Authors: Alexander Mehler, Benno Wagner, Rüdiger Gleim
Category: Paper:Long Paper
Keywords: text mining, Wikidition, multi-layer network, linkification, lexiconisation
Wikidition: Towards A Multi-layer Network Model of Intertextuality
1. Introduction
Current computational models of intertextuality run the risk of ignoring several desiderata: on the one hand, they mostly rely on single methods of quantifying text similarities. This includes syntagmatic models that look for shared vocabularies (unigram models) or (higher order) ( k-skip-) n-grams (Guthrie et al., 2006). Such approaches disregard the two-level process of sign constitution according to which language-related, paradigmatic relations have to be distinguished from their text-related, syntagmatic counterparts (Hjelmslev, 1969; Miller et al., 1991; Raible, 1981) where the former require language models of the sort of neural networks (Mikolov et al., 2013), topic models (Blei et al., 2007) or related approaches in the area of latent semantic analysis (cf., e.g., (Paaß et al., 2004)). On the other hand, computational models should enable scholars to revise their computations. The reason is the remarkably high error rate produced by statistical models even in cases that are supposed to be as “simple” as automatic pre-processing. Thus, scholars need efficient means to make numerous corrections and additions to automatic computations. Otherwise, the computations will be hardly acceptable as scientific data in the humanities (Thaller, 2014).

This paper presents Wikidition as a Literary Memory Information System (LiMeS) to address these desiderata. It allows for the automatic generation of online editions of text corpora. This includes literary texts in the role of (referring) hypertexts (Genette, 1993) in relation to candidate (referred) hypotexts by exploring their intra- and intertextual relations – see Table 1 for nine related research scenarios. In order to explore, annotate and display such relations, Wikidition computes multi-layer networks that account for the multi-resolution of linguistic relations – on the side of the hypo- and the hypertexts. The reason is that hypertextual relations (in the sense of Genette) (that occur in the form of transformations, imitations or any mixture thereof) may be manifested on the lexical, sentential or the textual level (including whole paragraphs or even larger subtexts). As a consequence, Wikidition spans lexical, sentential and textual networks that allow for browsing along the constituency relations of words in relation to sentences, sentences in relation to texts etc. In this multi-layer network model, intrarelational links (of words, sentences or texts) are represented together with interrelational links that combine units of different layers. Figure 1 shows the range of sign relations that are mapped. To this end, Wikidition combines a multitude of text similarity measures (beyond n-grams) for automatically linking lexical, sentential and textual units regarding their (1) syntagmatic (e.g., syntactic) and (2) paradigmatic use. We call this two-level task linkification.
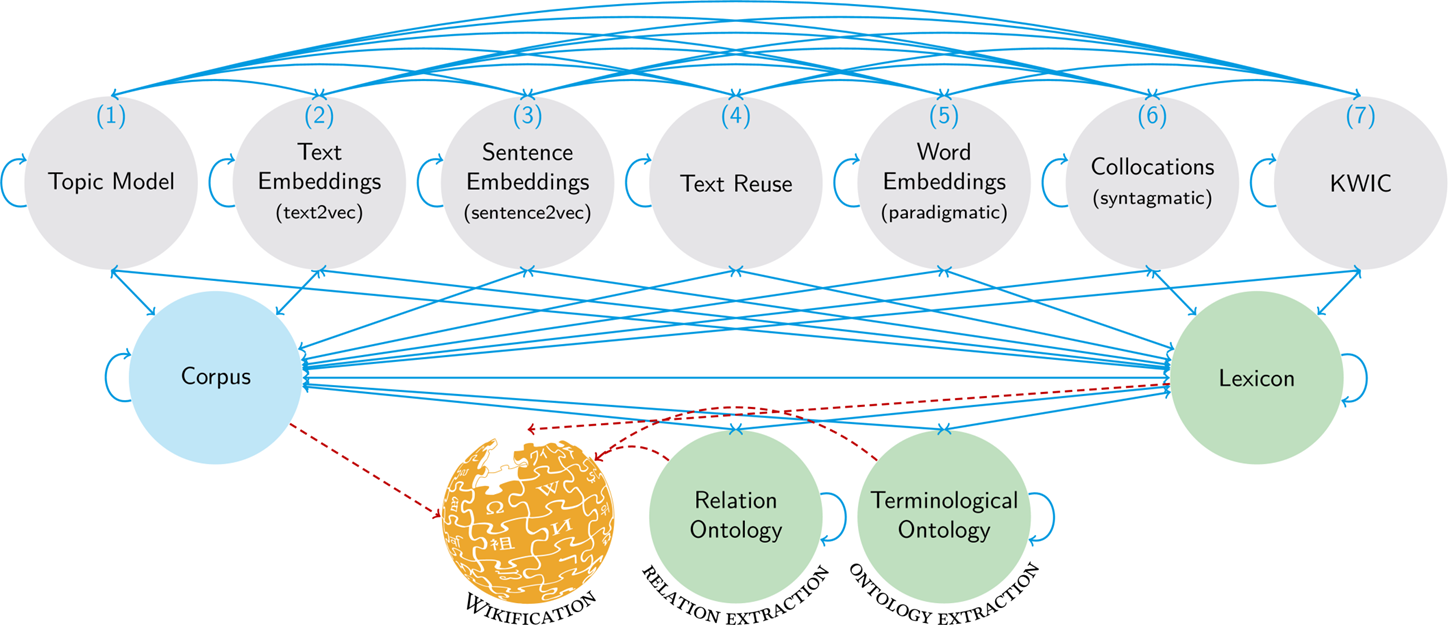
Beyond linkification, Wikidition contains a module for automatic lexiconisation (see Figure 2). It extracts lexica from input corpora to map author specific vocabularies as subsets of the corresponding reference language. Input corpora (currently in English, German or Latin) are given as plain text that first are automatically preprocessed; the resulting wikiditions are mapped onto separate URLs to be accessible as self-contained wikis. By means of lexiconisation, research questions of the following sort can be addressed: What kind of German does Franz Kafka write? (E.g., Prager Deutsch.) What terminologies does Franz Kafka use in “In der Strafkolonie”? (E.g., engineering terminology.) How does his German depart from the underlying reference language? Since texts are not necessarily monolingual (because of using citations, translations, loan words, verbal expressions etc.), the same procedure can be applied by simultaneously looking at all foreign languages being manifested in the texts under consideration (right side of Figure 2).
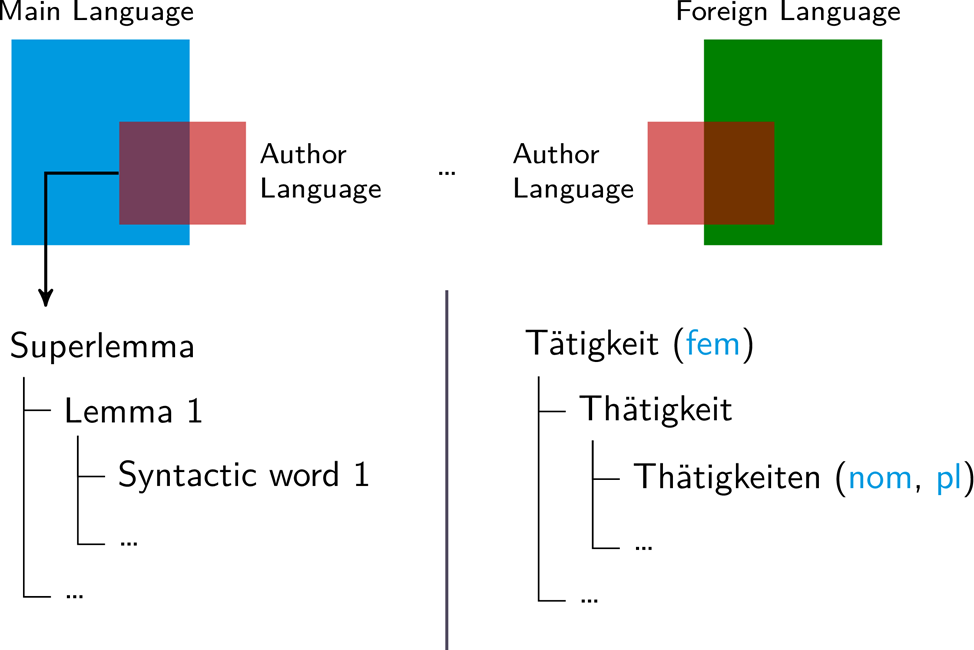
To this end, Wikidition distinguishes three levels of lexical resolution: superlemmas (e.g. German Tätigkeit), lemmas (e.g., Thätigkeit) and syntactic words (e.g., Thätigkeiten ( nominative, plural)) as featured sign-like manifestations of lemmas (lower part of the figure). Note that this model diverges from the majority of computational models to textual data which start from tokens as manifestations of wordforms (referred to as types) and which, therefore, disregard the meaning-side of lexical units. Based on linkification and lexiconisation, Wikidition does not only allow for traversing input corpora on different (lexical, sentential and textual) levels. Rather, the readers of a Wikidition can also study the vocabulary of single authors on several levels of resolution: starting from the level of superlemmas via the level of lemmas down to the level of syntactic words and wordforms (see Figure2).
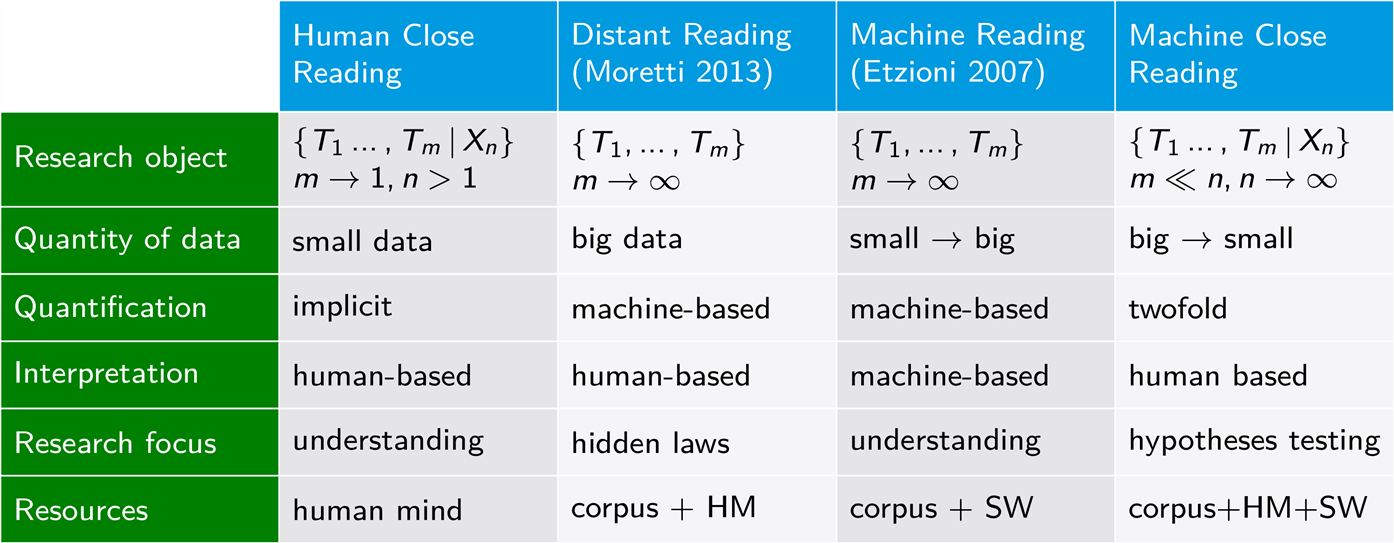
While the linkification component of Wikidition relates to principles of WikiSource and Wikipedia, the Wiktionary project is addressed by its lexiconisation module. Wikidition uses numerous computational methods for providing interoperability and extensibility of the resulting editions according to the wiki principle. In this way, the dissemination of computer-based methods is supported even across the borders of digital humanities in that scholars are enabled to make their own exploratory analyses. However, Wikidition does not address a big data scenario in support of distant reading (Moretti, 2013), nor does it aim at emulating human reading in the sense of machine reading (Etzioni, 2007). Rather, Wikidition addresses what we call machine close reading in that it aims at massively supporting the process of (scientific or literary) reading by means of computational methods (see Table 2).
2. Evaluation
We exemplify Wikidition by example of three pairs of text. Regarding the layers of lemmas and sentences, Table 3 shows that Wikidition generates extremely sparse networks (whose cohesion is below 1%) of high cluster values and short average geodesic distances in conjunction with largest connected components that comprise almost all lexical and sentential nodes. In this example, we compute paradigmatic associations among words by means of word2vec (Mikolov et al., 2013) while sentence similarities are computed by means of the centroids of the embeddings of their lexical constituents. Networks are filtered by focusing on the first three most similar neighbors of each node – obviously, this does not interfere with the small-world topology of the networks. Each pair of texts is additionally described regarding the subnetwork of syntactic words and sentences. This is done to account for the impact of inflection on networking. As a result, the networks are thinned out (cohesion is now at most 0.5%), but neither the sizes of the largest connected components nor the cluster and distances values are affected considerably. Obviously, differentiation leads to sparseness, but in a sense that the general topology is retained. By focusing on a single level of resolution (e.g., paradigmatic relations among words), sub-networks are generated that fit into what is known about universal laws of complex linguistic networks (Mehler, 2008). See (Mehler et al., 2016) for additional evaluations of Wikidition.
| Edition | #nodes | #links | c | lcc | l | coh |
| Kafka // Nietzsche | 1624 | 10391 | 0,27 | 1 | 3,31 | 0,008 |
| 2401 | 13644 | 0,34 | 1 | 3,56 | 0,005 | |
| Kafka // Rathenau | 1749 | 10782 | 0,28 | 1 | 3,36 | 0,007 |
| 2473 | 13609 | 0,36 | 1 | 3,60 | 0,004 | |
| Kafka // Rauchberg | 4034 | 30951 | 0,25 | 0,999 | 3,35 | 0,004 |
| 6830 | 44369 | 0,31 | 0,999 | 3,62 | 0,002 |
3. Conclusion
We presented Wikidition as a framework for exploring intra- and intertextual relations. Wikidition combines machine learning with principles of several wiki-based projects (Wikipedia, WikiSource and Wiktionary) to generate multi-layer networks from input corpora by integrating syntagmatic and paradigmatic relations on the lexical, sentential and the textual level. Our approach addresses intra- and inter-level networking in a single framework while adhering to laws of networking as being explored by complex network theory. In this way, input corpora get traversable in line with both empirical findings about characteristics of linguistic networks and the multi-resolution of sign relations whose space complexity is preferably reduced. Currently, Wikidition exists as a prototype that is further-developed by means of several edition projects in order to be finally made available as open source software. Wikidition is open for the cooperative development of digital editions.
- Eger, S. and Gleim, R. and Mehler, A. (2016). Lemmatization and Morphological Tagging in German and Latin: A comparison and a survey of the state-of-the-art. In Proceedings of the 10th International Conference on Language Resources and Evaluation.
- Etzioni, O. (2007). Machine reading of web text. In Proceedings of the 4th International Conference on Knowledge Capture, K-CAP ’07, pp. 1–4.
- Genette, G. (1993). Palimpseste: Die Literatur auf zweiter Stufe. Suhrkamp, Frankfurt am Main.
- Guthrie, D., Allison, B., Liu, W., Guthrie, L. and Wilks, Y. (2006). A closer look at skip-gram modelling.
- Hjelmslev, L. (1969). Prolegomena to a Theory of Language. University of Wisconsin Press, Madison.
- Kafka, F. (1916). Die Verwandlung. Kurt Wolff Verlag, Leipzig.
- Kafka, F. (1919). In der Strafkolonie. Kurt Wolff Verlag, Leipzig.
- Mehler, A. (2008). Large text networks as an object of corpus linguistic studies. In Anke Lüdeling and Merja Kytö, editors, Corpus Linguistics. An International Handbook of the Science of Language and Society. De Gruyter, Berlin/New York, pp. 328–82.
- Mehler, A., Gleim, R., vor der Brück, T., Hemati, W., Uslu, T. and Eger, S. (2016). “Wikidition: Automatic Lexiconization and Linkification of Text Corpora,” Information Technology.
- Mihalcea, R. and Csomai, A. (2007). Wikify!: Linking documents to encyclopedic knowledge. In Proceedings of the Sixteenth ACM Conference on Conference on Information and Knowledge Management, CIKM ’07. New York, NY, USA. ACM, pp. 233–42.
- Mikolov, T., Yih, W. and Zweig, G. (2013). Linguistic regularities in continuous space word representations. In Lucy Vanderwende, Hal Daumé III, and Katrin Kirchhoff, (eds), Proceedings of NAACL 2013. The Association for Computational Linguistics, pp. 746–51.
- Miller, G. A. and Charles, W. G. (1991). Contextual correlates of semantic similarity. Language and Cognitive Processes,6(1): 1–28.
- Moretti, F. (2013). Distant Reading. Verso.
- Paaß, G., Kindermann, J. and Leopold, E. (2004). Learning prototype ontologies by hierarchical latent semantic analysis. In Andreas Abecker, Steffen Bickel, Ulf Brefeld, Isabel Drost, Nicola Henze, Olaf Herden, Mirjam Minor, Tobias Scheffer, Ljiljana Stojanovic, and Stephan Weibelzahl, (eds), LWA 2004: Lernen – Wissensentdeckung – Adaptivität. Humbold-Universität Berlin, pp. 193–205.
- Raible, W. (1981). Von der Allgegenwart des Gegensinns (und einiger anderer Relationen). Strategien zur Einordnung semantischer Informationen. Zeitschrift für romanische Philologie,97(1-2): 1–40.
- Rauchberg, H. (1890). Statistische Technik. Deutsche Statistische Gesellschaft, 1.
- Thaller, M. (2014). The humanities are about research, first and foremost; their interaction with computer science should be too. Dagstuhl Reports,4(7): 108–10.