Authors: Han Sloetjes, Olaf Seibert
Category: Paper:Poster
Keywords: annotation, multimedia, commentary framework, semi-automatic annotation
New Facets Of The Multimedia Annotation Tool ELAN
1. Introduction
ELAN is a multimedia annotation tool that is being developed by “The Language Archive” (https://tla.mpi.nl), a department of the Max Planck Institute for Psycholinguistics. It is applied in a variety of research areas within the humanities and beyond; it can be useful in any type of research that includes audio and/or video recordings and analyzes these qualitatively or quantitatively (or both). A general comparison of characteristics of this and other, similar tools can be found in the report of a workshop organized at a gesture conference in Lyon (Rohlfing et al., 2006). This poster with demo is intended as a general introduction to its main functionalities, with an emphasis on the latest developments. Most of these new developments have been executed within CLARIN (Common Language Resources and Technology Infrastructure, http://clarin.eu) projects in the Netherlands and in Germany.
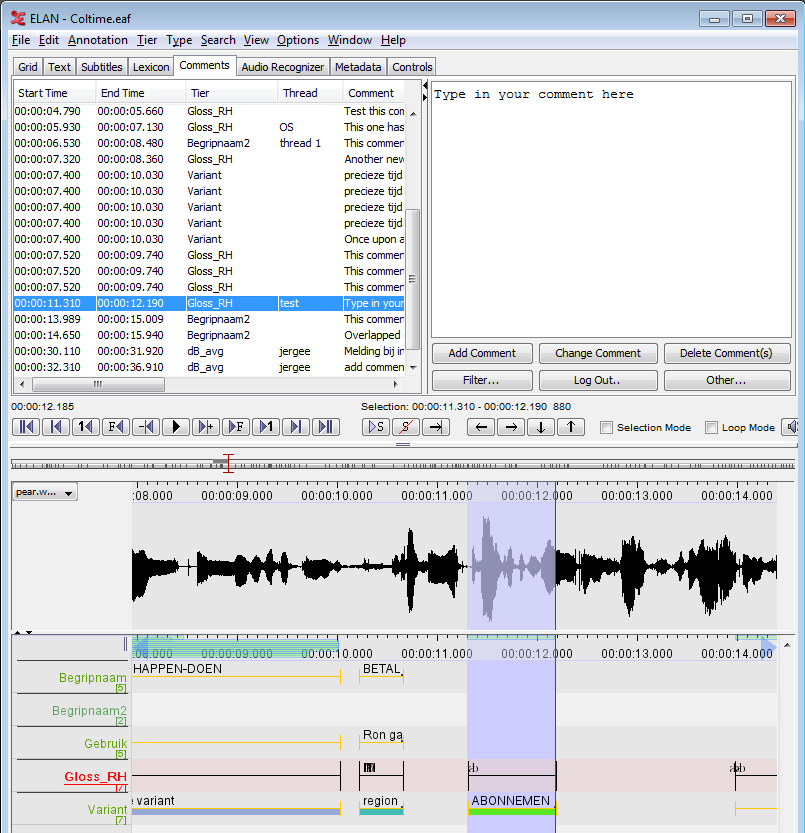
2. Adding and sharing comments
One of the new developments concerns a commentary framework that improves collaboration of annotators working in a team setting. Comments are pieces of text linked to a segment of the media and possibly to a tier (a tier is an annotation layer). They can be used to store notes, remarks or questions concerning a fragment for later use or for discussion with a colleague. Much alike the way comments in word processors are used. The comments can be shared via email, a file sharing (cloud) service (such as Dropbox) and/or via the back-end of the DASISH Web Annotator (DWAN, http://dasish.eu), a web service for storing annotations (comments) to online content (e.g. web pages). Comments can sometimes be annotations on annotations, but their content and purpose are usually not obvious parts of a (final version of a) transcription.
Another recent development is the possibility to associate parts of a transcription to a language identifier (e.g. ISO 639-1/3 code, http://www.iso.org/iso/home/standards/language_codes.htm) in an explicit way. Among these parts are tiers, entries in a controlled vocabulary and individual annotations. The language attribute of tiers can be used for selecting or sorting tiers in the user interface, when exporting or searching.
3. Connecting to web services
A preliminary implementation of interaction with WebLicht web services (Hinrichs et al., 2010) was presented at the Digital Humanities conference in 2013. Since then this implementation has been modified and updated in several ways. The address of the services called by ELAN are no longer hard wired but instead the user can select a service (representing a parser or tagger etc.) from a list that is obtained from the WebLicht framework itself. The features mentioned above more tightly embed ELAN in the CLARIN world.
4. Interrater agreement
Other important changes are the new functions for assessing interrater reliability. For many annotation tasks it is important to have an idea of how well annotators are instructed, to what extent annotators agree in their observations and how consistent these are. A simple comparison method solely based on extent and overlap of co-occurring annotations on tiers of two annotators is now complemented by two third party algorithms that take chance agreement into account. One calculates a Cohen’s kappa value by first applying a matching algorithm to the segmentations created by two raters (Holle and Rein, 2015). The other calculates a degree of organization by applying Monte Carlo Simulations to segmentations produced by multiple raters (Lücking et al., 2011). It is now possible to perform agreement calculations for an entire corpus, where the user can specify which tiers (i.e. which types of events) need to be assessed.
5. Automatic segmentation and labelling
ELAN allows to create annotations manually, which means that the user can inspect the media stream, identify relevant segments and create annotations using the mouse and/or the keyboard. We have been involved in several projects that aim at integration of tools for semi-automatic segmentation and labelling of the media. A first version was presented in 2013; within the AUVIS (https://tla.mpi.nl/projects_info/auvis/) project the algorithms have been improved and the user interface further streamlined. Information technology experts specialized in analyses of digital video streams closely collaborated with gesture researchers to improve the algorithms for automatic gesture detection and categorization (Schreer et al., 2014) while specialist in speech recognition cooperated with language documentation scientists on better algorithms for speech segmentation and speaker diarization (Rieber and Bardeli, 2013). Although the automatically created segmentation is often not accurate enough to completely replace manually created annotations, these technologies can already be applied in a scenario in which the automatic approach creates the segmentation which is then manually corrected.
- Hinrichs, M., Zastrow, T. and Hinrichs, E. (2010). WebLicht: Web-based LRT Services in a Distributed eScience Infrastructure. In Proceedings of the Seventh International Conference on Language Resources and Evaluation, LREC 2010. Valletta, Malta, pp. 489-93.
- Holle, H. and Rein, R. (2014). EasyDIAg: A tool for easy determination of interrater agreement. Behavior Research Methods, 47(3): 837-47.
- Lücking, A., Ptock, S. and Bergmann, K. (2011). Staccato: Segmentation Agreement Calculator. In Proceedings of the 9th International Gesture Workshop, May 25-27, 2011. Athens, Greece, pp. 50-53.
- Rieber, J. and Bardeli, R. (2013). Speech Recognition as a Retrieval Problem. Lecture Notes in Informatics, 220: 2958-71.
- Rohlfing, K., Loehr, D., Duncan, S., Brown, A., Franklin, A., Kimbara, I., Milde, J.-T., Parrill, F., Rose, T., Schmidt, T., Sloetjes, H., Thies, A. and Wellinghof, S. (2006). Comparison of multimodal annotation tools - workshop report. Gesprächforschung - Online-Zeitschrift zur Verbalen Interaktion, 7: 99-123.
- Schreer, O., Masneri, S., Lausberg, H. and Skomroch, H. (2014). Coding Hand Movement Behavior and Gesture with NEUROGES Supported by Automatic Video Analysis. In Proceedings of Measuring Behavior 2014, August 27-19, Wageningen, The Netherlands.