Authors: Paul J. Fields, Larry W. Bassist, Matthew R. Roper
Category: Paper:Short Paper
Keywords: Stepwise Discriminant Analysis, Most Distinguishing Words, Most Frequent Words, Power, Sensitivity
Choosing Words for Stylometric Authorship Attribution Evaluating Most Distinguishing Words (MDWs) vs. Most Frequent Words (MFWs)
1. Introduction
The results of stylometric authorship attribution studies are strongly influenced by four choices:
- Candidate Authors – The choice of candidate authors should be based on the historical context of the texts to be attributed.
- Representative Texts – Representative texts should be chosen that are similar in genre, topic and time frame as the texts to be attributed (Argamon et al, 2003; Stamatatos, 2009).
- Analytical Method – Many analytical methods are available. Burrows’ Delta is often considered to be the ‘gold standard’ to compare other methods (Burrows, 2002).
- Distinguishing Features – One list of features to distinguish among candidate authors can provide greater distinguishing power than another list of features. This paper is about identifying the most distinguishing list.
Grammatical function words are used by all authors, but authors do not use function words in the same way or with the same frequencies. Therefore, different usage frequencies for function words are useful in characterizing an author’s writing style. Although the specific function words that are distinguishing among authors vary from study to study, their effectiveness as features to set apart an author’s writing style is well established (Mosteller and Wallace, 2007; Holmes, 1998).
Discriminant analysis is a statistical technique to classify objects into known categories based on a set of features about those objects. The technique was developed by Sir Ronald Fisher, a botanist. He illustrated the technique by classifying iris flowers into three species using four features – the length and width of sepals and petals (Fisher, 1936).
The approach is to compute linear combinations of the features that best separate the categories from each other. The most distinguishing combination of features is called the first linear discriminant function (LD1). Additional combinations (LD2, LD3 and so on) are computed that are orthogonal to each other to maximize the separation among categories. After computing the discriminant functions using a training set of data for objects with known classification, the discriminant functions can be used to classify objects of unknown classification into the categories to which they most likely belong.
The discriminant analysis concept is illustrated in figure 1 for a two-category problem and two dimensions. Each ellipse in the graph encircles the items within a category. LD1 shows the direction of greatest separation between the two categories. Discriminant analysis can be extended to classification problems with any number of categories and dimensions.
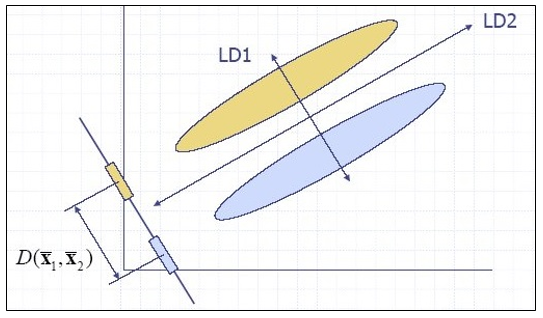
Discriminant analysis can be used in authorship attribution since the problem is similar to that of classifying plants into species based on their physical features. In attribution, the process is to use a set of texts of known authorship to determine the discriminant functions using non-contextual words as the features, and then classify texts of unknown authorship into the set of authors using the discriminant functions.
A variation of discriminant analysis called stepwise discriminant analysis (SDA) first determines a subset of the most distinguishing features from a comprehensive list of features and then formulates the discriminant functions (Goldstein and Dillon, 1977). The most distinguishing features are the best predictors for classifying objects into the proper categories.
n our stylometric work we have observed the utility of SDA to choose the words to use as distinguishing features in authorship attribution studies. This observation agrees with work done by other researchers (Smith and Aldridge, 2011). From a comprehensive list of non-contextual words, SDA identifies the most discriminating word first and subsequent words in descending order of discriminating ability. It stops when none of the remaining words add to the discriminating ability of the set of words. Thus, we end up with a subset of words that are the best predictors of authorship.
Another approach often used to select distinguishing features for authorship attribution is to use a list of the most frequent words listed in descending order of frequency in a set of representative texts of the candidate authors’ works. Consequently, we considered this research question:
For a given set of authors and representative texts, and using Burrows’ Delta as the analytical method, will the most distinguishing words (MDWs) identified by SDA give more distinguishing power in the analysis than using the most frequent words (MFWs) approach?
The corresponding null and alternative hypotheses are:
H 0: Using non-contextual MDWs selected by SDA is not more distinguishing among candidate authors than using a set of MFWs.
H a: Using non-contextual MDWs selected by SDA is more distinguishing among candidate authors than using a set of MFWs.
2. Method
To answer our research question, the metric we used for a set of words’ distinguishing power was the difference in Burrows’ Deltas for the two authors with the smallest Deltas to that text. If the null hypothesis is true, the differences between Deltas should be about the same whether using MDWs or using MFWs. If using MDWs produces larger Delta differences than using MFWs, that evidence would support the alternative hypothesis.
We used the difference in Deltas between the nearest authors because it is an indication of statistical power. Analogous to the power of a microscope, statistical power is a statistical technique’s ability to distinguish between things that are close together. The greater the distance between Deltas, the greater the power of the technique used to calculate the Deltas.
To conduct the study we used The Federalist Papers, commonly used for testing the usefulness of authorship attribution methods. The Federalist Papers are well suited to the problem as there were a total of 85 published papers written by Alexander Hamilton, James Madison and John Jay. Fifty-one were known to have been written by Hamilton, fourteen by Madison, five by Jay, and three written jointly by Hamilton and Madison. Twelve had disputed authorship, but have subsequently been studied extensively and are commonly attributed to Madison.
Because the attribution of the disputed papers is relatively non-controversial, The Federalist Papers provide a useful basis for comparing attribution methods. Since our research objective was not to answer the attribution question, but rather to compare methods of answering the question, using The Federalist Paper removed the question of correct attribution for a more direct comparison of the distinguishing ability of SDA-selected MDWs compared to MFWs.
Using only the 70 papers of known authorship as the representative texts, we applied SDA and selected the MDWs from a large list of non-contextual words, and then calculated Burrows’ Delta distances for each paper to each of the three candidate authors. We compared these results to the results of using sets of MFWs ranging from 50 to 500 words in increments of 50 words.
Results
The SDA procedure select 29 words as the most distinguishing words for The Federalist Papers. Those 29 MDWs produced 100% correct classification of the 70 representative texts and provided greater distinguishing power than MFWs for the 12 disputed texts. As shown in figure 2, for The Federalist Papers, MDWs have from 1.5 to 4 times the discriminating power of MFWs.
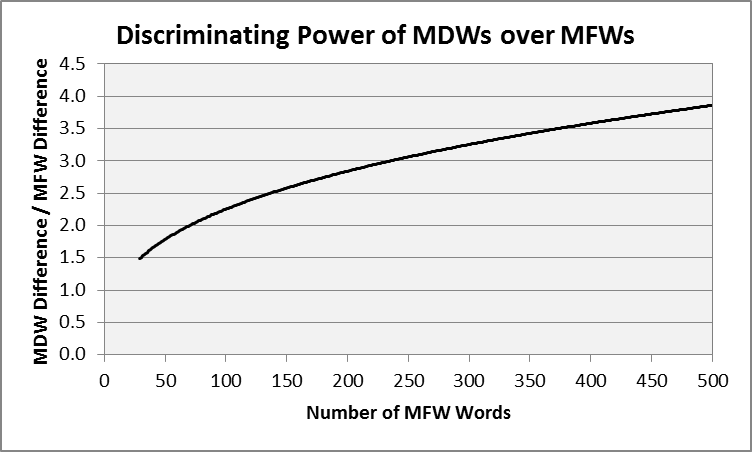
To understand why this occurs, examine table 1 and notice where each of the 29 MDWs appears on the MFW list.
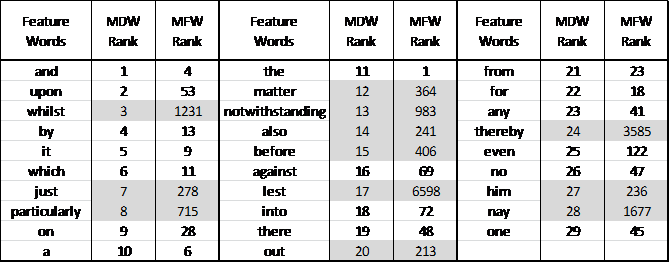
Words in a list of MDWs often are not included in typical MFW lists. For example, note that the word, whilst, is the third most discriminating word selected by SDA and yet it is not even in the top 1000 MFWs. Even though Mosteller and Wallace identified whilst as a key indicator of authorship for the disputed papers, MFW lists of less than 1231 words would miss this highly distinguishing word. Notice further that 12 of the 29 MDWs are not even in the top 200 MFWs. So using MFWs will miss many highly distinguishing words.
3. Discussion
Thus, we reject the null hypothesis and assert that MDWs provide more distinguishing power between the Deltas for the two closest authors to the texts to be attributed as compared to MFWs. Our results show that MDWs can provide greater sensitivity than MFWs in discovering stylistic word-choice differences among candidate authors. The finding that it only takes 29 words selected by SDA to correctly classify all of the disputed Federalist Papers is a striking example of the power of using SDA-selected MDWs, since over 350 MFW words – more than ten times as many words – were required to achieve the same results.
Although some research has shown that variations of Delta may perform better than Burrows’ original formulation (Evert et al., 2015; Hoover, 2004), we have found that using modifications of Delta does not improve the performance of MFWs relative to MDWs.
Conclusion
We conclude greater discriminating power can be achieved with a small set of MDWs chosen by SDA than with even large sets of MFWs. Using SDA-selected MDWs a researcher is more likely to make correct attributions and may be able to do it with fewer representative texts and for smaller texts. As a result, a researcher will have a greater likelihood of discovering new insights about the possible authorship of unattributed or disputed texts.
- Argamon, S., et al. (2003). Gender, genre, and writing style in formal written texts. Text, 23(3): 321-46.
- Burrows, J. (2002). ‘Delta’: A measure of stylistic difference and a guide to likely authorship. Literary and Linguistic Computing, 17(3): 267-87.
- Evert, S., et al. (2015). Towards a better understanding of Burrows’s Delta in literary authorship attribution. Proceedings of NAACL-HLT Fourth Workshop on Computational Linguistics for Literature, Denver, CO.
- Fisher, R. A. (1936). The use of multiple measurements in taxonomic problems. Annals of Eugenics, 7(2): 179-88.
- Goldstein, M. and Dillon, W. R. (1977). A stepwise discrete variable selection procedure. Communications in Statistics – Theory and Methods, 6(14): 1423-36.
- Holmes, D. I. (1998). The evolution of stylometry in humanities scholarship. Literary and Linguistic Computing, 13(3): 111-17.
- Hoover, D. L. (2004). Delta prime?, Literary and Linguistic Computing, 19(4): 477-95.
- Mosteller, F. and Wallace, D. L. (2007). Inference and Disputed Authorship: The Federalist, The David Hume Series Philosophy and Cognitive Science Reissues, CSLI Publications.
- Smith, P. W. H. and Aldridge, W. (2011). Improving Authorship Attribution: Optimizing Burrows' Delta Method. Journal of Quantitative Linguistics, 18(1): 63-88.
- Stamatatos, E. (2009). A survey of modern authorship attribution methods. Journal of the American Society for information Science and Technology, 60(3): 538-56.