Authors: Menzo Windhouwer, Twan Goosen, Jozef Misutka, Dieter Van Uytvanck, Daan Broeder
Category: Paper:Long Paper
Keywords: metadata, infrastructure, community driven. flexibility
Flexible Community-driven Metadata with the Component Metadata Infrastructure
1. Introduction
Many researchers, from the humanities and other domains, have a strong need to study resources in close detail. Nowadays more and more of these resources are available online. To make these resources discoverable, they are described with metadata. These metadata records are collected and made available via central catalogues. Often, resource providers want to include specific properties of the resource in the metadata. The purpose of catalogues will be more generic and addresses a broader target audience. It is hard to strike the balance between these two ends of the spectrum with one metadata schema, and mismatches can negatively impact the quality of metadata provided. The European CLARIN infrastructure (CLARIN ERIC, 2016b) was confronted with this specific problem, and designed a solution based on a flexible mechanism to build resource specific metadata schemas, potentially using domain, community or project specific terminology, out of shared components and semantics. This paper introduces this approach and the infrastructure built for it, which is applicable to any domain with the same needs.
2. Component Metadata
In the Component Metadata (CMD) Infrastructure (CMDI) (CLARIN ERIC, 2016c; Broeder et al., 2012) the metadata lifecycle starts with the need of a metadata modeler to create a dedicated metadata profile for a specific type of resources, e.g., speech recordings (e.g., HZSK, 2015) or historical letters (e.g., Roorda, 2013). The modeler can browse and search a registry for components and profiles that are suitable or come close to meeting the requirements at hand. A component groups together metadata elements that belong together and can be potentially reused as a group in a different context, e.g., a location or a language description. Components can also group other components, e.g., the actor component can contain the general location component. The CMDI Component Registry (CLARIN, 2016a) already contains many of these general components. And these can be reused as they are or be adapted, i.e., add or remove some metadata elements and/or components. Also completely new components can be created to model the unique properties of the resources under consideration. All the needed components are combined into one profile that is specific to the type of resources, e.g., a profile for a speech recording (see Figure 1). Components, elements and values in this profile are linked to a semantic description, e.g., a concept, to make their meaning explicit. This feature allows the use of community specific terminology, while still creating a shared semantic layer that can be exploited by generic tools. Finally, metadata creators can create records for specific resources that comply with the profile relevant for the resource type, and these records can be provided to local and global catalogues. Notice also that CMD leaves the final responsibility of how heavy a metadata description should be to the modeler: it is perfectly possible to create a lean profile, resulting in lightweight records and combine it with a full-text index of the resources for discovery.
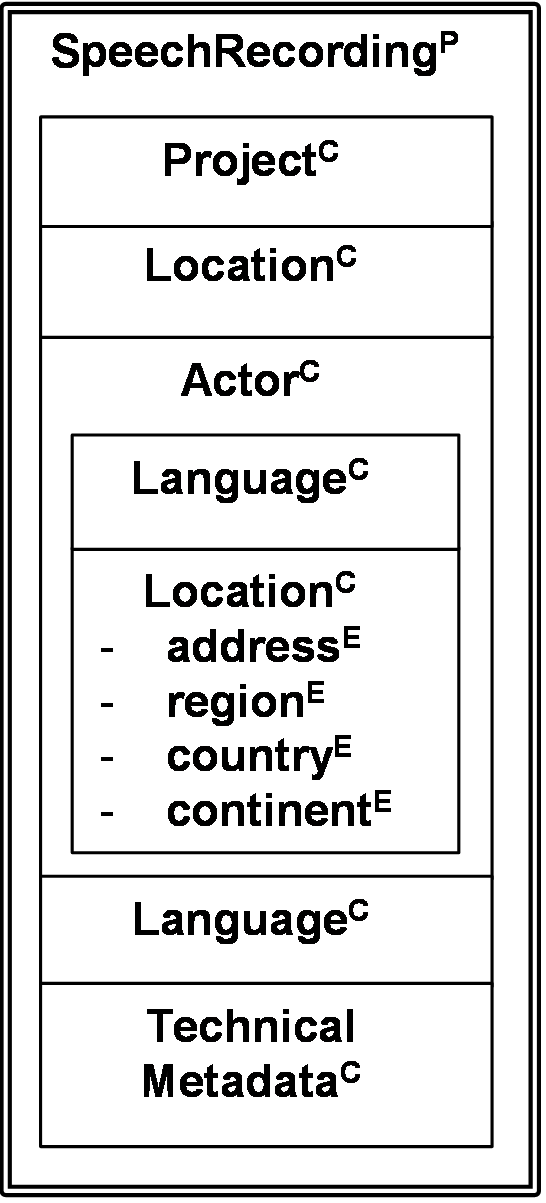
The Component Metadata approach is currently being standardized by ISO Technical Committee 37. And the first part (ISO 24622-1, 2015) of this family of standards has been released and specifies the model just described.
3. Component Metadata Infrastructure
CLARIN built an infrastructure (see Figure 2) around the approach described in the previous section. This infrastructure is open source and provides many tools, which can readily be reused by other communities.
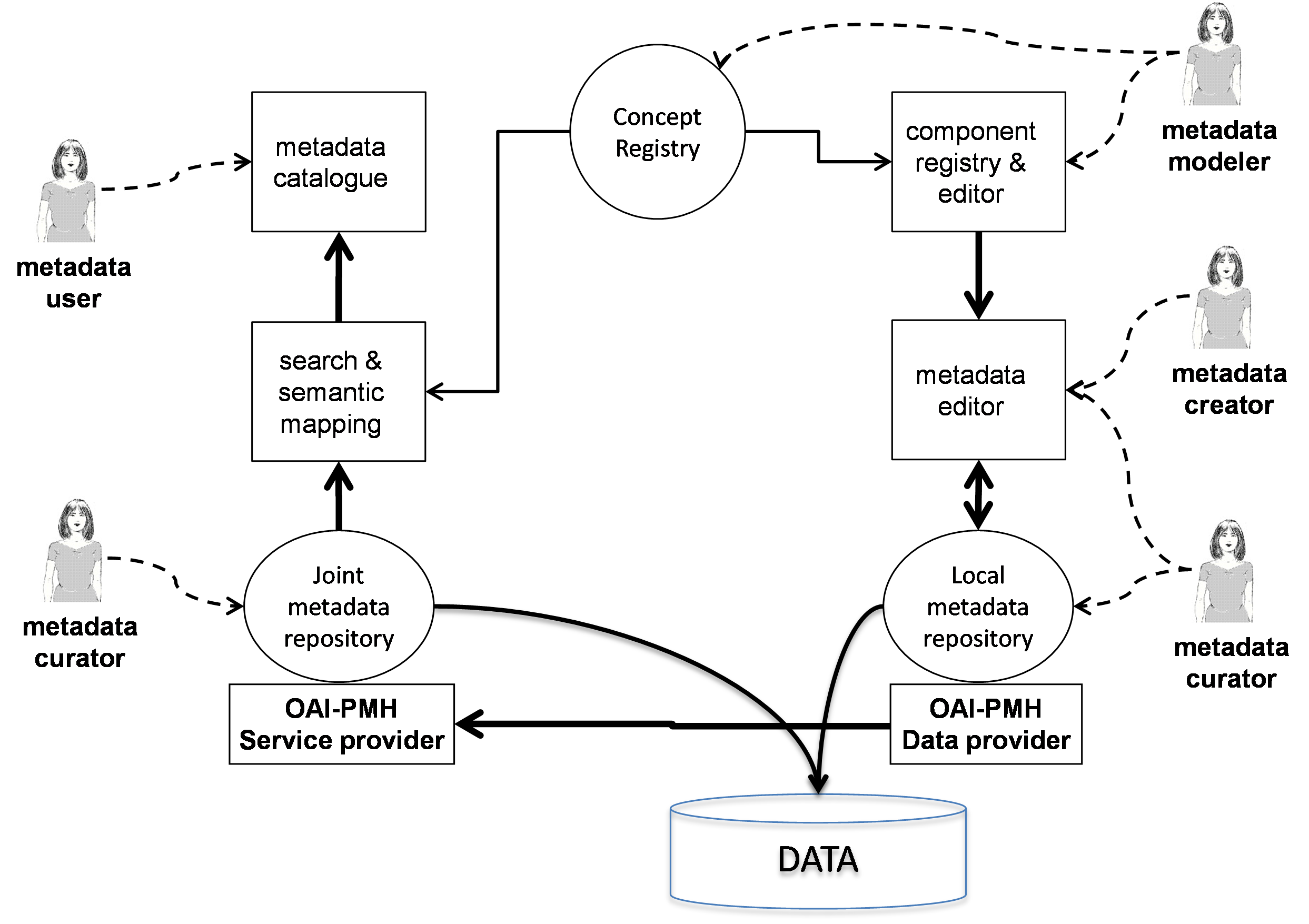
CMDI toolkit (CLARIN, 2016b): A set of XML schemas and transformations that implement the workflow from validating component and profile specifications to conversion into profile specific XML schemas used to validate specific CMD records.
Component Registry (CLARIN, 2016b): A registry storing the profiles and components created by the community for reuse. It also provides an editor for the creation of new profiles and components and derivatives of existing ones. The backend also provides REST services based on the toolkit, i.e., serves the XML schema representation of a CMD profile.
Concept Registry (CLARIN, 2016c; Schuurman et al., 2015): A SKOS-based registry storing the communities widely accepted concepts and their relations, which form the general semantic network overlaying the specific metadata profiles (Durco and Windhouwer, 2014).
CMD editors and forms: Various general CMD editors have been developed, e.g., the desktop tool Arbil (The Language Archive, 2016a) and the online editor COMEDI (CLARINO, 2016). Also dedicated forms for specific profiles, e.g., the CMDI maker (CLARIN-D, 2016), which can be inspiring.
Repository systems: Many CLARIN centers have deployed and configured generic repository systems to store their resources accompanied by CMD records. LINDAT (UFAL, 2016) and The Language Archive (2016b) have done so as well and released their solutions as general CMD-capable repository systems.
OAI harvester (The Language Archive, 2016c): CMD records can be harvested with any OAI harvester, but this harvester is special in that has easy provisions to add transformations to CMD that enable the harvesting of other metadata formats.
Catalogues: Faceted browsing is a suitable and commonly applied method for exloring vast collections based on some key properties. The CLARIN Virtual Language Observatory (VLO) (CLARIN, 2016d) is such a browser. Although the front-end is rather CLARIN specific, the VLO importer in the back-end, which takes the harvested CMD records, determines the facets and their values and stores these in a SOLR index, is generic because the facet mapping is highly configurable and exploits the shared semantic layer. The Meertens Institute has developed an alternative faceted browser (Meertens Institute, 2016) for CLARIN-NL. The importer of this browser does not take any configuration and dynamically creates facets for any semantically different context it finds in the CMD records.
Convertors: CMDI is currently XML oriented, but other representation formats are possible. The CMD2RDF service (CLARIN-NL, 2016) provides a RDF representation to link CMD records with the world of Linked (Open) Data. Also convertors for other metadata formats, e.g., MODS or OLAC, to CMD are available.
Although this list is far from complete it shows that the CMD Infrastructure is a thriving and versatile software ecosystem. Also many parts of it are configurable, which makes it adaptable to other domains.
4. Lessons learned by CLARIN
When CLARIN started development on the CMD Infrastructure in its preparatory phase many things were not clear yet and a lot of flexibility was needed. Common and reusable components and concepts still had to be specified. This has lead to situations where sometimes several alternatives have coexisted for a long time in the CMD ecosystem, which can make it hard for users, especially novices, to select which one to use. It is better to prevent this kind of confusion. CLARIN advises new communities that start using the CMD Infrastructure to first setup a set of basic recommended or even obligatory components and concepts, so a stable generic core is available to the community to extend with their specific needs.
5. Future work
CLARIN keeps on working actively on the CMD Infrastructure, with the next version, i.e., CMDI 1.2 (Goosen et al., 2015) currently under development. The following topics will be addressed by this update:
- Lifecycle management of components and profiles.
- Connection to vocabulary services.
- Annotation of profiles and components with hints targeted at tools.
Also improvement of the metadata quality is an ongoing process. The ongoing CLARIN-PLUS project (CLARIN ERIC, 2016a) includes the design and development of tools and and a workflow that can be used used by metadata curators for quality assessment and curation of CMD records (King et al., 2015).
6. Conclusions
CLARIN has built a highly flexible and versatile infrastructure for metadata that is able to meet both the generic needs of catalogues and the specific needs of resource providers. The fruits of these efforts are ready to be picked by any community experiencing the same needs. CLARIN is happy to share their experiences as well as the sometimes hard learned lessons.
- Broeder, D., Windhouwer, M., Van Uytvanck, D., Goosen, T. and Trippel, T. (2012). CMDI: a Component Metadata Infrastructure. Proceedings of the Metadata 2012 Workshop on Describing Language Resources with Metadata: Towards Flexibility and Interoperability in the Documentation of Language Resources. Istanbul, Turkey: European Language Resources Association (ELRA).
- CLARIN (2016a). Component Registry https://catalog.clarin.eu/ds/ComponentRegistry (accessed 24 February 2016).
- CLARIN ERIC (2016a). Factsheet: CLARIN-PLUS https://www.clarin.eu/node/4213 (accessed 3 March 2016).
- CLARIN ERIC (2016c). Component Metadata http://www.clarin.eu/content/component-metadata (accessed 24 February 2016).
- CLARINO (2016). COMEDI:: The COmponent Metadata EDItor http://clarino.uib.no/comedi/page (accessed 24 February 2016).
- Durco, M. and Windhouwer, M. (2014). The CMD Cloud. In Calzolari, N., Choukri, K., Declerck, T., Loftsson, H., Maegaard, B., Mariani, J., Moreno, A., Odijk, J. and Piperidis, S. (eds), Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14). Reykjavik, Iceland: European Language Resources Association (ELRA).
- Goosen, T., Windhouwer, M., Ohren, O., Herold, A., Eckart, T., Durco, M. and Schonefeld, O. (2015). CMDI 1.2: Improvements in the CLARIN Component Metadata Infrastructure. Selected Papers from the CLARIN 2014 Conference. (Linköping Electronic Conference Proceedings). Soesterberg, The Netherlands: Linköping University Electronic Press, Linköpings universitet.
- HZSK (2015). SpokenCorpusWithResourcesProfile https://catalog.clarin.eu/ds/ComponentRegistry/ - /?itemId=clarin.eu%3Acr1%3Ap_1442920133048®istrySpace=public (accessed 3 March 2016).
- ISO 24622-1 (2015). Language Resource Management - Component Metadata Infrastructure (CMDI) - Part 1: The Component Metadata Model. International Organization for Standardization.
- King, M., Ostojic, D. and Durco, M. (2015). Variability of the Facet Values in the VLO - a Case for Metadata Curation. CLARIN Annual Conference 2015 - Book of Abstracts. Wroclaw, Poland.
- Meertens Institute (2016). Search Resources and Tools at the Meertens Institute http://www.meertens.knaw.nl/cmdi/search (accessed 24 February 2016).
- Roorda, D. (2013). CorrespondenceHistorical https://catalog.clarin.eu/ds/ComponentRegistry/ - /?itemId=clarin.eu%3Acr1%3Ap_1360230992133®istrySpace=public (accessed 25 February 2016).
- Schuurman, I., Windhouwer, M., Ohren, O. and Zeman, D. (2015). CLARIN Concept Registry: the new semantic registry. CLARIN Annual Conference 2015 - Book of Abstracts. Wroclaw, Poland.
- The Language Archive (2016a). Arbil https://tla.mpi.nl/tools/tla-tools/arbil/ (accessed 24 February 2016).
- The Language Archive (2016b). FLAT https://github.com/TheLanguageArchive/FLAT (accessed 24 February 2016).
- The Language Archive (2016c). A Simple Java Application for Managing an OAI-PMH Harvesting Workflow https://github.com/TheLanguageArchive/oai-harvest-manager (accessed 24 February 2016).
- UFAL (2016). LINDAT/CLARIN Digital Repository Based on DSpace https://github.com/ufal/lindat-dspace (accessed 24 February 2016).