Authors: Peter Organisciak, Sayan Bhattacharyya, Loretta Auvil, Leena Unnikrishnan, Benjamin Schmidt, Muhammad Saad Shamim, Robert McDonald, J. Stephen Downie, Erez Lieberman Aiden
Category: Paper:Poster
Keywords: text analysis, visualization, scholarly curation
Adding Flexibility to Large-Scale Text Visualization with HathiTrust+Bookworm
The HathiTrust holds one of the largest collections of digitized published work in the world. With nearly 14 million volumes ("Currently Digitized", HathiTrust.org), it is a challenge to create mechanisms to understand and interpret a collection of this size. The HathiTrust+Bookworm (HT+BW) project presents ways to behold that textual content through interactive visualization. In this poster, we present new work from HT+BW in applying visualization as an complementary, rather than center, tool for supporting better comprehension of large collections. Whereas HT+BW has previously been used in standalone contexts with pre-determined metadata, we present work in two new areas: 1) allowing scholars to analyze custom personal collections from within the larger corpus; and 2) use of HT+BW as a supplement to other uses of the HathiTrust Research Center.
1. Context
The vanguard of big text data was the realization that we had more books than a person can read in a lifetime (Crane, 2006). At the scale of current collections, such as that of the HathiTrust, it would take many years to read only the titles of all the digitized works. Such a scale presents opportunities for new forms of inference about historical, cultural, and linguistic trends. However, because of the necessary abstractions away from qualitative reading to quantifiable features in these texts, the underlying biases of the collection are not always apparent to a scholar. HT+BW seeks to address such problems.
HathiTrust+Bookworm (HT+BW) is a project seeking to adapt the generalized analytic tool Bookworm (http://bookworm.culturomics.org) to the large scales and unique needs in the HathiTrust Research Center. The HathiTrust is a consortium of institutions collecting millions of digitized works, and its research center seeks to support scholars in the large-scale insights that such a collection can accommodate. HT+BW is built on the HathiTrust Research Center's Extracted Features Dataset (Capitanu et al., 2015), a publicly-released dataset of page-level counts for important features, such as text frequencies. The dataset contains nearly 8 terabytes of data for 1.8 billion pages across 4.8 million books, with plans to grow three-fold in 2016.
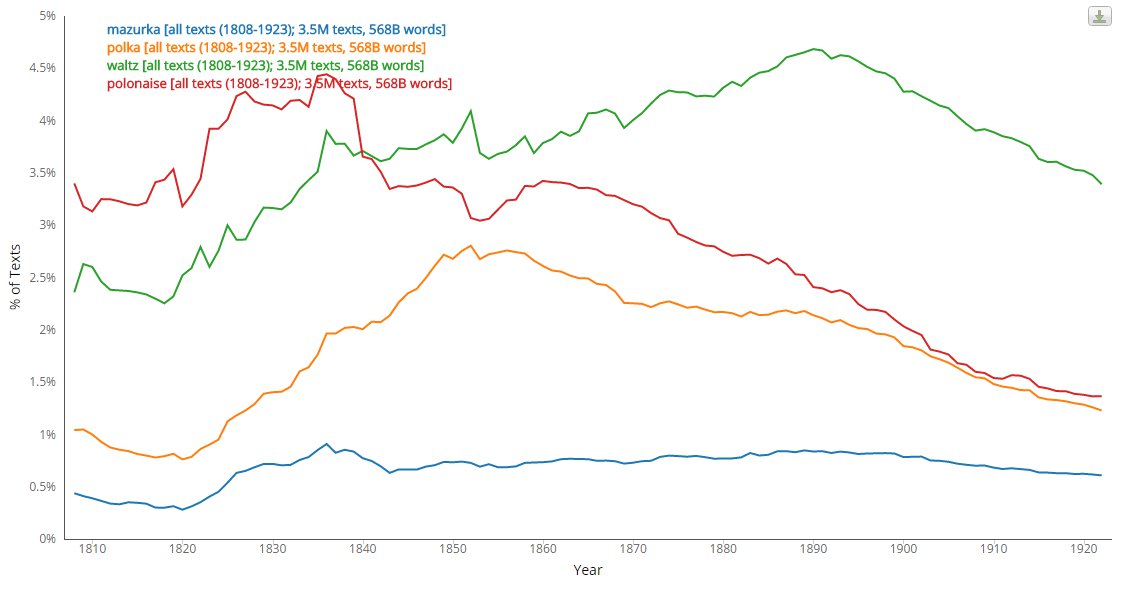
Figure 1: Comparing multiple topics over all texts
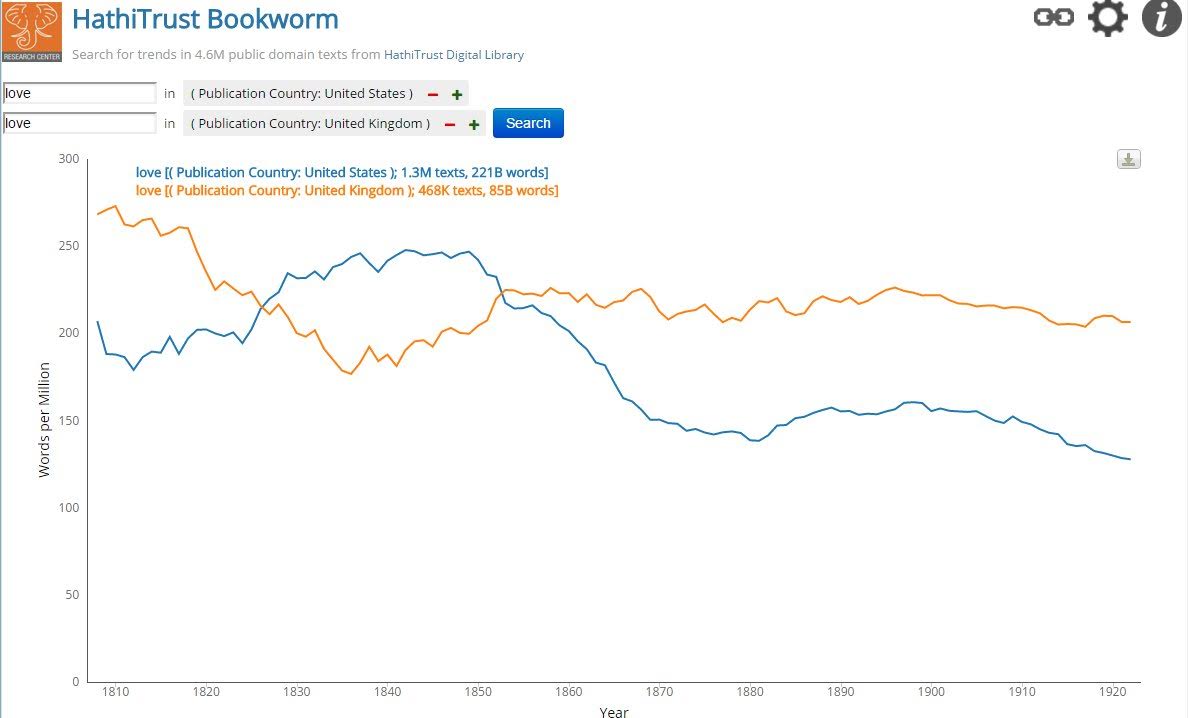
Figure 2: Comparing a single topic in multiple facets of the collections (US-published and UK-published books)
2. Approach
The strength of HT+BW is in detailed querying and faceting. In contrast to the Google Ngrams Viewer, for instance, scholars do not have to compare term usage across the entire corpus. Rather, they can peer within highly particular facets; for example, one can visualize longitudinal trends for the word “love” for only those books that were both published in the US and classified as literature (Figure 2). This ability becomes much more valuable when comparing across different facets, so that the usage trend of “love” can be compared between literature and general non-fiction works.
Our current work extends faceting to custom groupings of the collection — personal subsets called worksets — in the Hathitrust Research Center (Jett, 2015). Worksets can be visualized in Bookworm in a manner similar to visualizing any predetermined metadata-based facet. The affordances this allows include:
- generating descriptive statistics for a particular research domain, such as late 19th century best-sellers;
- creating two worksets, one of early-career and one of late-career authors, and comparing how theme words occur in either case; or
- using HT+BW over a collection derived from other scholarship, such as (Ted Underwood's fiction data).
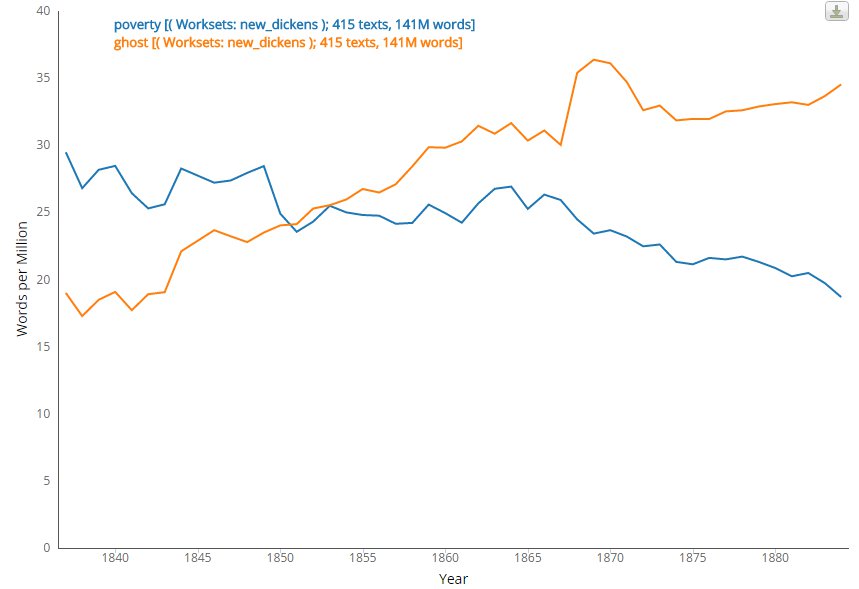
Figure 3: Comparing terms used in a 2000-volume scholar curated workset
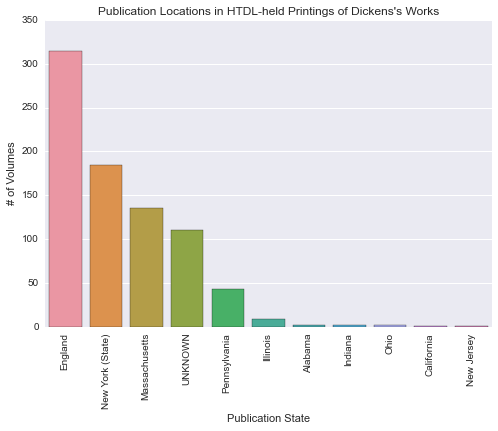
Figure 4: Comparing facet counts for “publication state” within a workset, using HT+BW public API.
In addition to workset access, HT+BW is being used for “widget” access to support other activities within the broader HathiTrust Research Center. Most importantly, this includes search. When searching for individual works, or building a workset, it is not immediately clear what relationship the relevant results have to the underlying contours of the dataset. For example, the widget-style visualization of a researcher’s query for “Beijing” or “Istanbul” would reveal that those terms are biased toward 20th century work (as these places were earlier referred to by other names).
The primary development challenge of the HT+BW has been the technical hurdles inherent to the scale of the HathiTrust’s collection. We have improved the ingest process for Bookworm to allow for lower level optimizations, a gain applicable to other projects' use of Bookworm. Query performance is robust at the scale of unigrams for 4.8 million volumes, though it remains to be seen how this will be scaled to larger n-grams and more volumes.
3. Conclusion
The HT+BW project is providing richer, more flexible access to the large holdings of the HathiTrust Digital Library, with a goal of supporting humanists in probing questions about historical, literary, or cultural trends in published literature.
4. Notes
HT+BW is supporting the development of Bookworm as a standalone, collection-agnostic tool. Our technical contributions are available at https://github.com/Bookworm-project and https://github.com/htrc. HT+BW is built upon publicly-available data from the HathiTrust Digital Library ( https://sharc.hathitrust.org/features) and metadata ( https://www.hathitrust.org/hathifiles).
HT+BW is supported by NEH Implementation Grant HK-50176-14. Any views, findings, conclusions, or recommendations do not necessarily reflect those of the National Endowment for the Humanities.
- Currently Digitized. Hathitrust Digital Library. http://hathitrust.org/about.
- Bookworm. Culturomics. http://bookworm.culturomics.org.
- Boris, C., Underwood, T., Organisciak, P., Bhattacharyya, S., Auvil, L., Fallaw, C. and Downie, J. S. (2015).Extracted Feature Dataset from 4.8 Million HathiTrust Digital Library Public Domain Vol. 2, [Dataset]. HathiTrust Research Center, doi:10.13012/j8td9v7m.
- Crane, G. (2006). What Do You Do with a Million Books?, D-Lib Magazine, 12(3). doi:10.1045/march2006-crane.
- Jett, J. (2015). Modeling Worksets in the HathiTrust Research Center. CIRSS Technical Report WCSA0715. Champaign, IL: University of Illinois at Urbana-Champaign.