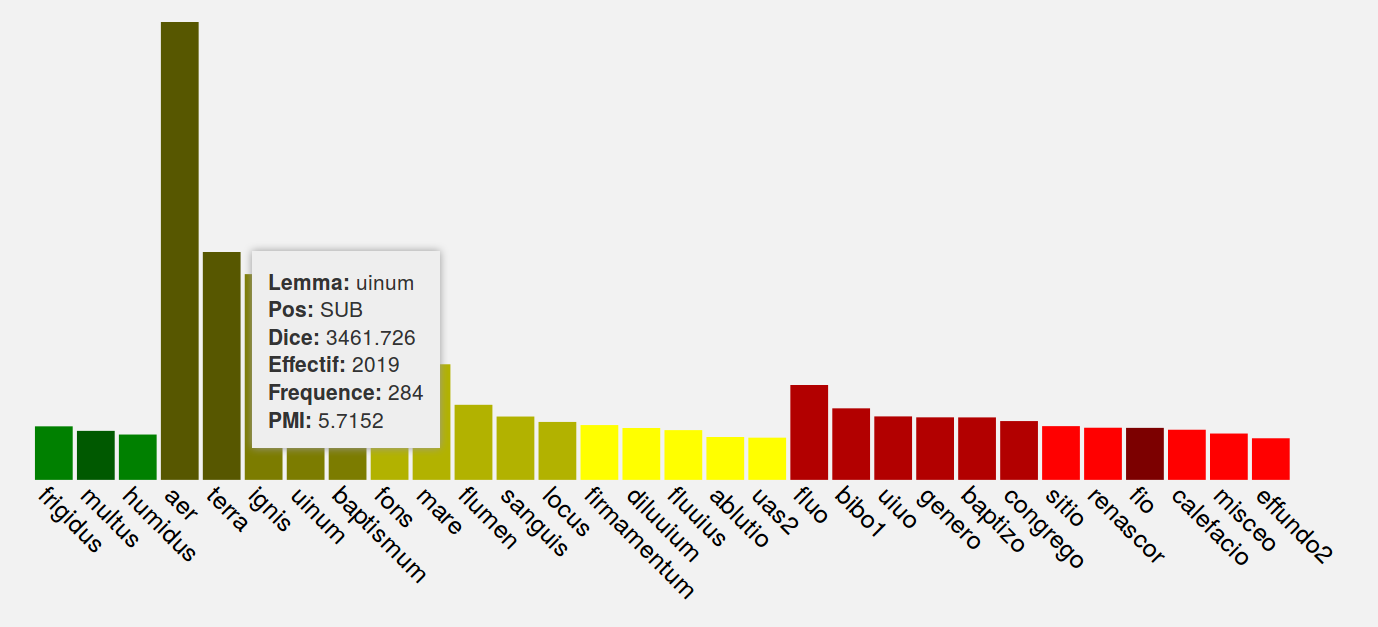
Barplot representing computed co-occurrences of the lemma AQUA “water” in the Patrologia Latina corpus (data fetched from an R session exposed as an OpenCPU API; the chart generated with the d3.js library).
The external resources are exploited through their public APIs. This is also the case of the locally hosted services. Yet, their role is by no means limited to only exposing data, since they also serve to enrich, compute on and prepare data for subsequent display. For instance, an R session is exposed to the web application through the OpenCPU API (Ooms, 2014) and permits computation on corpusand lexicography resources: the rcqp package (Desgraupes and Loiseau, 2012) is used to connect to the CQP engine (Hardie, 2012), A. Guerreau’s scripts for lexical statistics allow to find co-occurrences of the lemma in the corpus, and the wordspace package (Evert, 2014) is employed to calculate word similarities based on word's distributional properties.
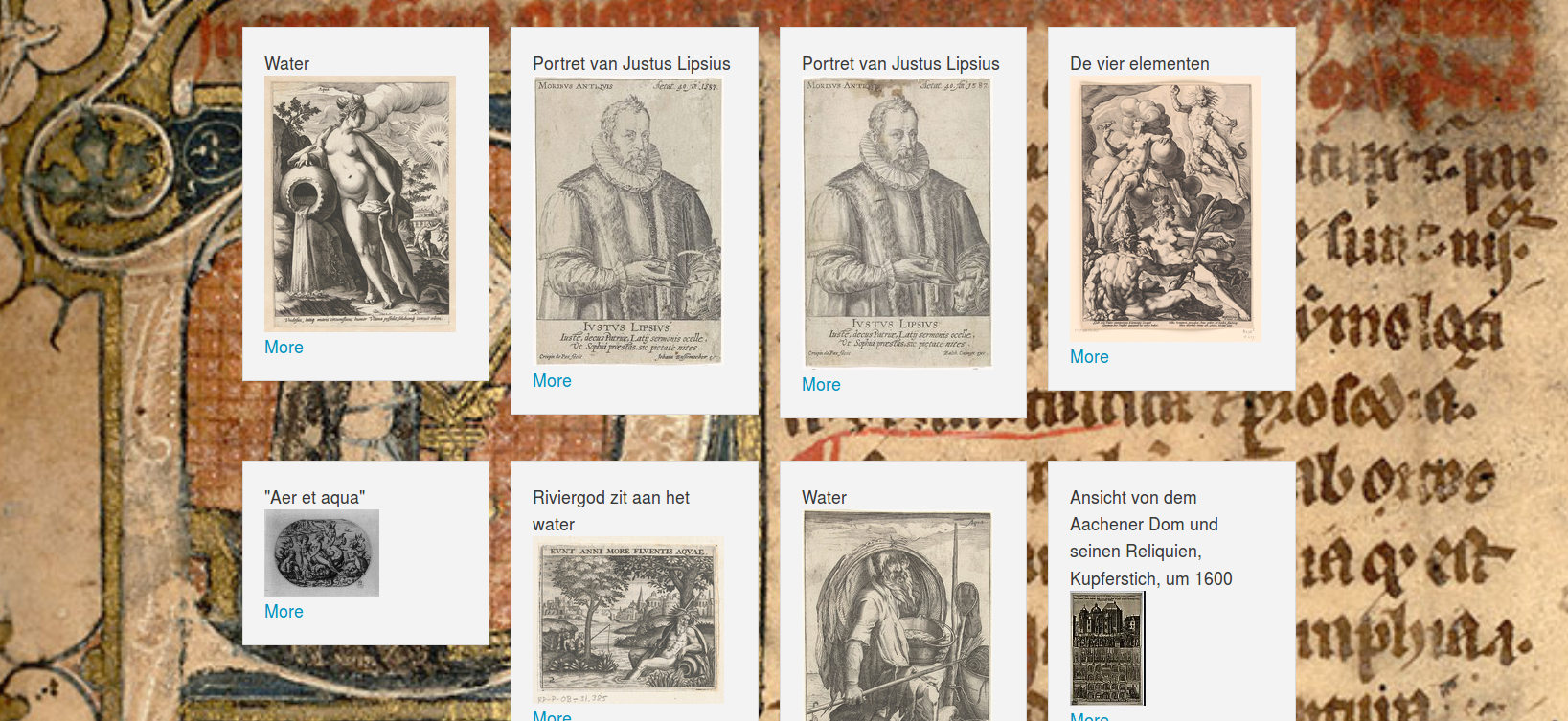
Image search (the lemma AQUA “water”) in the Europeana repository.
In spite of the relative variety of technologies and formats used, the medialatinitas.eu is planned to be developed in a modular way, so the users could contribute their widgets as R or JavaScript code snippets responsible for self-contained functionalities.
- Desgraupes, B. and Loiseau, S. (2012). rcqp: Interface to the Corpus Query Protocol. http://CRAN.R-project.org/package=rcqp (accessed 2 March 2016).
- Evert, S. (2014). Distributional Semantics in R with the wordspace Package. In Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: System Demonstrations. Dublin: Dublin City University/Association for Computational Linguistics, pp. 110–14.
- Hardie, A. (2012). CQPweb — combining power, flexibility and usability in a corpus analysis tool. International Journal of Corpus Linguistics, 17(3): 380–409.
- Nowak, K. and Bon, B. (2015). medialatinitas.eu. Towards Shallow Integration of Lexical, Textual and Encyclopaedic Resources for Latin. In I. Kosem et al. (Eds.). Electronic lexicography in the 21st century: linking lexical data in the digital age. Proceedings of the eLex 2015 conference. Ljubljana/Brighton: Trojina, Institute for Applied Slovene Studies/Lexical Computing Ltd., pp. 152–69.
- Ooms, J. (2014). The OpenCPU System: Towards a Universal Interface for Scientific Computing through Separation of Concerns. ArXiv e-prints. http://arxiv.org/pdf/1406.4806v1.pdf (accessed 1 March 2016).