Authors: Christof Schöch, Daniel Schlör, Stefanie Popp, Annelen Brunner, Ulrike Henny, José Calvo Tello
Category: Paper:Long Paper
Keywords: direct speech, dialogue, Random Forest, novels, literary genre
Straight Talk! Automatic Recognition of Direct Speech in Nineteenth-Century French Novels
1. Introduction
In fictional prose narrative such as novels and short stories, various forms of speech, thought, and writing representation are ubiquitous and have been studied in great detail in linguistics and literary studies. However, beyond quotation marks, what are linguistic markers of direct speech? And just how ubiquitous is direct speech really? Is there systematic variation in the amount of direct speech over time or across genres? Especially for the field of French literary history, where typography is not a reliable guide, we really don't know.
This is regrettable, because being able to quickly and automatically detect direct speech in large collections of literary narrative texts is highly desireable for many areas in literary studies. In the history of literary genres, this allows to observe distributions and evolutions of a fundamental, formal aspect of the novel on a large scale. In narratology, differentiating narrator from character speech is a precondition for more detailed analyses of narrator speech, e.g. with regard to text type (descriptive, narrative, argumentative text). And in authorship attribution, it hereby becomes possible to discard character speech from a set of novels and perform authorship attribution on the narrator speech only, something which may improve attribution.
Against this background, the work presented here addresses both the question of how to identify direct speech in French prose fiction and that of how prevalent direct speech is in different subgenres of the nineteenth-century French novel.
2. Aims and hypotheses
Our first aim has been to use machine learning to automatically identify direct character speech in a small collection of French-language fictional prose. This is less trivial than it seems to be since in the French typographical tradition, direct speech is usually not marked with opening and closing quotation marks (figure 1). Rather, a long hyphen usually indicates the beginning of direct speech, whereas the end is left unmarked. In figure 1, the first highlighted direct speech continues after the insertion revealing who has just spoken (“lui dit-il, tout bas,”; he quietly said to him). In the second example, the direct speech ends after the speaker has been indicated (“dit une voix à la portière”; said a voice at the door). Our hypothesis is that there are enough linguistic markers of direct speech to make it possible to identify it automatically and reliably (for an overview of such markers, see Durrer, 1994).

Our second aim has been to use the best-performing algorithm to identify direct speech in a larger collection of French nineteenth-century novels and to study its distribution. Here, we hope to detect significant differences in the proportion of direct speech found in different novelistic subgenres. Research about other literary traditions supports this hypothesis (e.g. Allison et al., 2011).
3. State of the Art
Speech, thought and writing representation are common topics in narratology and stylistics (Genette, 2008, Leech/Short, 2007). Semino and Short’s 2004 quantitative study finds that direct representation is clearly the most frequent type in their English fiction sub-corpus. Brunner 2015 confirms this trend for her corpus of German short narratives. Here, the percentage of sentences containing direct speech is about 35% and varies widely over different texts (2%-72%).
Frequently, speech representation recognition is an auxiliary step to other tasks, e.g. knowledge extraction or speaker recognition (Krestel at al., 2008, Elson and McKeown, 2010, Iosif and Mishra, 2014, Sarmento/Nunes, 2009). Weiser and Watrin 2012 used a rule-based approach to extract unmarked quotations in French newspaper texts with success rates of 0.745-0.789. Brunner 2015 focuses on speech, thought and writing representation in German short literary narratives. Using machine learning with random forests, she reports an F1 score of 0.87 for direct speech in a sentence-based cross-validation.
4. Data
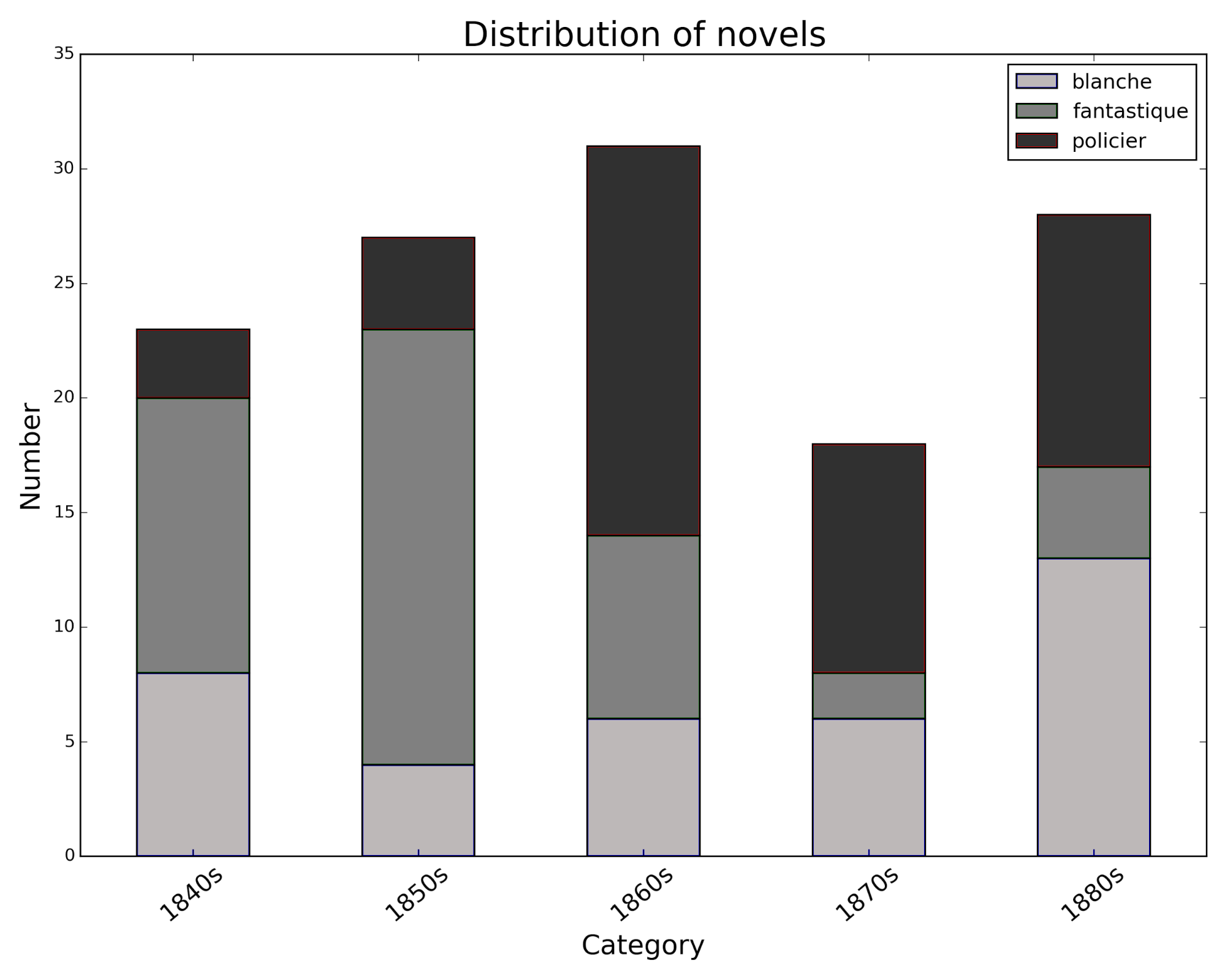
Our text collection contains 127 French novels published between 1840 and 1889. Three generic subsets can be distinguished, each of which is represented by approximately 40 texts: general novelistic fiction (so-called ‘littérature blanche’) is contrasted with specific subgenres, crime fiction (‘policier’) and fantastic novels (see figure 2). The narrative perspective is largely heterodiegetic.
5. Methods
5.1. Manual Annotation
To obtain a gold standard, 40 chapters from 20 different novels were randomly chosen from the collection and annotated manually. 5734 sentences were marked as either containing direct speech or not containing any direct speech; the former also include mixed sentences.
5.2. Preprocessing
To prepare feature generation, preprocessing was performed, the pipeline consisting of the Stanford CoreNLP-Tokenizer and Sentence-Splitter, as well as the TreeTagger for POS-Tagging and Lemmatization.
5.3. Feature generation
We modeled 81 features which we believed to be useful cues for the classification task (see the annex for a ranked list). Features are generated on a sentence-based level and can be divided into different categories:
- Character-based: e.g. long hyphen marks, exclamation marks, question marks.
- Lexical: e.g. deictic expressions, interjections.
- Semantic: categories of verbs, from WordNet and the French equivalent WOLF: e.g. verbs of motion or perception.
- Morphological: e.g. part-of-speech, verb-tense, lemma.
- Syntactic features: e.g. number of commas, sentence length.
5.4. Classification
For the binary classification task (sentences containing vs. not containing direct speech), we used an annotation and classification framework developed by Markus Krug (Würzburg) wrapping LibSVM Support-Vector-Machine (Chang and Lin, 2011), Maximum Entropy (Nigam et al., 1999) and Naïve Bayes (John and Langley, 1995) and implemented in MALLET (McCallum 2002). Random Forest (Breiman, 2001) and JRip (Cohen, 1995) were applied using Weka. All experiments were validated using 10-fold cross-validation unless otherwise stated.
5.5. Error analysis
The machine learning algorithms’ incorrect assignments on the gold standard (false positives and false negatives) were manually analyzed in order to detect the errors' underlying causes.
5.6. Automatic tagging of unseen texts
Using the best-performing model, all sentences in the text collection were tagged for containing direct speech or not. The distribution of ratios of direct speech / non-direct speech was calculated for the three subgenres and five decades covered by the collection. Performance on these unseen texts was checked manually on a random sample. (We sampled 2300 sentences, i.e. 100 random sentences each from a sample of 23 novels stratified by ratio of direct speech.)
6. Results and Discussion
6.1. Recognition of direct speech
Table 1 depicts the performance for different conditions.
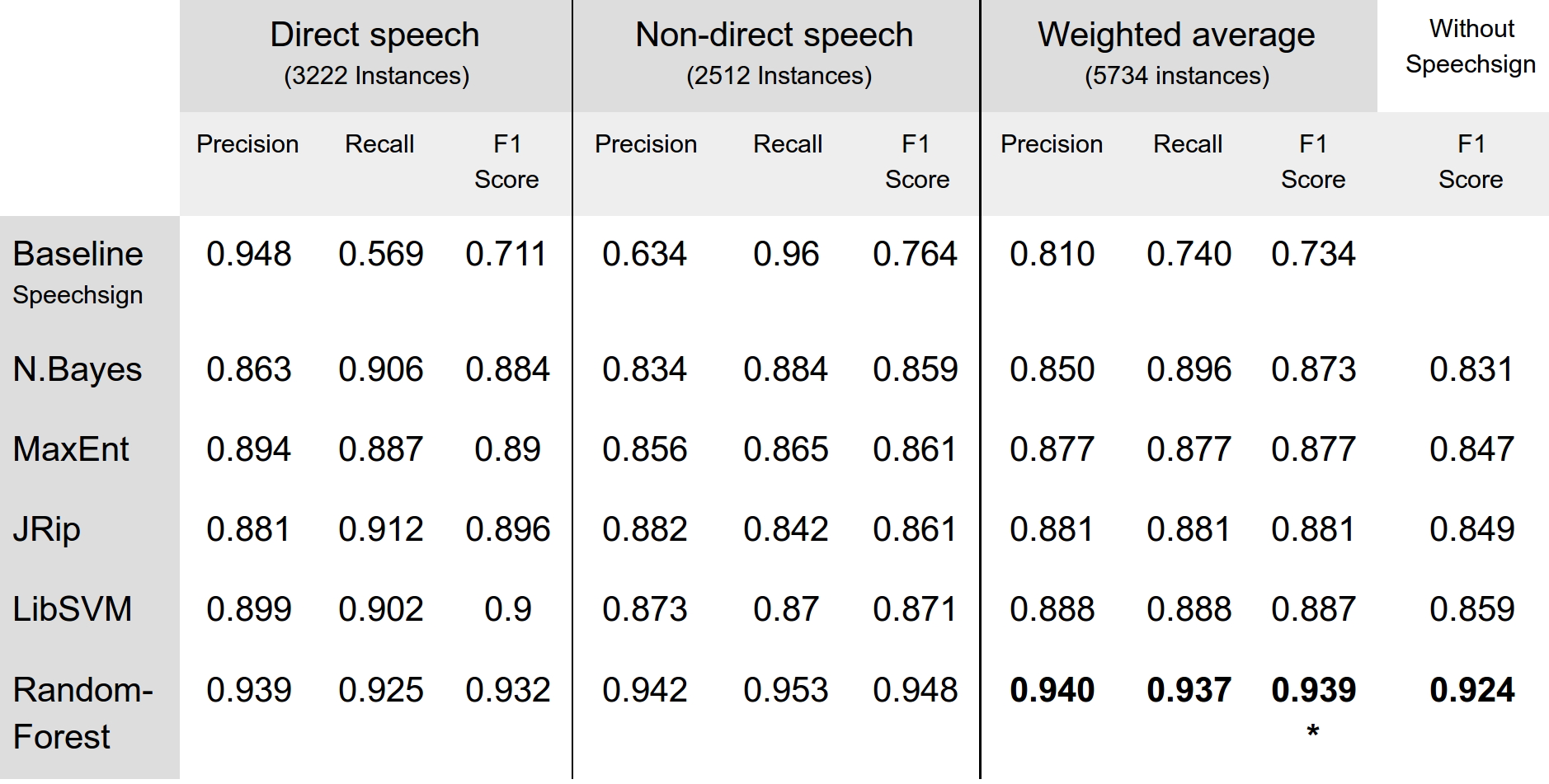
Our baseline is using the speech sign (i.e. the long hyphen) as the only feature, which yields an F1 score of 0.734. Random-Forest performs best, with an F1 score of 0.939, which we consider to be an impressive result. Even when excluding the speech sign from the features, we still reach an F1 score of 0.924, much better than the hyphen alone.
After inspecting the models, it becomes clear that only very few features carry strong cues for direct speech, namely (and unsurprisingly) the initial long hyphen. Most other features, taken separately, carry weak signals in either direction, but become relevant in combination.
Error analysis reveals that incorrect assignments (false positives and negatives) are frequently due to imperfect sentence segmentation. Several features which have been previously used to define and recognize direct speech (question / exclamation marks, interjections, verbal tenses) also cause incorrect assignments, especially in the context of homodiegetic narration, where the narrator is somewhat involved in the plot so that his narrator speech is similar to direct speech. Finally, letters are sometimes mistaken for direct speech, which makes sense given that in most of them, one person addresses one or several other people.
6.2. Distribution of direct speech in the corpus
We applied the best-performing algorithm (Random Forest) to the entire text collection. Evaluation shows a certain drop in performance, with a weighted average success rate of 0.844, indicating less-than-perfect generalization. We noted a welcome absence of any strong bias for either direct or non-direct speech. Our results suggest that the average proportion of direct to non-direct speech across the collection is 61% sentences with direct speech (and 39% without direct speech).
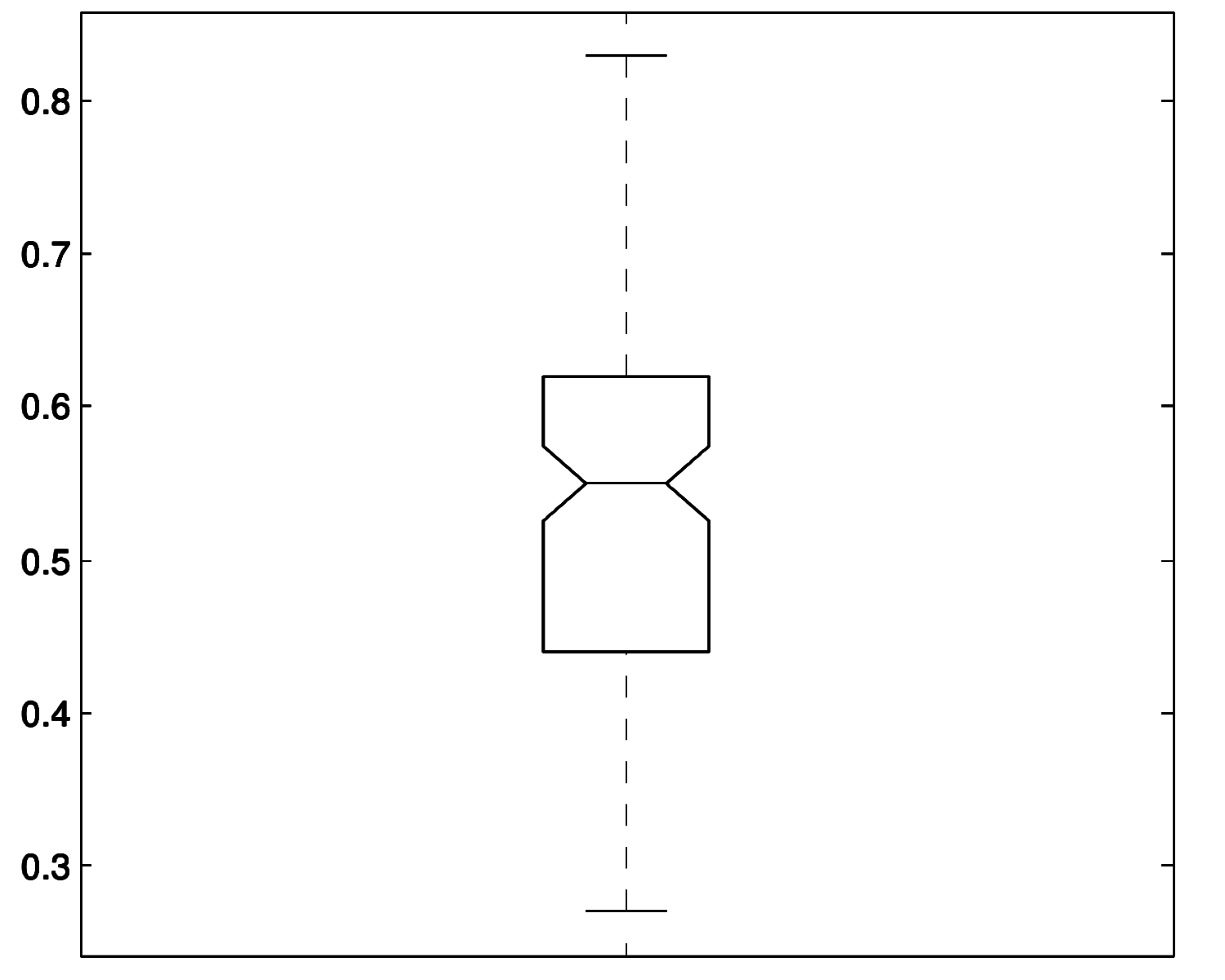
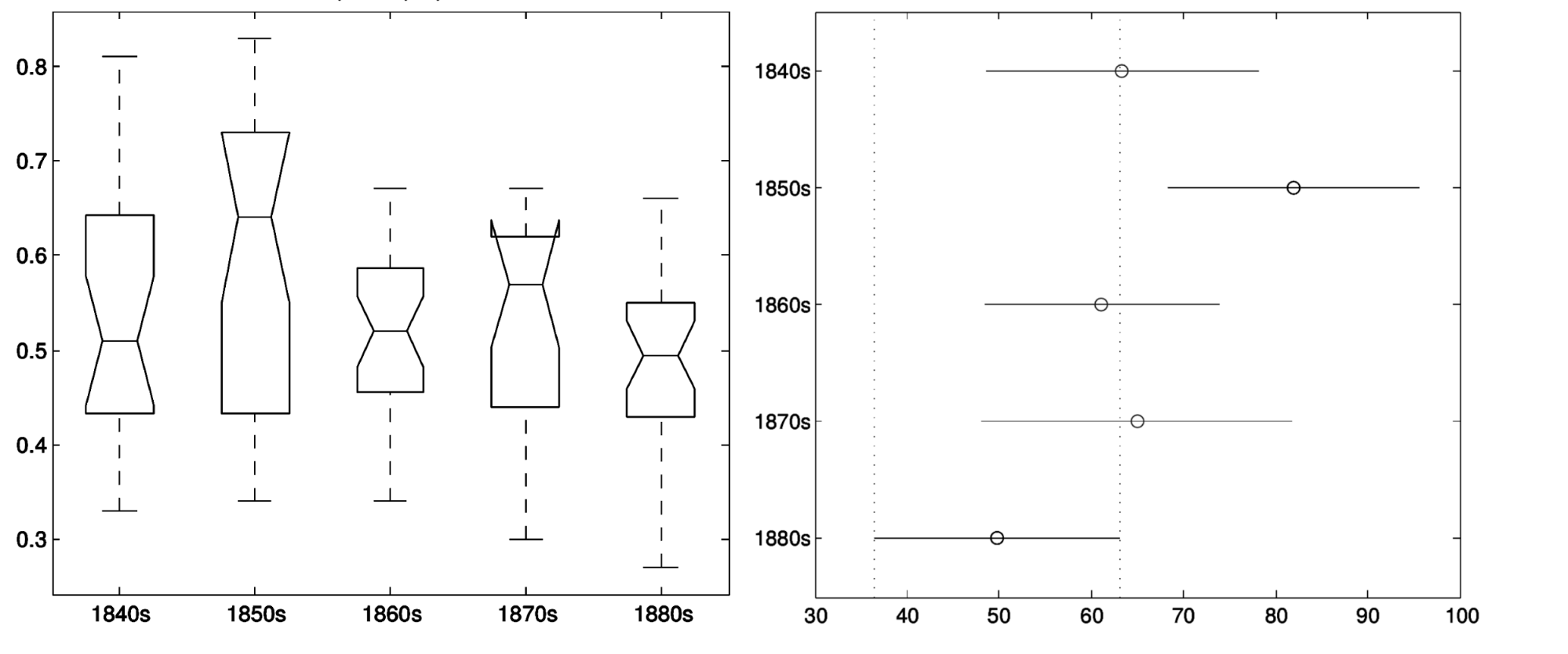
While variance is considerable (see figure 3), the proportion of direct speech in French nineteenth-century novels is overall much higher than expected (and higher, for example, than the 35% reported by Brunner 2015 for German novellas).
Figure 4 shows that both fantastic novels and crime fiction have a significantly higher median for proportion of direct-speech than ‘littérature blanche’, but do not differ significantly from each other (for significance tests, we used the non-parametric Kruskal-Wallis test at a significance level of 1%).
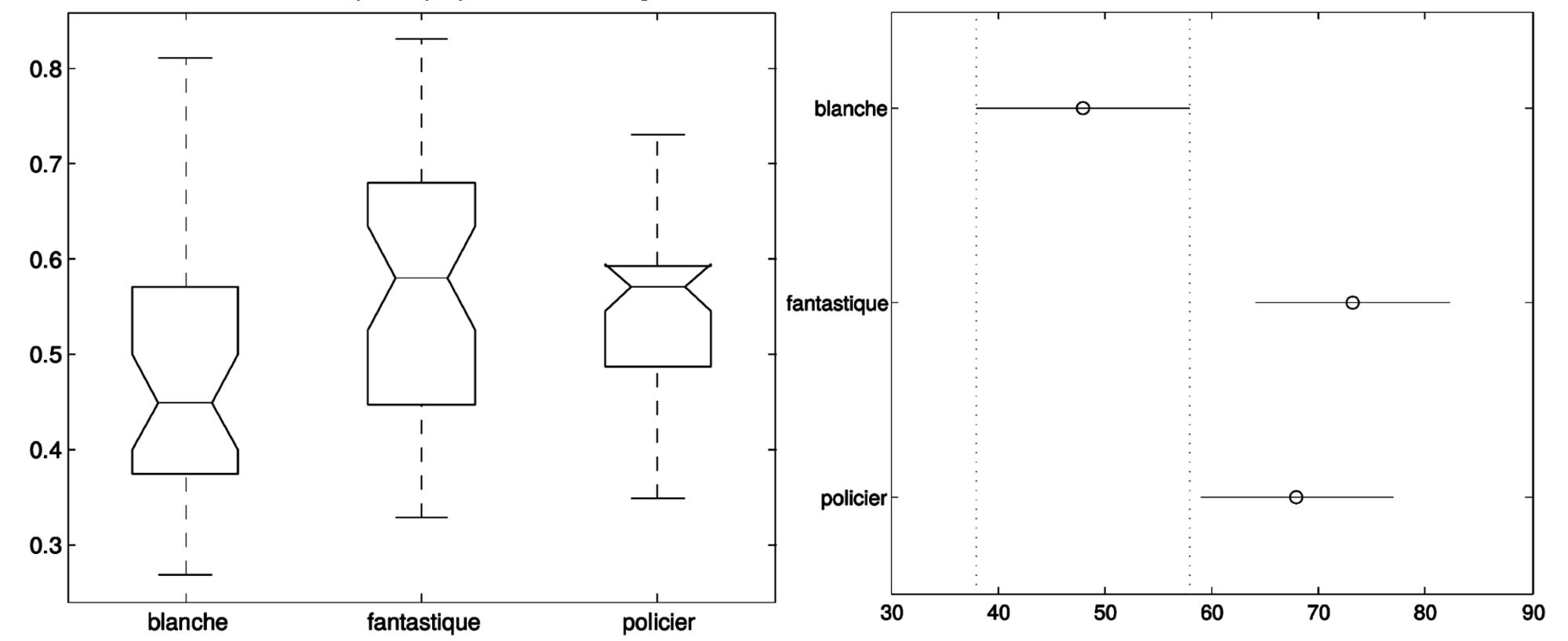
Figure 5 shows that only the ratios for the 1850s and the 1880s have a significantly differing level. However, because the decades do not have perfectly balanced subgenre proportions, this is probably due to a subgenre imbalance rather than an effect of the time period.
7. Conclusions and Future Work
Using a wide range of linguistic markers allows the reliable identification of direct speech, even in the absence of clear typographic markers. Performance is excellent to good (F1-score of 0.94 on the gold standard, weighted average success rate of 0.844 on unseen texts). Using our method reveals that nineteenth-century French novels contain a large proportion of sentences with direct speech (61% on average). Also, there are previously unseen differences in direct speech proportion for subgenre, but not for time period.
For future work, we plan to use several strategies to improve performance. One is to add more sequential information to our set of features. Examples include the position, inside a sentence, of certain lexical or typographical features as well as linguistic cues preceding and following direct speech. Also, we plan to expand our corpus to make it more balanced in terms of genres and decades. This will allow us to discover genre-related patterns of interest to literary historians in a more reliable manner and assess their significance with more confidence.
8. Supplementary material
Supplementary material can be found at: https://github.com/cligs/projects/tree/master/2016/dh.
9. Annex A: Features used
List of features used, sorted by descending rank by a one-rule classifier.
average merit average rank attribute
74.028 +- 0.168 1 +- 0 79 SPEECHSIGN
71.743 +- 0.16 2 +- 0 57 VER:impf
65.847 +- 0.234 3 +- 0 54 VER:pres
63.893 +- 0.155 4 +- 0 55 VER:simp
63.248 +- 0.136 5 +- 0 6 PUNCMARKDOT
59.48 +- 0.12 6 +- 0 29 MATCHINGPPER_SON
58.835 +- 0.094 7.7 +- 0.64 30 MATCHINGPPER_SES
58.695 +- 0.208 8.1 +- 0.94 24 MATCHINGPPER_IL
58.713 +- 0.104 8.4 +- 0.92 35 VERB_MOTION
58.364 +- 0.083 10.6 +- 0.49 28 MATCHINGPPER_SA
58.344 +- 0.417 10.8 +- 1.78 7 SENTENCELENGTH
58.172 +- 0.078 11.7 +- 0.46 61 VER:subi
57.492 +- 0.091 14 +- 1.41 25 MATCHINGPPER_ELLE
57.422 +- 0.103 14.5 +- 1.36 44 VERB_PERCEPTION
57.387 +- 0.248 14.9 +- 1.51 50 INNERSUBCLAUSE
57.356 +- 0.4 15.8 +- 2.09 48 UNKNOWNLEMMA
57.213 +- 0.07 16.5 +- 1.02 31 MATCHINGPPER_LEUR
57.143 +- 0.162 17.3 +- 1.1 60 VER:ppre
56.672 +- 0.042 20.2 +- 0.98 36 VERB_BODY
56.672 +- 0.115 21 +- 1.84 52 VER:cond
56.62 +- 0.136 21.7 +- 2.1 40 VERB_EMOTION
56.567 +- 0.072 22.3 +- 1.19 26 MATCHINGPPER_ILS
56.497 +- 0.033 23.9 +- 1.3 41 VERB_COGNITION
56.428 +- 0.044 25 +- 1 46 VERB_CONSUMPTION
56.201 +- 0.005 34.5 +- 4.06 20 MATCHINGPPER_VOTRE
56.339 +- 0.176 35.4 +-18.69 32 COMMAS
56.201 +- 0.005 35.8 +- 4.19 21 MATCHINGPPER_VOS
56.201 +- 0.005 35.8 +- 6.4 22 MATCHINGPPER_TOI
56.201 +- 0.005 36.3 +- 4.2 17 MATCHINGPPER_TES
56.201 +- 0.005 37.6 +- 7.35 5 PUNCMARKCOLON
56.195 +- 0.018 37.7 +-13.33 18 MATCHINGPPER_NOTRE
56.201 +- 0.005 38.2 +- 3.16 23 MATCHINGPPER_MOI
56.424 +- 0.296 38.4 +-25.85 47 VERB_COMMUNICATION
56.201 +- 0.005 38.6 +- 6.45 4 PUNCMARKEXCL
56.201 +- 0.005 38.7 +- 3.44 16 MATCHINGPPER_TON
56.201 +- 0.005 39.4 +- 4.82 15 MATCHINGPPER_TA
56.201 +- 0.005 39.6 +- 6.45 3 PUNCMARKQUSTION
56.201 +- 0.005 40.2 +- 8.81 8 MATCHINGPPER_JE
56.201 +- 0.005 41.8 +-10.17 9 MATCHINGPPER_TU
56.201 +- 0.005 43.5 +- 9.19 10 MATCHINGPPER_NOUS
56.201 +- 0.005 43.5 +- 2.84 13 MATCHINGPPER_MON
56.201 +- 0.005 44.6 +- 4.43 12 MATCHINGPPER_MA
56.201 +- 0.005 44.7 +- 6.47 11 MATCHINGPPER_VOUS
56.261 +- 0.436 45.6 +-27.28 1 AmmountOfPPER
56.201 +- 0.005 45.8 +- 9.65 75 INTERJECTION_FI
56.201 +- 0.005 48 +-14.72 76 INTERJECTION_HEP
56.201 +- 0.005 50.2 +- 9.34 73 INTERJECTION_EH
56.201 +- 0.005 50.2 +- 6.27 74 INTERJECTION_EUH
56.201 +- 0.005 51.3 +- 3.66 81 INTERJECTION_MADAME
56.203 +- 0.08 51.3 +-23.56 37 VERB_COMPETITION
56.201 +- 0.005 52.1 +-15.75 58 VER:infi
56.201 +- 0.005 52.3 +-16.54 56 VER:futu
56.201 +- 0.005 53 +- 8.91 78 INTERJECTION_OUSTE
56.201 +- 0.005 54.7 +-17.43 34 VERB_CONTACT
56.162 +- 0.116 55.6 +-18.7 33 VERB_WEATHER
56.201 +- 0.005 56.9 +- 6.55 64 INTERJECTION_OH
56.201 +- 0.005 57.3 +- 4.5 63 INTERJECTION_AH
56.135 +- 0.087 58 +-24.31 19 MATCHINGPPER_NOS
56.193 +- 0.015 58.7 +-13.46 77 INTERJECTION_OUF
56.201 +- 0.005 59.3 +- 9.42 67 INTERJECTION_HÉLAS
56.143 +- 0.07 59.6 +-16.69 14 MATCHINGPPER_MES
56.201 +- 0.005 59.9 +- 4.5 42 VERB_STATIVE
56.201 +- 0.005 60.2 +- 2.64 62 VER:subp
56.201 +- 0.005 60.6 +- 8.39 71 INTERJECTION_CHUT
56.201 +- 0.005 62 +- 6.36 70 INTERJECTION_HEM
56.193 +- 0.015 62.5 +-10.87 66 INTERJECTION_HEIN
56.197 +- 0.011 62.6 +- 8 65 INTERJECTION_HÉ
56.201 +- 0.005 62.7 +- 5.87 51 DEIKTIKA
56.201 +- 0.005 63 +- 4.07 80 INTERJECTION_MONSIEUR
56.201 +- 0.005 63 +-11.79 53 VER:impe
56.005 +- 0.298 63.8 +-24.78 38 VERB_POSSESSION
56.201 +- 0.005 64 +- 5.67 39 VERB_SOCIAL
56.201 +- 0.005 64.3 +- 4.86 45 VERB_CHANGE
56.197 +- 0.013 64.7 +- 8.74 68 INTERJECTION_BAH
56.201 +- 0.005 64.7 +- 5.27 59 VER:pper
56.197 +- 0.015 65.2 +- 7.08 69 INTERJECTION_HOLÀ
56.139 +- 0.062 66.7 +-20.16 27 MATCHINGPPER_ELLES
56.183 +- 0.008 71.8 +- 5.23 72 INTERJECTION_BRAVO
56.005 +- 0.121 74.2 +- 9.41 43 VERB_CREATION
56.079 +- 0.038 77.4 +- 1.56 2 AmmountOfDET
55.99 +- 0.142 78.1 +- 3.73 49 POSNPP
10. Annex B: Text collection
| author-name | title | year | subgenre | narration |
| Balzac | Pierrette | 1840 | blanche | heterodiegetic |
| Balzac | TenebreuseAffaire | 1841 | policier | heterodiegetic |
| Balzac | AlbertSavarus | 1842 | blanche | heterodiegetic |
| Sue | MysteresParis02 | 1842 | fantastique | heterodiegetic |
| Sue | MorneDiable | 1842 | fantastique | heterodiegetic |
| Sue | MysteresParis01 | 1842 | fantastique | heterodiegetic |
| FevalPP | LoupBlanc | 1843 | blanche | heterodiegetic |
| Dumas | Eppstein | 1843 | fantastique | heterodiegetic |
| FevalPP | MysteresLondres1 | 1843 | policier | heterodiegetic |
| FevalPP | FanfaronsRoi | 1843 | blanche | heterodiegetic |
| FevalPP | MysteresLondres3 | 1843 | policier | heterodiegetic |
| Sue | MysteresParis04 | 1843 | fantastique | heterodiegetic |
| Sue | MysteresParis05 | 1843 | fantastique | heterodiegetic |
| Sue | JuifErrant | 1844 | fantastique | heterodiegetic |
| Sand | PecheAntoine | 1845 | blanche | heterodiegetic |
| Sue | PaulaMonti | 1845 | fantastique | heterodiegetic |
| FevalPP | Quittance2Galerie | 1846 | blanche | heterodiegetic |
| Sand | LucreziaFloriani | 1846 | blanche | homodiegetic |
| Balzac | CousineBette | 1846 | blanche | heterodiegetic |
| Gautier | PartieCarrée | 1848 | fantastique | heterodiegetic |
| Sue | MysteresPeuple02 | 1849 | fantastique | heterodiegetic |
| Dumas | Fantômes | 1849 | fantastique | homodiegetic |
| Dumas | Olifus | 1849 | fantastique | homodiegetic |
| Dumas | ColliersVelours | 1850 | fantastique | heterodiegetic |
| Sue | MysteresPeuple03 | 1850 | fantastique | heterodiegetic |
| Sue | MysteresPeuple04 | 1850 | fantastique | heterodiegetic |
| Sue | MysteresPeuple07 | 1851 | fantastique | heterodiegetic |
| Sue | MysteresPeuple06 | 1851 | fantastique | heterodiegetic |
| Aurevilly | Ensorcelée | 1852 | fantastique | homodiegetic |
| Ponson | Baronne | 1852 | fantastique | heterodiegetic |
| FevalPP | ReineEpees | 1852 | blanche | heterodiegetic |
| Ponson | FemmeImmortelle | 1852 | fantastique | heterodiegetic |
| Sue | MysteresPeuple09 | 1853 | fantastique | heterodiegetic |
| Sue | MysteresPeuple08 | 1853 | fantastique | heterodiegetic |
| Sue | MysteresPeuple11 | 1854 | fantastique | heterodiegetic |
| Sue | MysteresPeuple10 | 1854 | fantastique | heterodiegetic |
| Sue | MysteresPeuple12 | 1855 | fantastique | heterodiegetic |
| FevalPP | MadameGilBlas | 1856 | blanche | homodiegetic |
| Gautier | Avatar | 1856 | fantastique | heterodiegetic |
| FevalPP | Louve2 | 1856 | blanche | heterodiegetic |
| Sue | MysteresPeuple13 | 1856 | fantastique | heterodiegetic |
| Gautier | RomanMomie | 1857 | fantastique | heterodiegetic |
| Sue | MysteresPeuple16 | 1857 | fantastique | heterodiegetic |
| Dumas | MeneurLoups | 1857 | fantastique | heterodiegetic |
| Sue | MysteresPeuple15 | 1857 | fantastique | heterodiegetic |
| Ponson | ClubValets2 | 1858 | policier | heterodiegetic |
| Ponson | ExploitsRocambole3 | 1859 | policier | heterodiegetic |
| Ponson | ExploitsRocambole2 | 1859 | policier | heterodiegetic |
| Ponson | ExploitsRocambole1 | 1859 | policier | heterodiegetic |
| Sand | ElleLui | 1859 | blanche | heterodiegetic |
| Ponson | Chevaliers | 1860 | policier | heterodiegetic |
| Féval | Ténèbre | 1860 | fantastique | heterodiegetic |
| FevalPP | ChevalierTenebre | 1861 | fantastique | homodiegetic |
| Aimard | RodeursFrontieres | 1861 | blanche | heterodiegetic |
| Hugo | Miserables1Fantine | 1862 | blanche | heterodiegetic |
| Ponson | TestamentGrainDeSel | 1862 | policier | heterodiegetic |
| About | OreilleCassée | 1862 | fantastique | heterodiegetic |
| Villiers | Isis | 1862 | fantastique | heterodiegetic |
| FevalPP | HabitsNoirs1 | 1863 | policier | heterodiegetic |
| Aurevilly | PrêtreMarié | 1864 | fantastique | homodiegetic |
| Féval | Vampire | 1865 | fantastique | homodiegetic |
| Gaboriau | Lerouge | 1865 | policier | heterodiegetic |
| FevalPP | HabitsNoirs2Coeur | 1865 | policier | heterodiegetic |
| Ponson | Breda | 1866 | fantastique | heterodiegetic |
| Ponson | ResurrectionRocambole2 | 1866 | policier | heterodiegetic |
| Verne | CapitaineHatteras | 1866 | blanche | heterodiegetic |
| Ponson | DernierMot3 | 1867 | policier | heterodiegetic |
| Ponson | DernierMot4 | 1867 | policier | heterodiegetic |
| Gaboriau | EsclavesParis2 | 1867 | policier | heterodiegetic |
| Ponson | DernierMot2 | 1867 | policier | heterodiegetic |
| Ponson | MiseresLondres3 | 1868 | policier | heterodiegetic |
| Aimard | Ourson | 1868 | blanche | heterodiegetic |
| Ponson | MiseresLondres2 | 1868 | policier | heterodiegetic |
| Ponson | MiseresLondres4 | 1868 | policier | heterodiegetic |
| FevalPP | HabitsNoirs3Rue | 1868 | policier | heterodiegetic |
| Ponson | FéeAuteuil | 1868 | fantastique | heterodiegetic |
| Flaubert | Education | 1869 | blanche | heterodiegetic |
| FevalPP | HabitsNoirs4Arme | 1869 | policier | heterodiegetic |
| FevalPP | HabitsNoirs5Maman | 1869 | policier | heterodiegetic |
| Gouraud | EnfantsFerme | 1869 | blanche | heterodiegetic |
| Gaboriau | MonsieurLecoq2 | 1869 | policier | heterodiegetic |
| Zola | FortuneRougon | 1870 | blanche | heterodiegetic |
| Ponson | CordePendu1 | 1870 | policier | heterodiegetic |
| Ponson | CordePendu2 | 1870 | policier | heterodiegetic |
| Gaboriau | VieInfernale2 | 1870 | policier | heterodiegetic |
| Gaboriau | Degringolade1 | 1872 | policier | heterodiegetic |
| Gaboriau | Degringolade3 | 1872 | policier | heterodiegetic |
| Gaboriau | Degringolade2 | 1872 | policier | heterodiegetic |
| Gaboriau | CordeCou2 | 1873 | policier | heterodiegetic |
| Zola | VentreParis | 1873 | blanche | heterodiegetic |
| Gaboriau | CordeCou1 | 1873 | policier | heterodiegetic |
| Gaboriau | Argent1 | 1874 | policier | heterodiegetic |
| Gaboriau | Argent2 | 1874 | policier | heterodiegetic |
| FevalPP | VilleVampire | 1875 | fantastique | homodiegetic |
| Zola | AbbeMouret | 1875 | blanche | heterodiegetic |
| Verne | HectorServadac | 1877 | fantastique | heterodiegetic |
| Malot | Cara | 1878 | blanche | heterodiegetic |
| AimardAuriac | AigleNoirDacotahs | 1878 | blanche | heterodiegetic |
| Stolz | SecretLaurent | 1878 | blanche | heterodiegetic |
| FevalPP | HommeSansBras | 1881 | policier | heterodiegetic |
| Loti | RomanSpahi | 1881 | blanche | heterodiegetic |
| Boisgobey | Omnibus | 1881 | policier | heterodiegetic |
| Gaboriau | AmoursEmpoisonneuse | 1881 | policier | heterodiegetic |
| Stolz | Mesaventures | 1881 | blanche | heterodiegetic |
| FevalPP | HistoireRevenants | 1881 | fantastique | heterodiegetic |
| Gouraud | ChezGrandMere | 1882 | blanche | heterodiegetic |
| Aurevilly | HistoireSans | 1882 | fantastique | heterodiegetic |
| Maupassant | UneVie | 1883 | blanche | heterodiegetic |
| Rachilde | MVénus | 1884 | fantastique | heterodiegetic |
| Boisgobey | Voilette | 1885 | policier | heterodiegetic |
| Zola | Germinal | 1885 | blanche | heterodiegetic |
| Ohnet | GrandeMarnière | 1885 | blanche | heterodiegetic |
| Zola | Oeuvre | 1886 | blanche | heterodiegetic |
| Villiers | EveFuture | 1886 | fantastique | heterodiegetic |
| Boisgobey | RubisOngle | 1886 | policier | heterodiegetic |
| Malot | Zyte | 1886 | blanche | heterodiegetic |
| Loti | PecheurIslande | 1886 | blanche | heterodiegetic |
| Mary | RogerLaHonte | 1886 | blanche | heterodiegetic |
| Malot | Conscience | 1888 | blanche | heterodiegetic |
| Boisgobey | OeilChat1 | 1888 | policier | heterodiegetic |
| Boisgobey | Chat2 | 1888 | policier | heterodiegetic |
| Gouraud | QuandGrande | 1888 | blanche | heterodiegetic |
| Boisgobey | MainFroide | 1889 | blanche | heterodiegetic |
| Boisgobey | Opera2 | 1889 | policier | heterodiegetic |
| Boisgobey | MainFroide | 1889 | policier | heterodiegetic |
| Boisgobey | Opera1 | 1889 | policier | heterodiegetic |
| Boisgobey | DoubleBlanc | 1889 | policier | heterodiegetic |
- Allison, S., Heuser, R., Jockers, M. L., Moretti, F. and Witmore, M. (2011). Quantitative Formalism: An Experiment (Stanford Literary Lab, Pamphlet 1). Stanford: Standford Literary Lab.
- Breiman, L. (2001). Random Forests. Machine Learning, 45(1): 5–32.
- Brunner, A. (2015). Automatische Erkennung von Redewiedergabe: Ein Beitrag Zur Quantitativen Narratologie. (Narratologia: Contibutions to Narrative Theory Band 47). Berlin; Boston: De Gruyter.
- Chang, C.-C. and Lin, C.-J. (2011). LIBSVM: A library for support vector machines. ACM Transactions on Intelligent Systems and Technology, 2(3): 1-27.
- Cohen, W. W. (1995). Fast Effective Rule Induction. Twelfth International Conference on Machine Learning. Morgan Kaufmann, pp. 115–23.
- Durrer, S. (1994). Le dialogue romanesque. Style et structure. Geneva: Droz.
- Elson, D. K. and McKeown, K. R. (2010). Automatic Attribution of Quoted Speech in Literary Narrative. Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence (AAAI-10).
- Genette, G. (1980). Narrative Discourse. An Essay in Method. Oxford: Blackwell.
- Iosif, E. and Mishra, T. (2014). From Speaker Identification to Affective Analysis: A Multi-Step System from Analyzing Children Stories. Proceedings of the Third Workshop on Computational Linguistics for Literature, pp. 40–49.
- John, G. H. and Langley, P. (1995). Estimating Continuous Distributions in Bayesian Classifiers. Eleventh Conference on Uncertainty in Artificial Intelligence. San Mateo: Morgan Kaufmann, pp. 338–45.
- Krestel, R., Bergler, S. and Witte, R. (2008). Minding the Source: Automatic Tagging of Reported Speech in Newspaper Articles. ELRA, Proceedings of the Sixth International Language Resources and Evaluation Conference.
- Leech, G. N. and Short, M. (1981). Style in Fiction: A Linguistic Introduction to English Fictional Prose. London; New York: Longman.
- McCallum, A. K. (2002). MALLET: A Machine Learning for Language Toolkit.
- Sarmento, L. and Nunes, S. (2009). Automatic Extraction of Quotes and Topics from News Feeds. Proceedings of DSIE’09 - 4th Doctoral Symposium of Informatics Engineering.
- Weiser, S. and Watrin, P. (2012). Extraction of Unmarked Quotations in Newspapers. Proceedings of the Eight International Conference on Language Resources and Evaluation.