Authors: Thomas Koentges
Category: Paper:Short Paper
Keywords: Topic-modelling, Finding Aids, GLAM metadata organisation, Multilinguality, Morpho-syntactic normalization
Researchers to your Driving Seats: Building a Graphical User Interface for Multilingual Topic-Modelling in R with Shiny
In this paper I will showcase the results of topic-modelling research undertaken during my 2015 visiting fellowship at Victoria University Wellington (VUW), New Zealand. This research was undertaken in collaboration with staff at the Alexander Turnbull Library, National Library of New Zealand (ATL), and was subsequently applied to the Open Philology Project (OPP) in the Department of Digital Humanities at the University of Leipzig, Germany, and to Classical Persian corpora in collaboration with the Roshan Institute for Persian Studies at the University of Maryland (UMD), USA. The paper emphasizes how humanities researchers, even those who do not have deep scripting knowledge, can be enabled not only to understand, but also to modify the topic-modelling process, adapt it to their corpus- or language-specific needs, and then use the results of this process for further qualitative research. Topic-modelling in digital humanities research is a means to an end that should always help to answer a specific research question. In this way the paper follows an alternative route to previous interactive topic-modelling research, for example Hu et al. (2014) at the University of Maryland. Instead of asking how the method of topic-modelling can be improved by user-input, the author of this paper focuses on the ways in which we can improve the results of topic-modelling while also improving the humanities researcher’s understanding of the method and its variables.
After a brief introduction to the research projects in Wellington and Leipzig and to topic-modelling itself, the paper will summarize the limitations of topic-modelling with special emphasis on how to determine an ideal number of topics, as well as a short discussion of morphosyntactic normalization and the use of stop-words. It will then suggest a researcher-focused method of addressing these limitations and challenges in topic-modelling by introducing the Shiny topic-modelling application developed by the author based on R, Shiny, and J. Chang’s LDA library and C. Sievert’s LDAvis library. The paper will then briefly demonstrate the applicability to the different use-cases at ATL and OPP, which deal with very different fields and languages, including English, Latin, Ancient Greek, Classical Arabic and Persian. The paper will finish by stressing how digital humanities research results and practices can be improved by enabling humanities researchers who focus on more traditional and qualitative analyses of the corpora to use the quantitative method of topic-modelling as a macro-scope and faceting tool; effectively calling humanities researchers back to their driving seats.
During my research stay at VUW I worked with the Research Librarian for cartoons at ATL, Dr Melinda Johnston, on a mixed-methods-based analysis of the reactions of cartoonists and New Zealand print publications to the Canterbury Earthquakes in 2010 and 2011. ATL is part of the National Library of New Zealand, an institution that is interested in making the country’s cultural heritage more accessible to a digital audience and researchers. Within the short project I attempted to automatize the detection and analysis of cartoon descriptions created by ATL and over 100,000 abstracts produced by Index New Zealand (INNZ); all items were published between September 2010 and January 2014. The INNZ-data could be retrieved as a double-zipped XML file from INNZ’s webpage and ATL’s item descriptions could be queried using the Digital New Zealand (DNZ) API. During the project it became apparent how a topic-modelling approach, first applied by the author in VUW’s Digital Colenso project, could considerably speed up the finding of earthquake-related descriptions and abstracts.
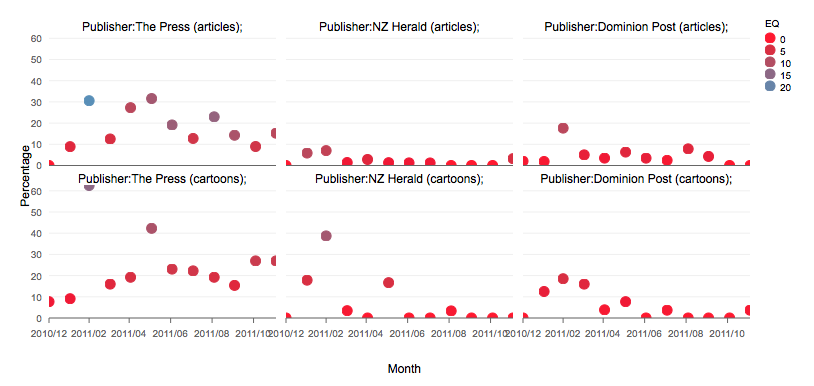
The results were so impressive (see e.g. Figure 1 and forthcoming article by Johnston, M. and Koentges, T. in Alexandria: The Journal of National and International Library and Information Issues) that the author decided to apply it to Latin and Greek literature in Leipzig’s OPP project. OPP has a text collection of over 60 million Greek and Latin words, and has recently begun to add Classical Persian and Arabic texts. It is one of the core interests of OPP to produce methods that can compete with more traditional approaches and that can swiftly generate results on big data. OPP is maintained and organized using eXistDB, the CTS/CITE-Architecture developed by the Homer Multitext Project, and additional web-based tools and services, including GitHub repositories and Morpheus, a Greek and Latin morpho-syntactic analyzer. This structure enables researchers to use a CTS-API to retrieve their desired text-corpora or specific texts. In a first evaluation run of the topic-modeller, 30,000 Classical Arabic biographies have been used (see Figure 2).
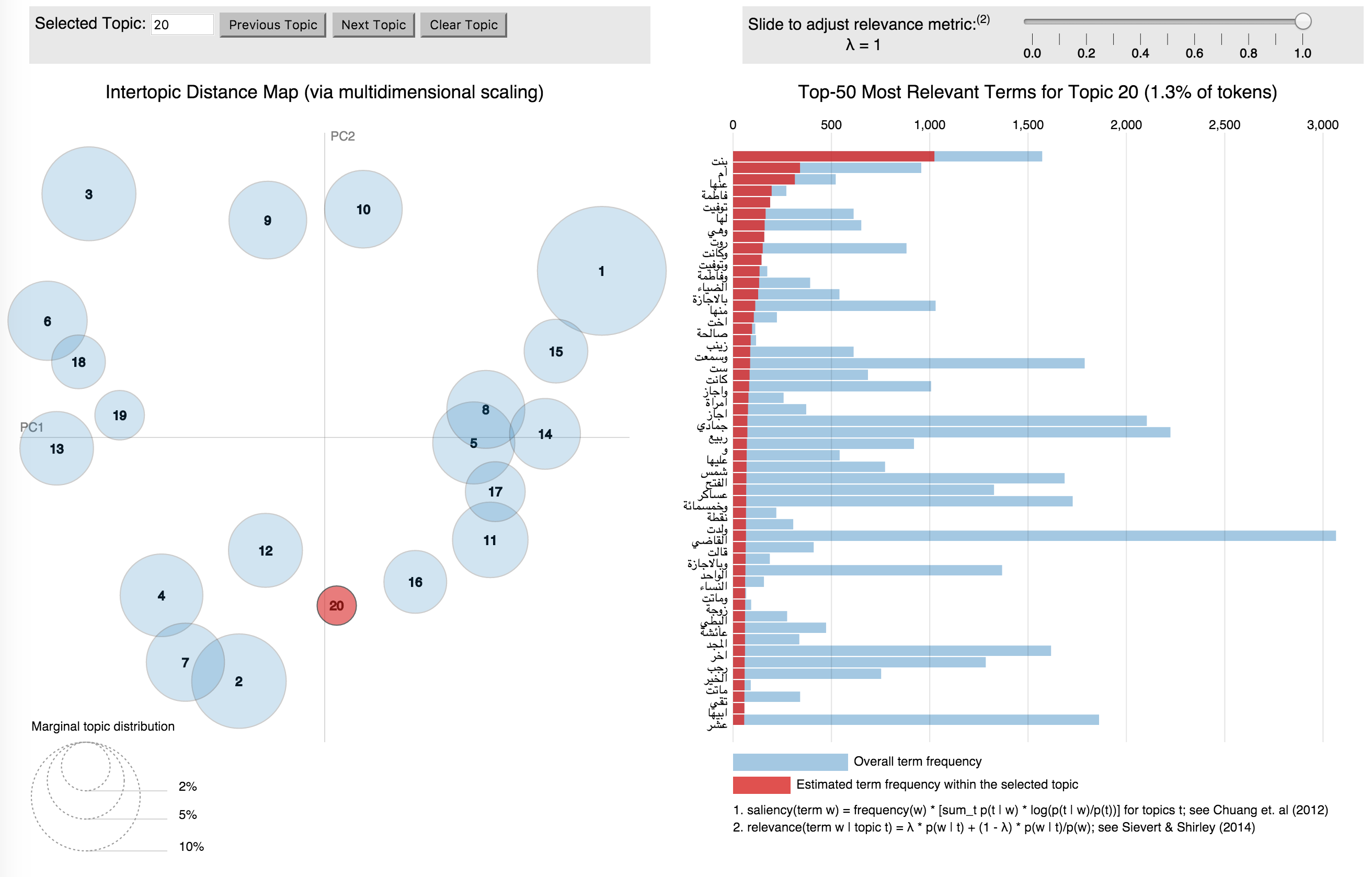
In both research institutions, OPP and ATL, researchers applying more qualitative methods complemented the process and evaluated results. In what follows the quantitative method topic-modelling will be explained briefly.
Topic-modelling is “a method for finding and tracing clusters of words (called “topics” in shorthand) in large bodies of texts” (M. Posner, 2012). A topic can be described as a recurring pattern of co-occurring words (M. Brett, 2012). Topic models are probabilistic models that are often based on the number of topics in the corpus being assumed and fixed (D. Bley, 2012). The simplest and probably one of the most frequently applied topic models is the latent Dirichlet allocation (LDA). Success and results of LDA rely on a number of apriori-set variables: for instance, the number of topics assumed in the corpus, the number of iterations of the modelling process, the decision for or against morpho-syntactic normalisation of the research corpus, and how stop-words are implemented in the process. Furthermore, its interpretation is often influenced by how the topics are graphically represented and how the words of each topic are displayed.
While Sievert has found already a very convincing solution for the latter (2014), the former is often out of the hands of the qualitative traditional researcher and any bigger modifications would have to be implemented by a computer-savy researcher. However, topic-modelling is often not an end in itself, rather it is a tool used to help answer a specific humanities research question or to facet large text-corpora so that further methods can be applied to a much smaller selection of texts. Traditional researchers often have to continue to work with topic-modelling results, but may not always be aware of the bias that the apriori-set variables have brought into the selection process. One possible way to bridge this gap between researcher and method is to involve the qualitative researcher earlier by providing them with agency in the topic-modelling process.
The author of this paper used R and the web-application framework Shiny to combine Chang’s LDA- and Sievert’s LDAvis-libraries with DNZ/CTS API requests and language-specific handling of the text data to create a graphical user interface (GUI) that enables researchers to find, topic-model, and browse texts in the collections of ATL, INNZ, OPP, and UMD. They can then export their produced corpus and model, so they can apply qualitative methods on a precise facet of a large text corpora, rather than the whole text corpora itself, which contains texts that are irrelevant for answering the researcher’s specific research question. On the left side of the GUI, the researcher can set the following variables: a) search term(s) or CTS-URN(s); b) the source-collection; c) certain stopword lists or processes; d) additional stop-words; e) the number of topics; and f) the number of terms shown for each topic in the visualization. The application then generates the necessary API-requests, normalizes the text as desired by the researcher, applies Chang’s LDA-library, and finally presents a D3 visualization of the topics, their relationship to each other, and their terms using Sievert’s LDAvis and dimension reduction via Jensen-Shannon Divergence & Principal Components as implemented in LDAvis. The researcher can then directly and visually evaluate the success of their topic-modelling and use the settings on the left like the settings of a microscope to focus on certain significant relationships of word co-occurrences within the corpus. Once they have focused their research tool, they can then export visualizations, topics, and their corpus for further research (see Figure 3) and teaching (see Figure 4).
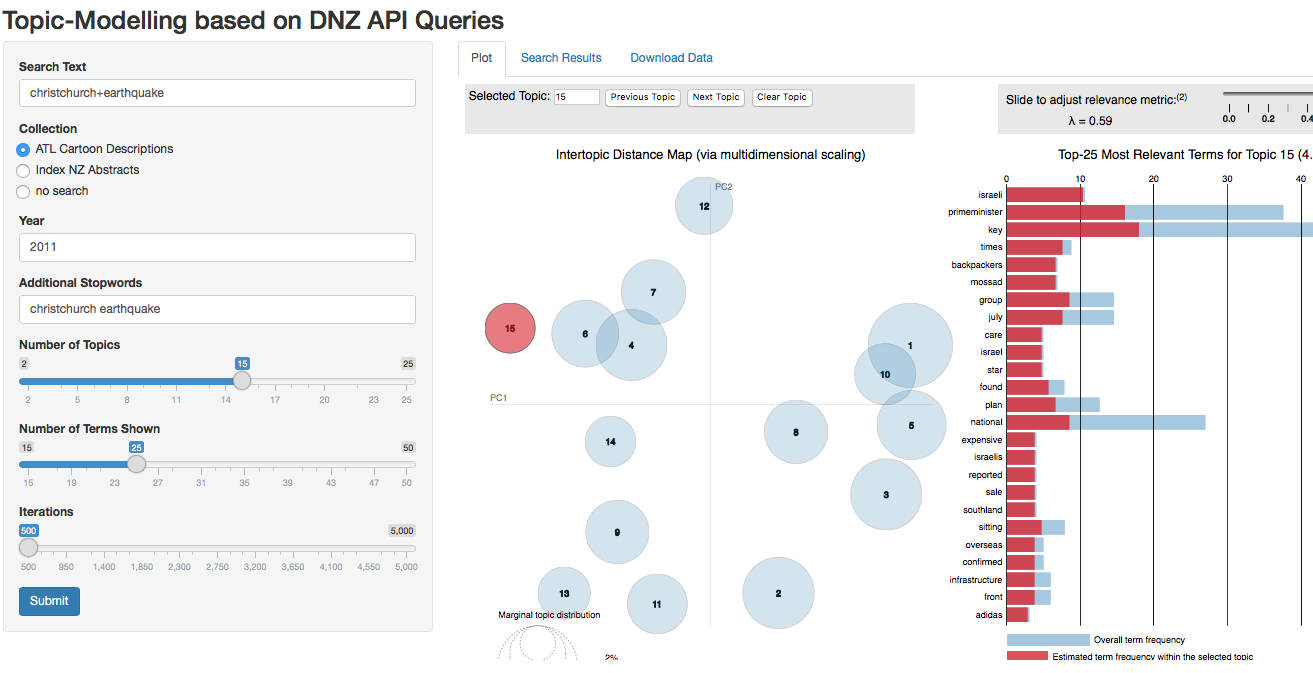
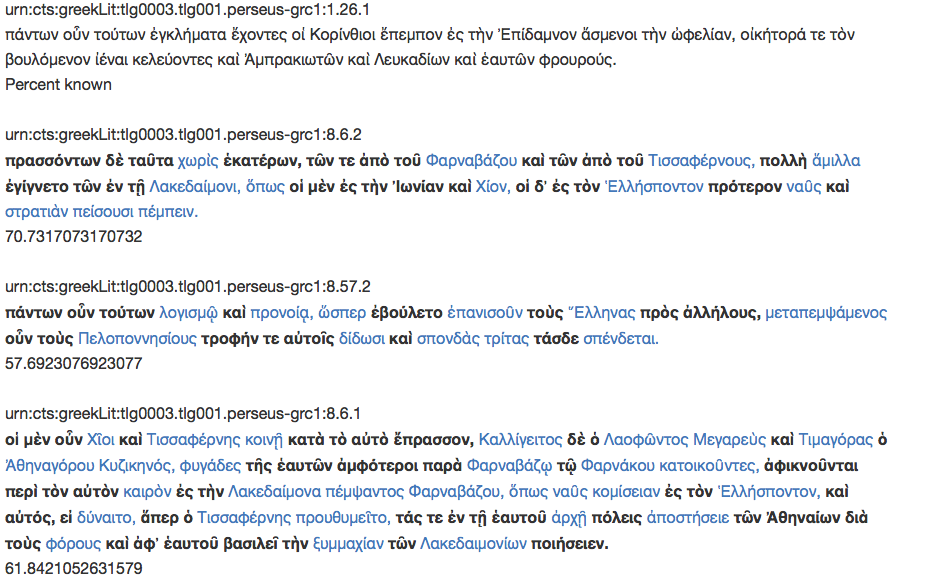
The approach also enables educators to use the topic-modelling results to identify sight-readings for language-teaching purposes. The passages are paired based on the profile of their document-topic values and Perseid’s Morpheus API is used to mark vocabulary not-yet-known by the learners. Unknown vocabulary links to an online dictionary, using markdown (see Figure 4).
The author hopes that this paper demonstrates how topic-modelling, in all its complexity, can be opened up to, and positively influenced by, more traditional researchers without advanced computer skills, enabling them to answer specific research questions based on large text corpora.
- Blei, D. (2012). “Probabilistic Topic Models.” Communications of the ACM, 55(4): 77–84. http://www.cs.princeton.edu/~blei/papers/Blei2012.pdf (accessed 30 October 2015).
- Hu, Y., Boyd-Graber J., Satinoff B. and Smith A. (2014). “Interactive topic modeling.” Machine Learning, 95(3): 423–69. http://www.umiacs.umd.edu/~jbg/docs/mlj_2013_itm.pdf (accessed 20 February 2015).
- Brett, M. (2012). “Topic Modeling: A Basic Introduction.” Journal of Digital Humanities, 2(1). http://journalofdigitalhumanities.org/2-1/topic-modeling-a-basic-introduction-by-megan-r-brett/ (accessed 30 October 2015).
- Posner, M. (2012). “Very Basic Strategies for Interpreting Results from the Topic Modeling Tool.” http://miriamposner.com/blog/very-basic-strategies-for-interpreting-results-from-the-topic-modeling-tool/ (accessed 30 October 2015).
- Sievert, C. and Shirley, K. (2014). LDAvis: A Method for Visualizing and Interpreting Topics, ACL Workshop on Interactive Language Learning, Visualization, and Interfaces. http://nlp.stanford.edu/events/illvi2014/papers/sievert-illvi2014.pdf (accessed 30 October 2015).