Authors: Fotis Jannidis, Isabella Reger, Markus Krug, Lukas Weimer, Luisa Macharowsky, Frank Puppe
Category: Paper:Short Paper
Keywords: evaluation, character networks
Comparison of Methods for the Identification of Main Characters in German Novels
1. Motivation
Digital literary studies have embraced social network analysis as a powerful tool to formalize and analyze social networks in literary texts (Elson et al., 2010b, Hettinger et al., 2015). Extracting networks automatically from texts is still a challenging task with the following steps: identification of all character references (which is not identical to named entity recognition), coreference resolution (CR) and a final step defining the amount of interaction between the characters, for example by the amount of verbal exchanges or the co-occurrence in a text segment. In the following we will discuss different ways to solve this task using an annotated corpus of German novels. One of the related problems is the definition of an evaluation metric which connects the computational problem to literary concepts like “main characters” and “character constellation”. Our goal is to find the best way to capture the intuition behind these literary concepts in a formalized procedure. For this purpose we introduce a new way of evaluating automatically extracted networks. We make use of carefully created and revised summaries of German novels, provided by Kindler Literary Lexicon Online 1. Besides, this work is to the best of our knowledge the first to compare different methods of creating and evaluating automatically extracted character networks.
2. Related Work
Social Network Analysis (SNA) is a well-established discipline, e.g. in the social sciences, which literary studies can apply for the analysis of character networks (Trilcke, 2013). Approaches to automatic extraction of SNs from literary text using NLP techniques have been manifold.
Most works start by identifying entities in the text and connect them via CR. Park et al. (Park et al., 2013) extract SNs based on proximity of names in the text and define a kernel function to distinguish protagonists from less important characters. Celikyilmaz et al. (Celikyilmaz et al., 2010) use an unsupervised actor-topic-model to create SNs from narratives. Elson et al. associate speakers with direct speech passages in novels (Elson et al., 2010a) and create SNs from the dialogues to validate literary hypotheses like whether the amount of dialogues is inversely proportional to the amount of characters that appear in the novel (Elson et al., 2010b).
Moreover, three end-to-end systems for the extraction and visualization of SNs from English literary texts already exist: PLOS (Waumans et al., 2015) works similarly to the approach by Elson et al. by creating networks from dialogue interactions. He et al. use their own speaker identification system to detect family connections between entities (He et al., 2013). SINNET by Agarwal et al. (Agarwal et al., 2013b) finds different types of directed events in a text and creates a directed SN from these events.
3. Data
This work is based on a corpus of 452 German novels from the TextGrid Digital Library 2. Expert plot summaries from Kindlers Literary Lexicon Online are available for 215 of these novels. As the following experiments are partly based on direct speech, we analysed the novels with regard to the direct speech they contain. We selected 58 novels with the highest possible amount of direct speech for which there was also a summary on hand.
Those 58 novels have been split into tokens and sentences with OpenNLP 3, POS-tagged and lemmatized by the TreeTagger (Schmid, 1995), further processed by the RFTagger (Schmid and Laws, 2008) and the morphological tagger from MATE-Tools 4. Additionally, we use the dependency parser by Bohnet (Bohnet and Kuhn, 2012) to analyze the sentence structure. Named Entity Recognition is done with the tool by Jannidis et al. (Jannidis et al., 2015) and the rule-based component by Krug et al. is used for CR. The detection of the speaker and the addressee for each direct speech passage is also part of the CR (Krug et al., 2015). In the summaries from Kindler, Named Entities and Coreferences have been manually labeled by two annotators.
4. Methods
We use four different methods to identify the most central characters in the novels and evaluate their quality by comparison with the characters occurring in the Kindler summaries.
The first method relies only on the frequencies of the characters in the text: the most central characters are those appearing most often in the novel (coreferences resolved). The second methods counts only those entities that have at least once been detected as speaker or addressee of direct speech. The other methods each construct a different type of social network and make use of SNA to find the most central characters. The first network is based on co-occurrences of characters in the same window of text: an edge between two characters exists if they are mentioned in the same paragraph and the weight of the edge is the number of paragraphs in which this is the case. The second network is created using the dialogue structure of the text. For each direct speech for which both speaker and addressee could be detected, an edge is drawn between those two. Longer dialogues consequently lead to higher edge weights between the participants. Thus, both network types are undirected and weighted. Examples for networks that were created with those methods are shown in Figure 1.
To identify the most central characters we use the weighted degree of each node (i.e. the sum of the weights of all edges incident to a node) in decreasing order. This metric is most intuitively interpretable with regard to the importance of characters in a fictional world.
In the following paragraph, we compare the rankings with the summaries and discuss possible sources of error and their influence on the results.
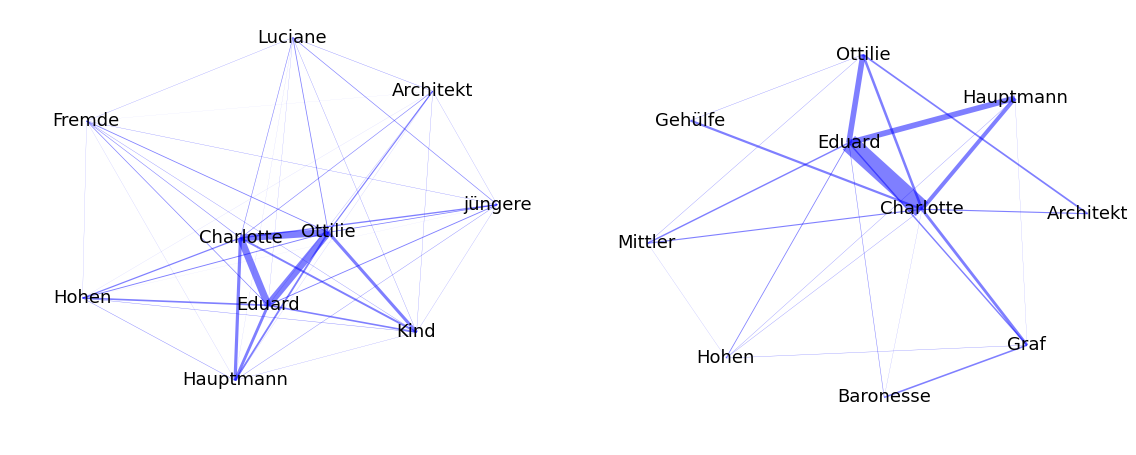
Figure 1: Automatically extracted SNs for Goethes: “Die Wahlverwandtschaften”. The left picture shows the ten most connected characters when an interaction is created for a common appearance in a paragraph. The right picture shows the corresponding network when only direct speech is used as interactions.
5. Evaluation
Evaluating automatically extracted SNs is not a trivial task and there are no established practices. Elson et al. (Elson et al., 2010b) validate literary hypotheses, (Park et al., 2013) and (Waumans et al., 2015) analyze typical distributions that they expect of literary character networks. Agarwal et al. (Agarwal et al., 2013a) evaluate a machine-generated network of Alice in Wonderland against a manually conceived version by comparing typical SNA metrics like different centrality measures.
In this work, we want to compare the methods for identifying the most central characters as described in section 4. As a gold standard, we use the manually annotated Kindler summaries. The generated rankings for each novel, as well as the rankings from the summaries are first cleaned up so that only real names remain.
Our evaluation is based on the assumption that a summary contains all important characters. Since those summaries are carefully created and even revised by experts we propose that this assumption holds. For each summary, we create a ranking of the mentioned characters by [a] the number of occurrences (gold_count from here) and [b] the order of occurrence (gold_order from here). We relax the ranking assumption and only select the top 5 (top 10) figures from the summary rankings and compare them against the top 5 (top 10) characters in the automatically obtained rankings for the novels without respecting the particular ordering. If the name of a character from the gold standard is exactly found in an automatic ranking, there is a match. Table 1 shows the resulting correspondences with the two gold rankings, averaged over all 58 novels.
Table 1: Overview of the successfully matched entities between the two relaxed rankings from the summaries (gold_count, gold_order) and the generated relaxed rankings for the top 5 and the top 10 entities (DSN= Direct Speech Network; PN = Paragraph Network;DSC = Direct Speech Count; Count = simple frequency)
| Algorithm | DSN_5 | DSN_10 | PN_5 | PN_10 | DSC_5 | DSC_10 | Count_5 | Count_10 |
| gold_count | 40.5% | 50.2% | 39.3% | 51.6% | 38.9% | 49.0% | 40.1% | 52.0% |
| gold_order | 38.6% | 45.1% | 41.3% | 48.6% | 37.5% | 45.3% | 41.2% | 48.5% |
6. Results and Discussion
Table 1 displays first results for the identification of main characters in novels. Nevertheless, none of the methods yields very high scores for this kind of evaluation. Interestingly, the simpler approaches seem to be suited well for the task.
The low values can be explained by a variety of errors which can be grouped in three categories. Firstly, a character might not be among the top 10 of the relaxed ranking from Kindler. If automatic matches to lower positions in the ranking are allowed, the score in Table 2 can be reached.
Table 2: Accuracy of the matching, independent of the position in the automatic ranking
| Algorithm | DSN_Max | PN_Max | DSC_Max | Count_Max |
| gold_count | 55.1% | 56.6% | 53.8% | 57.3% |
| gold_order | 58.0% | 64.7% | 55.1% | 64.7% |
We can see that approximately 60% of the characters can now be matched unambiguously.
The highest percentage of errors is due to incorrectly resolved coreferences. Clusters of the same character that have not been merged during the CR do not only create redundant elements in the rankings, wrongly merged clusters also mean, that one character can never be matched correctly. If coreference errors are ignored, the results are as shown in table 3.
Table 3: Accuracy of the matching, independent of the position in the automatic ranking, CR errors ignored
| Algorithm | DSN_Maxcr | PN_Maxcr | DSC_Maxcr | Count_Maxcr |
| gold_count | 79.7% | 81.2% | 78.8% | 81.2% |
| gold_order | 58.6% | 65.3% | 55.6% | 65.3% |
The third error type of originates from different spellings of the same name which make an unambiguous matching very difficult (e.g. “Amanzéi” vs. “Amanzei”, “Lenore” vs. “Leonore”). Those kinds of errors are caused by different encodings, since the novels and the summaries originate from separate sources. Further reasons which render the matching more difficult or impossible respectively are missing or incorrectly detected Named Entities. The error analysis shows that future improvements are especially needed for the CR or procedures which avoid CR, since those have a better chance to succeed.
7. Conclusion
In this paper we showed work in progress to extract SNs from German novels. We compared four different approaches to the identification of central characters and evaluated against manually annotated summaries. Two presented methods rely on direct speech, the other methods can be applied to any novel. At least for this task, the more challenging approaches of determining speaker and addressee of direct speech and creating networks from the resulting interactions did score slightly lower than the simpler approaches. To improve the results, future work especially needs to be invested into the creation of a less error-prone CR system.
- Agarwal, A., Kotalwar, A. and Rambow, O. (2013a). Automatic Extraction of Social Networks from Literary Text: A Case Study on Alice in Wonderland, Proceedings of the 6 th International Joint Conference on Natural Language Processing (IJCNLP 2013), Nagoya, Japan.
- Agarwal, A. et al. (2013b). Sinnet: Social Interaction Network Extractor from Text, Proceedings of the 6 th International Joint Conference on Natural Language Processing (IJCNLP 2013), Nagoya, Japan.
- Ardanuy, M. C. and Sporleder, C. (2014). Structure-based Clustering of Novels, Proceedings of EACL 2014, Gothenburg, Sweden.
- Bohnet, B. and Kuhn, J. (2012). The Best of Both Worlds: a Graph-based Completion Model for Transition-based Parsers, Proceedings of EACL 2012, Avignon, France.
- Celikyilmaz, A. et al. (2010). The Actor-Topic Model for Extracting Social Networks in Literary Narrative, NIPS Workshop: Machine Learning for Social Computing.
- Elson, D. K. and McKeown, K. (2010a). Automatic Attribution of Quoted Speech in Literary Narrative, Proceedings of AAAI 2010, Atlanta, Georgia.
- Elson, D. K., Dames, N. and McKeown, K. (2010b). Extracting Social Networks from Literary Fiction, Proceedings of ACL 2010, Uppsala, Sweden.
- Gruzd, A. A. and Haythornthwaite, C. (2008). Automated Discovery and Analysis of Social Networks from Threaded Discussions, Proceedings of INSNA 2008, St. Pete Beach, Florida.
- Hassan, A., Abu-Jbara, A. and Radev, D. (2012). Extracting Signed Social Networks from Text, Workshop Proceedings of TextGraphs7 on Graph-based Methods for Natural Language Processing, Jeju, Republic of Korea.
- He, H., Barbosa, D. and Kondrak, G. (2013). Identification of Speakers in Novels, Proceedings of ACL 2013, Sofia, Bulgaria.
- Hettinger, L. et al. (2015). Genre Classification on German Novels, Proceedings of the 12th International Workshop on Text-based Information Retrieval, Valencia, Spain.
- Jannidis, F. et al. (2015). Automatische Erkennung von Figuren in deutschsprachigen Romanen, Digital Humanities im deutschsprachigen Raum, Graz, Austria.
- Jing, H., Kambhatla, N. and Roukos, S. (2007). Extracting Social Networks and Biographical Facts from Conversational Speech Transcripts, Proceedings of ACL 2007, Prague, Czech Republic.
- Krug, M. et al. (2015). Attribuierung direkter Reden in deutschen Romanen, Digital Humanities im deutschsprachigen Raum 2016, Leipzig, Germany, 2016.
- Krug, M. et al. (2015). Rule-based Coreference Resolution in German Historic Novels, Proceedings of the 4 th Workshop on Computational Linguistics for Literature, Denver, CO, USA, 2015.
- Park, G. M. et al. (2013). Complex System Analysis of Social Networks Extracted from Literary Fictions, International Journal of Machine Learning and Computing 31: 107-11.
- Schmid, H. and Laws, F. (2008). Estimation of Conditional Probabilities with Decision Trees and an Application to Finegrained POS Tagging, Proceedings of Coling 2008, Manchester, UK. .
- Schmid, H., Fitschen, A. and Heid, U. (2004). SMOR: A German Computational Morphology Covering Derivation, Composition and Inflection, Proceedings of LREC 2004, Lisbon, Portugal.
- Schmid, H. (1995). Improvements in Part-of-Speech Tagging with an Application to German, In Proceedings of the EACL SIGDAT Workshop 1995, Dublin, Ireland.
- Sutton, C. and McCallum, A. (2006). An Introduction to Conditional Random Fields for Relational Learning. In Getoor, L. and Taskar, B. (Eds.), Introduction to Statistical Relational Learning. Cambridge: MIT Press, pp. 93-128.
- Trilcke, P. (2013). Social Network Analysis (SNA) als Methode einer textempirischen Literaturwissenschaft. In Philip Ajouri, P., Mellmann, K. and Rauen, C. (Eds.) , Empirie in der Literaturwissenschaft, Münster: Mentis, pp. 201-47.
- Waumans, M. C., Nicodème, T. and Bersini, H. (2015). Topology Analysis of Social Networks Extracted from Literature, PloS one 10.6: e0126470.
http://kll-online.de
https://textgrid.de/digitale-bibliothek
https://opennlp.apache.org/
https://code.google.com/p/mate-tools/