Authors: Giovanni Moretti, Sara Tonelli, Stefano Menini
Category: Paper:Short Paper
Keywords: persons' network, network extraction, network visualisation
Building Large Persons’ Networks to Explore Digital Corpora
1. Introduction
Although representing large corpora through the network of persons’ interactions has become quite popular in the Digital Humanities community (Elson et al., 2010), several parameters can have an impact on the resulting network, especially when it is automatically extracted. In this work, we present a step-by-step procedure to extract persons’ networks from documents and select possible configurations in order to increase readability and ease the interpretation of the obtained information. We also discuss some open issues of the task.
We rely on the same assumption as for word co-occurrence networks: two persons who tend to be mentioned together in a corpus share some commonality or relation from the author’s perspective.
2. The Methodology
We implemented a novel tool for the automated extraction of a persons’ network from a corpus in the online ALCIDE platform1 (Moretti et al., 2014). The module is based on the following steps: i) the corpus is first analysed with the Stanford named entity recognizer (Finkel et al., 2005), in order to recognize persons’ mentions (e.g. John Kennedy, F.D. >Roosevelt, etc.). In the network representation, we assume that persons correspond to nodes and edges express co-occurrence within a given token window; ii) We build a person-person matrix where we assign an edge weight of 1 every time two persons are mentioned together within a certain context window. Every time a co-occurrence is repeated, the weight is increased by 1; iii) The final output is a weighted undirected network where edge weights are the co-occurrence frequency. In the default configuration, name mentions are collapsed onto the same network node only if they have an exact match. In order to allow a more flexible creation of the network, a “Person Management” functionality (Fig. 1) has been implemented, through which users can collapse nodes referring to the same person (e.g. J.F. Kennedy and John Kennedy). This manual check is done through an interface, without the need to access directly the underlying matrix.
From a technical point of view, the information is stored in a relational database management system, in order to grant multi-user access, good performances and high flexibility regarding the queries. The persons’ co-occurrence matrix is visualized as a network by means of the d3 javascript framework2. During the conversion of the matrix in the json used by d3, the nodes are enriched with additional information, such as the list of documents containing the corresponding entity and the number of connections.
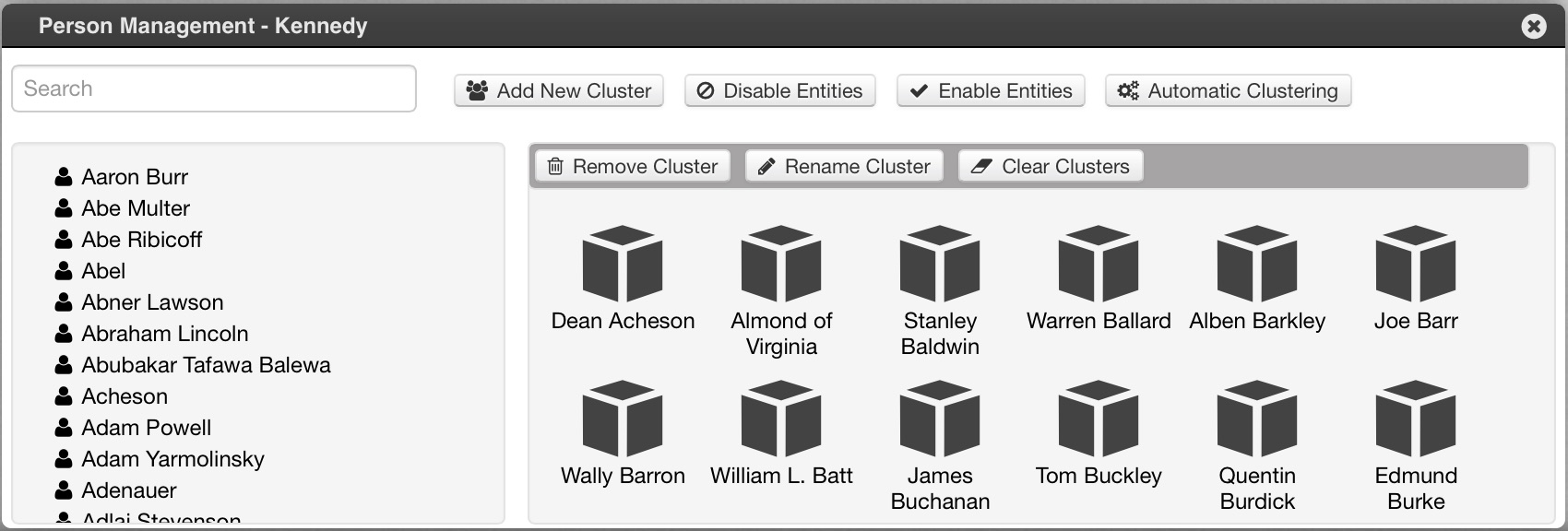
Some settings such as the co-occurrence window type (sentence or token) and width (number of sentences/tokens) are arbitrary, although they have a relevant impact on the extracted network and on its readability. Therefore, the system gives the possibility to change such settings and regenerate the co-occurrence matrix at runtime. In the following sections we will discuss some of these parameters and explain their impact in the light of a use case related to Nixon and Kennedy’s speeches of the 1960 presidential campaign. The corpus consists of 282 documents by Nixon (830,000 tokens) and 598 documents by Kennedy (815,000 tokens) 3. All networks displayed in the following sections are screenshots of the system output and are dynamically displayed.
2.1. Default configuration
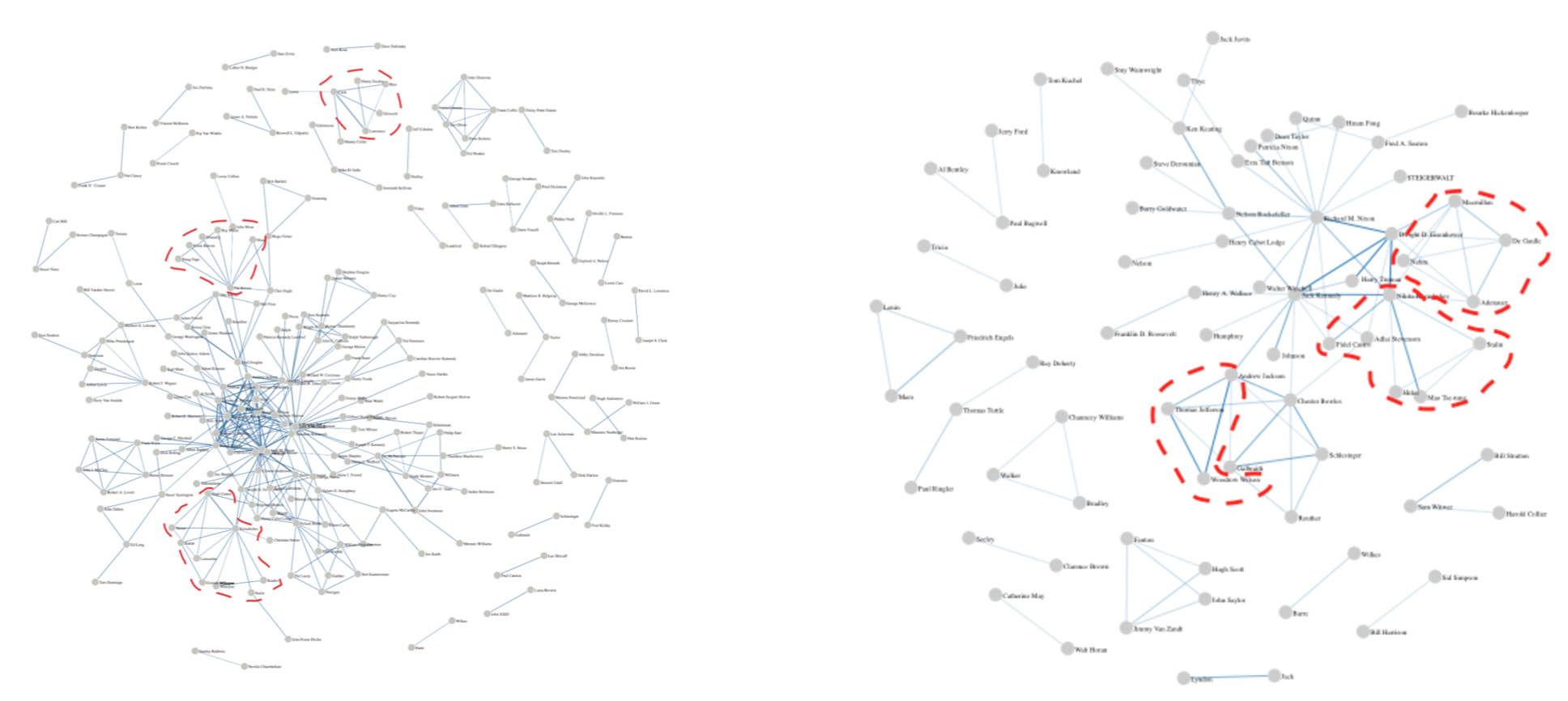
In our default configuration, the tool extracts persons’ networks using 1 sentence as a co-occurrence window and collapsing on the same node only name mentions with an exact match. As shown in Fig.2, this basic configuration is enough to highlight the differences between Kennedy’s and Nixon’s networks: the first is much larger and much more connected, with several cliques that tend to emerge from the overall picture. Nixon’s network, instead, is smaller (i.e. less persons are mentioned in his corpus) and less dense.
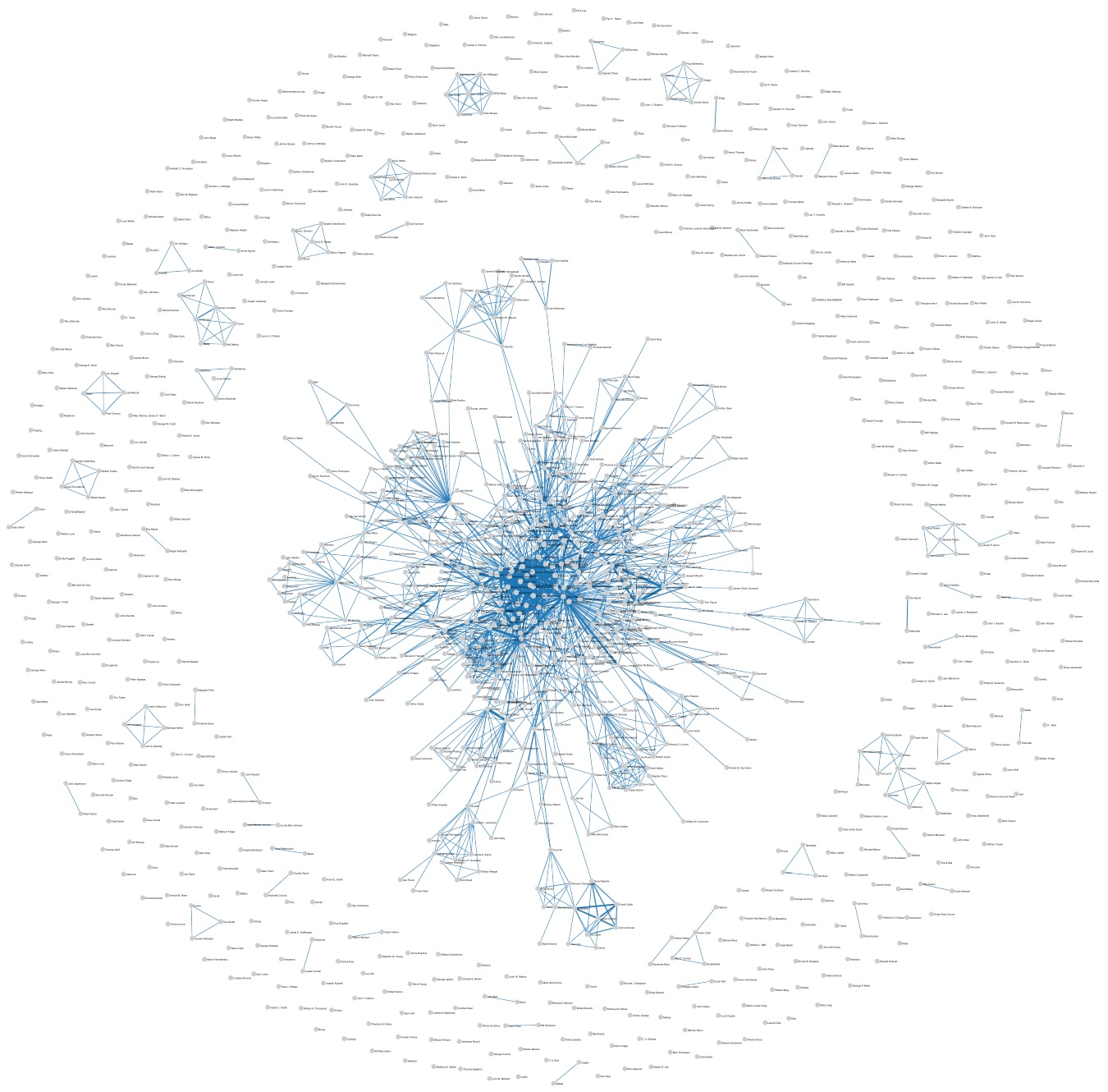
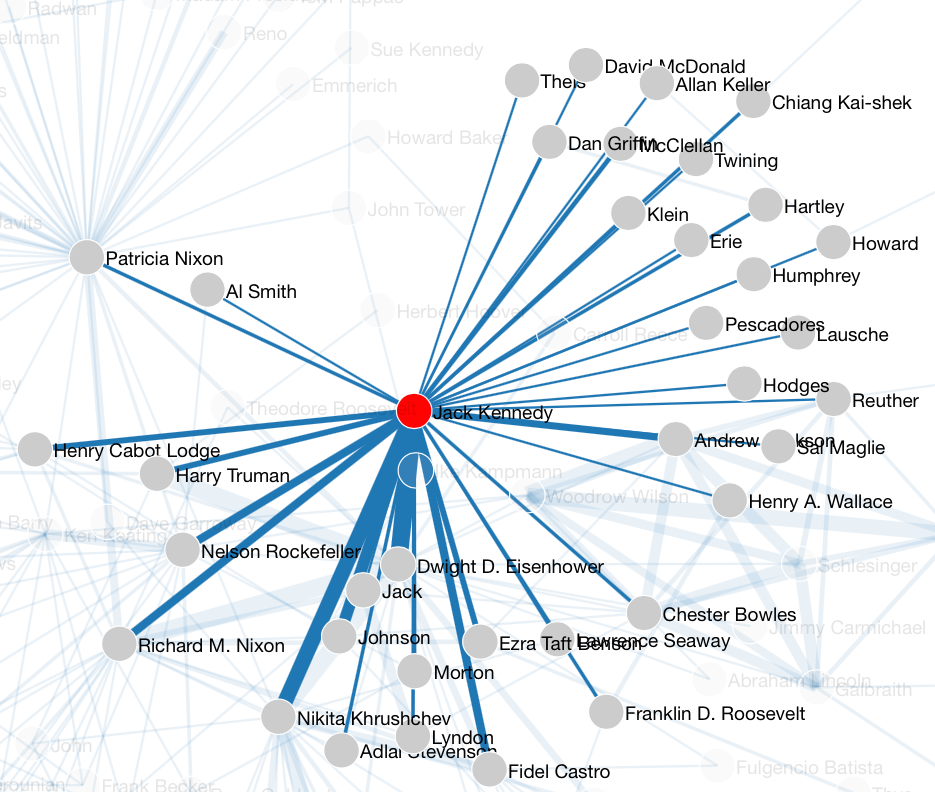
By zooming in the pictures, it is possible to focus on single nodes of interest. For example, if we compare Nixon’s mentions appearing in Kennedy’s speeches, and the other way round (Fig. 3, left and right resp.), we observe that in both cases the opponent is frequently mentioned with ‘enemies’ of the time such as Fidel Castro and Khrushchev. However, this association with negative figures is much more frequent in Kennedy’s speeches (e.g. Nixon is mentioned also with Trotsky and Lenin), probably because Nixon had already a prominent role in US foreign policy being Vice-President.
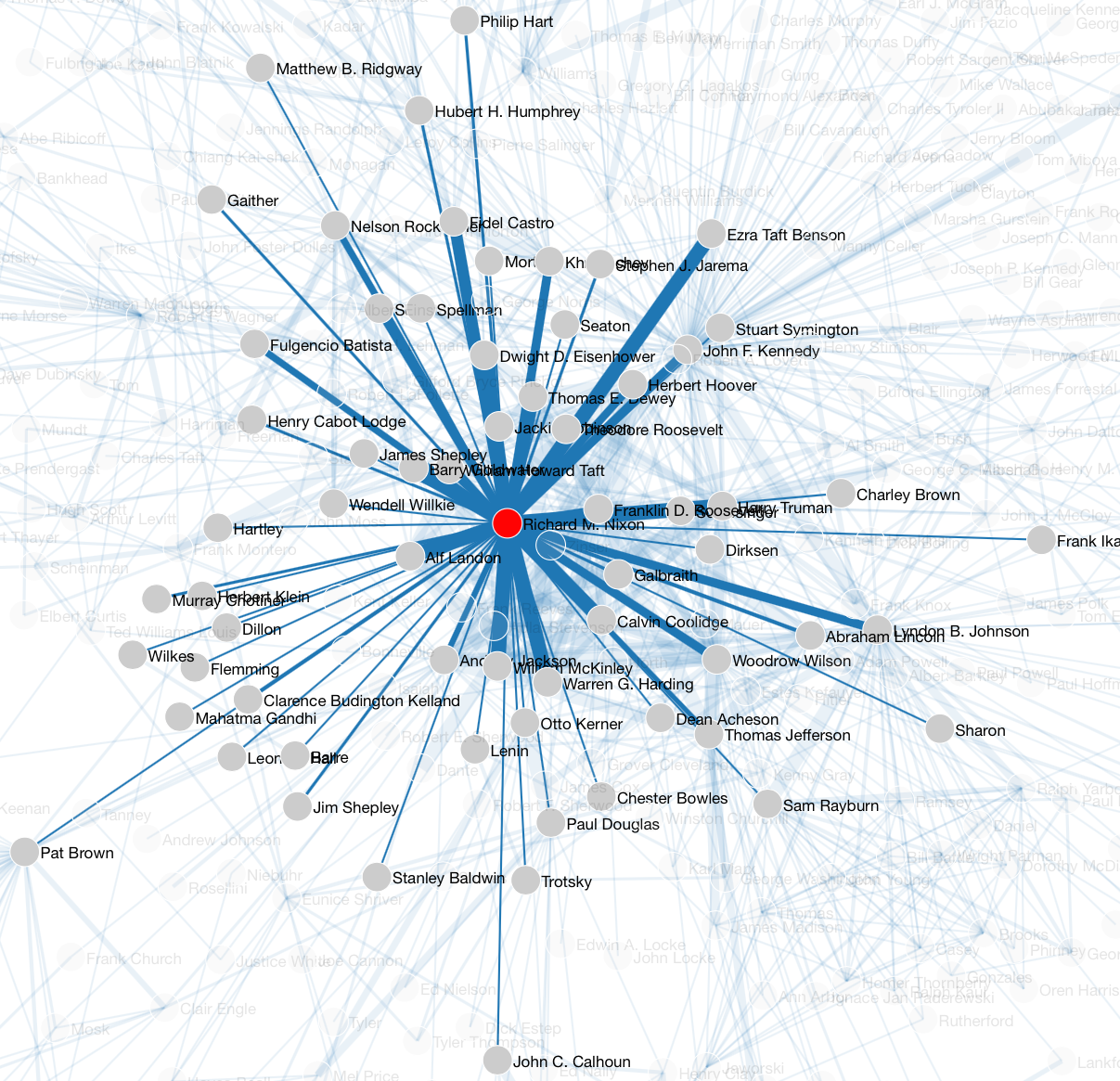
2.2. Changing configuration parameters
The tool allows users to move from the default configuration to a more customizable one, where it is possible to change the type (sentence or token) and the size of the context window taken into account for the co-occurrences as well as set a threshold to the edges’ weight (number of co-occurrences). By tuning these parameters, it is possible to transform the networks presented in Fig. 2 to obtain a more readable representation, filtering minor nodes and emphasizing information previously hidden by the large amount of information.
Reducing the co-occurrence window increases the probability to extract persons that are more strictly related. At the same time, by increasing the minimum edge weight threshold, we reduce the information visualized, filtering out all the persons co-occurring only once in favour of persons co-occurring consistently through the entire corpus.
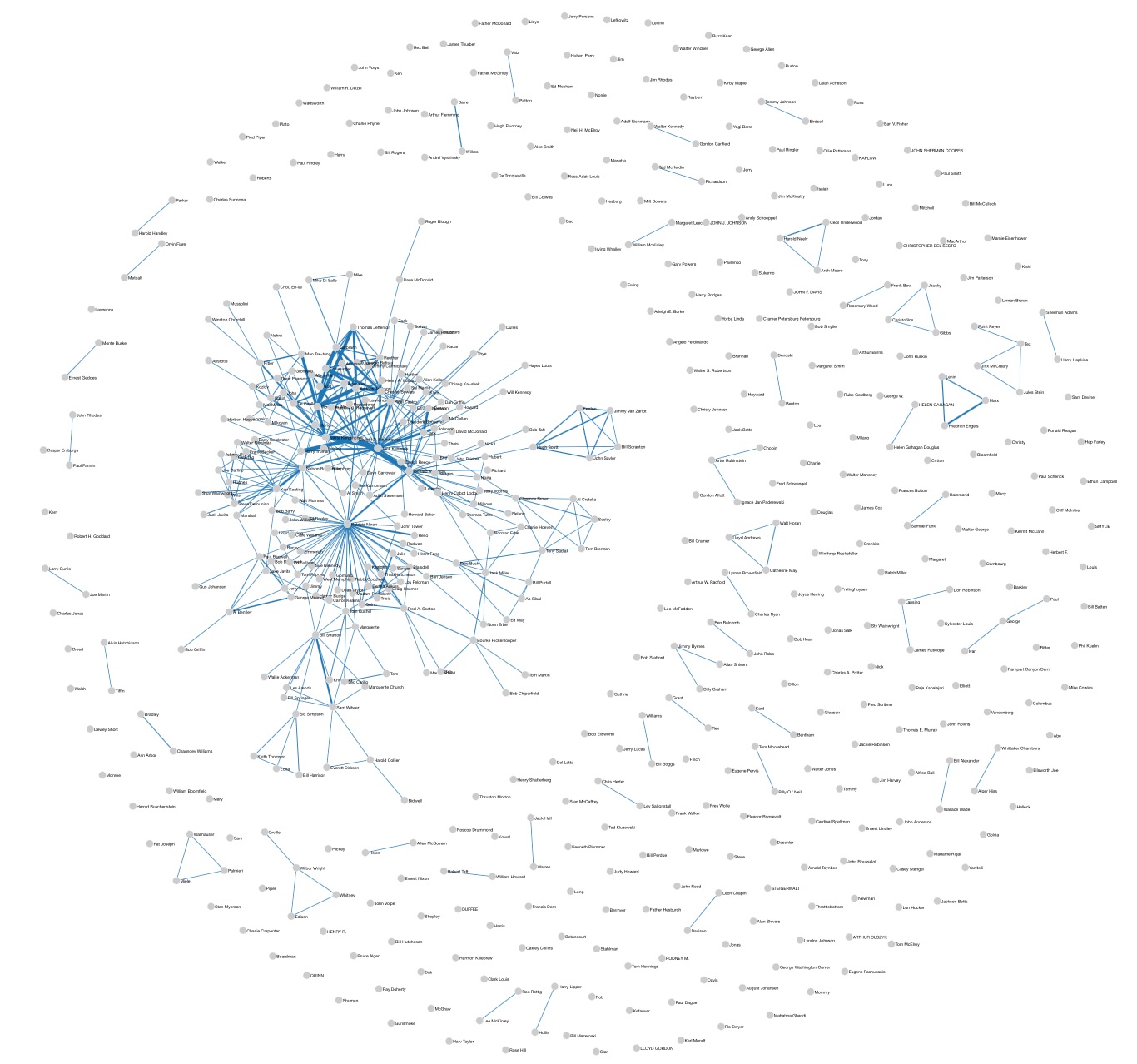
Fig. 4 shows the networks, obtained from the data in Fig. 2, generated by setting the maximum token range to 10 (thus, on average, less than the sentence length adopted in Fig. 2) and the minimum edge threshold to 2. The result is a visualization with less but more readable data. In Nixon’s network, we can easily spot some well-defined clusters such as the one grouping the leaders of the communist world (i.e Khrushchev, Stalin, Mao Tse-tung), the cluster of the main representatives of international politics in 1960 (e.g. de Gaulle, Nehru, Adenauer) or a cluster reflecting Nixon’s attitude to refer to previous U.S. Presidents (e.g Andrew Jackson, Thomas Jefferson). Also the network from Kennedy’s corpus is more understandable, including a cluster with prominent Communist politicians (e.g. Khrushchev, Castro, Kadar), but also clusters defining local democratic representatives, for instance those from California (e.g. Pat Brown, John Moss) or those from Pennsylvania (e.g. David Leo Lawrence, Joseph S. Clark).
3. Discussion
As shown in the above examples, building a persons’ network in an automated fashion implies making some a-priori choices that strongly affect the outcome of the analysis. Such choices are influenced by the type of analysis required by the user. If distant reading is the main goal, the parameters proposed as default by our tool, as shown in Fig. 2, seem to be appropriate. This analysis gives an overview of the overall network dimension and density, and makes it possible to compare two networks at a glance. Instead, if close reading and a qualitative analysis of the connections are more relevant, reducing the window width and displaying only the most connected nodes is necessary. Since in a typical research scenario distant and close reading are both present, and users need to zoom in and out frequently, a tool that changes the network on demand in real time should be implemented. In this respect, Gephi (Bastian et al., 2009), probably the most widely used tool for network analysis in the Digital Humanities community, shows some limitations. Although it provides useful in-built metrics for analysing a network structure, it does not offer the possibility to test different parameters on the fly. Also its integration in an online, browser-based environment is quite complex, as well as the connection to a text analysis pipeline.
Other issues related to the automated creation of persons’ networks are worth mentioning. Since natural language processing tools are involved in the pre-processing step, users should be aware of the possible mistakes introduced by this pipeline. In particular, Named Entity Recognizers may label as persons other types of entities, wrongly introducing nodes in the network. Other possible mistakes are more difficult to spot and concern homonyms (i.e. nodes that should be split). Such cases can be solved only resorting to a cross-document entity coreference system, where mentions can be resolved by linking them to the entities they refer to. A finer-grained outcome could be achieved integrating also an intra-document coreference system, able to link mentions referring to the same person in a text. Cross- and intra-document coreference would be necessary to ensure that all persons mentioned in a corpus are included in the extracted network. Nevertheless, the impact of automated processing on the quality of the network needs to be further investigated.
- Bastian M., Heymann S. and Jacomy M. (2009). Gephi: an open source software for exploring and manipulating networks. International AAAI Conference on Weblogs and Social Media (ICWSM).
- Elson, D. K., Dames, N. and McKeown, K. R. (2010). Extracting Social Networks from Literary Fiction. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics (ACL 2010), Uppsala, Sweden.
- Finkel J.-R., Grenager T. and Manning, Ch. (2005). Incorporating Non-local Information into Information Extraction Systems by Gibbs Sampling. Proceedings of the 43nd Annual Meeting of the Association for Computational Linguistics (ACL 2005), pp. 363-70.
- Moretti G., Tonelli S., Menini S. and Sprugnoli R. (2014). ALCIDE: An online platform for the Analysis of Language and Content in a Digital Environment. In Proceedings of the First Italian Conference on Computational Linguistics (CLIC-2014), Pisa, Italy.