Authors: David L. Hoover
Category: Paper:Long Paper
Keywords: character dialogue, computational stylistics, text-analysis
Textual Variation, Text-Randomization, and Microanalysis
Computational stylistics often analyzes style variation, including chronological change and the dialogue or narration of multiple characters or narrators (Craig 1999; Stamou 2008; McKenna and Antonia 1996; Stewart 2003; Burrows 1987; Hoover 2003, 2007). Here I suggest it is sometimes desirable to omit parts of texts, or to randomize a text to mask some variation, either analyzing parts of texts in random order or truncating such parts to create a word list based on equal amounts of text (see also Burrows, 1992).
Analyzing Doyle’s The Hound of the Baskervilles, shows that two sections of Holmes’s dialogue and one of Baskerville’s fail to cluster correctly, but both failures likely result from intra-textual variation that should not influence the analysis. Holmes’s outlier sections are a retrospective explanation more like narration than dialogue. This genre difference disrupts Holmes’s otherwise strongly consistent voice. I have similarly suggested ignoring the final “summing up” chapter of The Waves when analyzing its six narrative voices (Hoover forthcoming). Baskerville’s problematic section is largely a conversation with Barrymore, which may cause their voices to merge and their sections to cluster.
Special pleading in the face of apparent failure seems potentially illegitimate, but removing Holmes’s retrospective “dialogue” leaves the rest consistently clustered. Furthermore, Holmes’s dialogue from other stories clusters perfectly with his normal dialogue from Hound, so that inter-textual consistency supports an intra-textual argument. Retesting Hound with Baskerville’s dialogue randomly sorted clusters his three sections separately from Barrymore’s section, which forms its own cluster. But such randomizing to dampen intra-textual variation seems questionable. Will less distinctive voices cluster with these homogenized parts? Will randomization produce specious clustering of sections that are not “really” consistent in style?
Consider the nine fairly distinct main narrators in Collins’s The Moonstone (Hoover, Culpeper, and O’Halloran, 2014). Here, randomizing the parts greatly improves accuracy, correctly clustering all sections by all narrators over a wide range of analyses. Normal analysis of Faulkner’s As I Lay Dying clusters Darl’s and Vardaman’s sections correctly and clusters all of Tull’s sections with Cash’s section over a wide range of analyses (Hoover, 2010), but randomizing each character’s narrative correctly clusters all the characters, even when divided into much shorter sections.
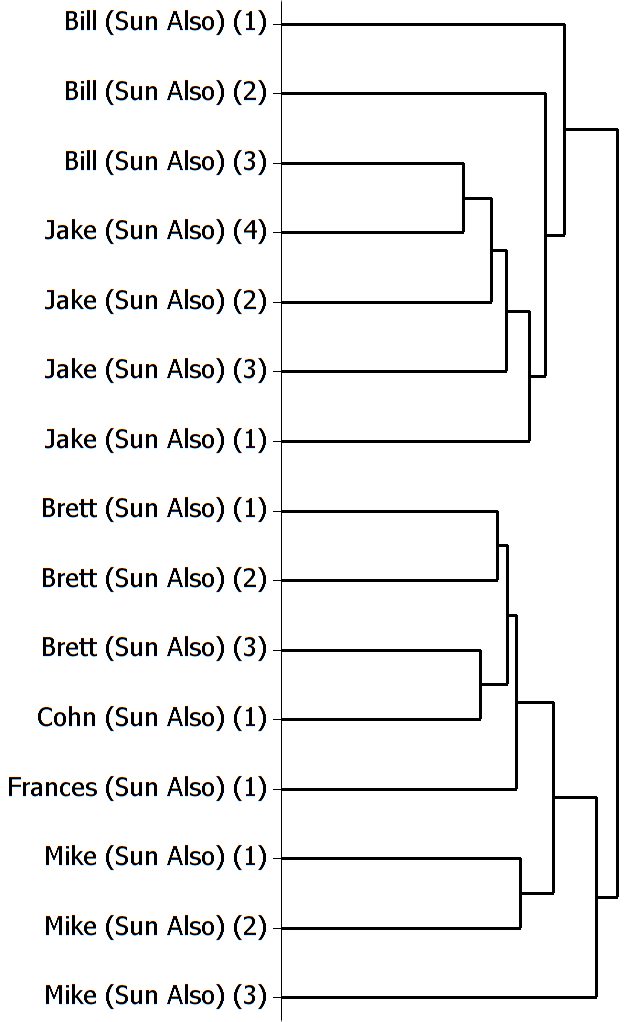
What about less distinct character parts? Randomization only slightly improves results for the letter writers in The Coquette (an epistolary novel), showing that randomization does not always produce artificial consistency. Jake and Brett from Hemingway’s The Sun Also Rises are memorable characters, yet their dialogue does not cluster very consistently in standard analyses, never approaching the success with Collins’s or Faulkner’s narrators . Figure 1 shows the most accurate clustering, based on the 700 MFW (most frequent words); all other analyses are weaker. Randomizing the character parts produces the completely correct results shown in Fig. 2 for analyses based on the 400-800MFW. (Cluster analysis is an exploratory statistical method that compares the frequencies of a set of words across a set of texts to determine which texts use those words at the most similar frequencies. The further to the left that two or more texts form a cluster, the more similar they are.) Randomization transforms the poor character separation in a standard analysis of James’s The Ambassadors into a clear separation of all except Bilham, in analyses based on the 500-800MFW. The same is true for Jane Eyre, though Jane’s dialogue seems problematic, as her story ranges from childhood to adulthood in five different settings. Many more texts will have to be analyzed to determine why randomization produces varying results and where it is appropriate.

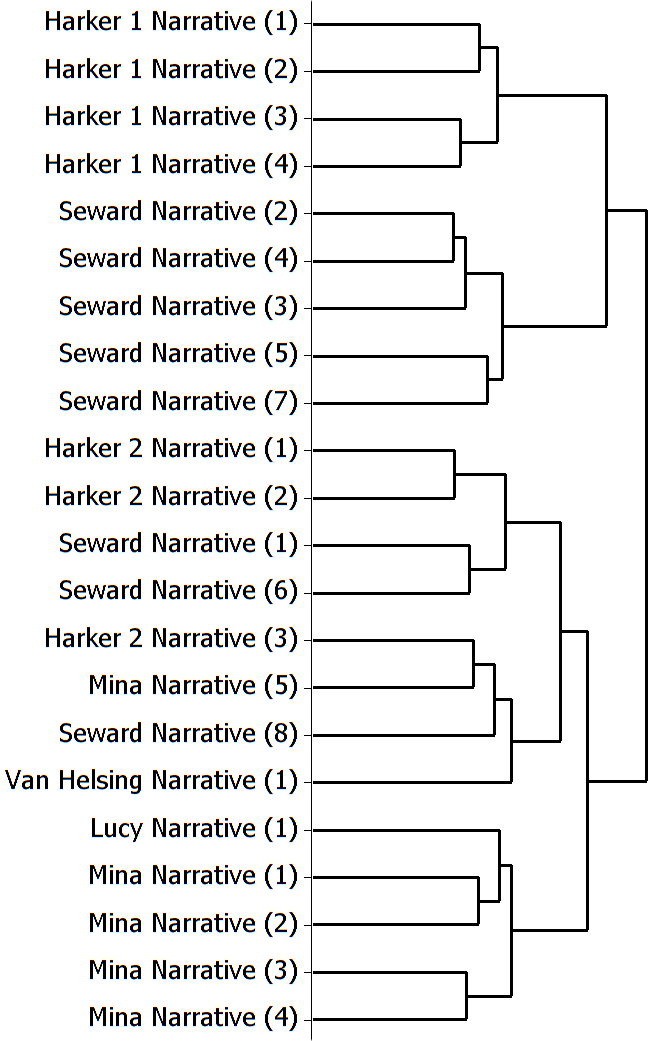
Dracula reacts similarly. A standard analysis, shown in Fig. 3, fails to cluster all the sections correctly. In the middle of the large lower cluster is a problematic mixed cluster containing Van Helsing’s single section and the final sections from Mina, Harker, and Seward. These sections narrate the race to capture Dracula at the end of the novel, and this provides an opportunity to push the question of randomization further. Because the Dracula narratives range widely in length, the full word list is skewed away from Lucy (4,400) and Van Helsing (5,200) and toward Mina (22,000), Harker 1 (19,000), Harker 2 (14,000) and Seward (35,000). A word list based on the first 6,000 words from the randomized narratives of these five characters (half from each of Harker’s) clusters the narrative much more accurately and clearly distinguishes the narratives of Lucy and Van Helsing (see Fig. 4).
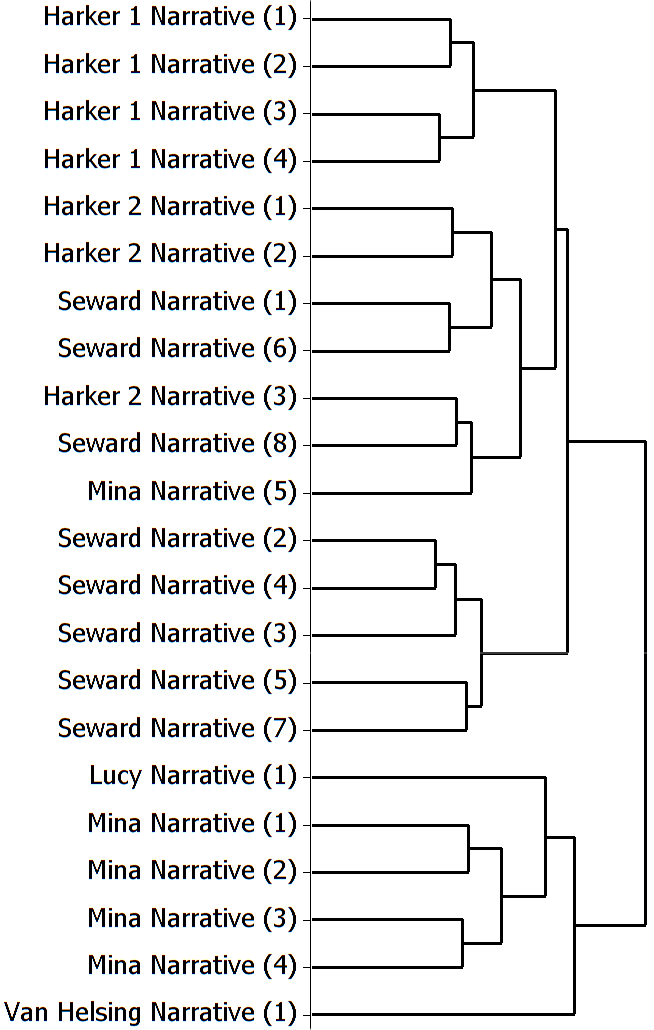
Harker’s, Mina’s, and Seward’s final sections remain clustered in Fig. 4, however. Analyzing these and Van Helsing’s in shorter sections, using a word list based on the equalized randomized parts, again improves results. Seward’s and Van Helsing’s sections cluster separately, as do Mina’s second, third, and fourth; only her first section clusters with Jonathan’s. Thus the voices remain relatively distinct, though inflected by the effects of the narrative structure. Because Mina’s wayward section is mainly a memo, its failure to cluster with the sections from her journal may also be explicable. Further analysis of the sub-genres of Dracula should provide additional insights into intra-textual variation.
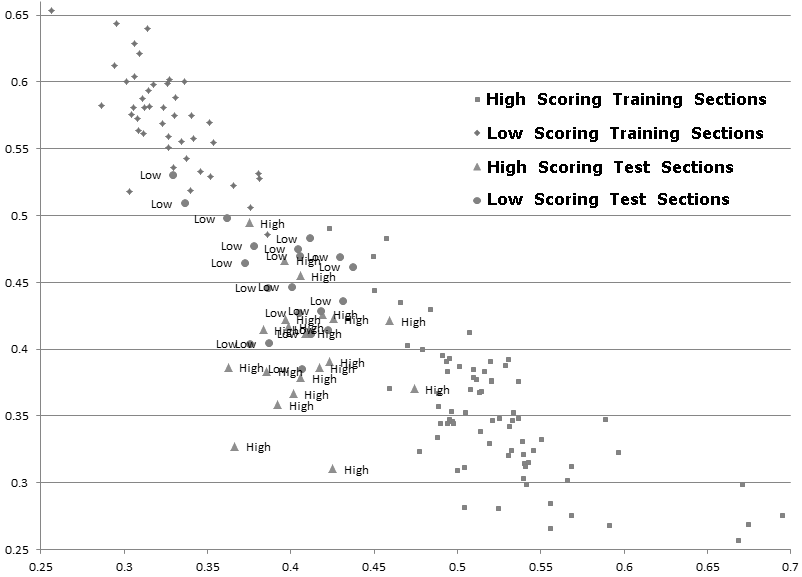
Consider now a very different kind of text posing different problems–a collection of nearly 400 high-stakes writing exams administered in U.S. high schools. These very short texts (128-1307 words) in multiple genres were written in response to a wide variety of prompts from multiple states (Jeffrey 2010; Jeffrey, Hoover, and Han 2013). This makes testing for the characteristic vocabulary of high- and low-scoring texts very challenging. Here I use a variant of Zeta, which identifies words used consistently by one group and avoided consistently by another (Burrows, 2006; Craig and Kinney, 2009; Hoover, 2013). Because the entire vocabulary is being tested, a normal word list seems appropriate. I also combine the low-scoring texts into one large text and the high-scoring texts into another, randomize the lines of each, and then compare analyses based on sections of the combined texts with analyses based on the combined and randomized texts. Holding out twenty high- and twenty low-scoring sections for testing, I use the eighty-six remaining sections for training. The combined texts distinguish high and low test texts fairly well (Fig. 5), but the combined-randomized texts greatly improve the results (Fig. 6). (The vertical and horizontal axes record the percentage of word types in each section that are characteristic of low-scoring and high-scoring texts, respectively.)
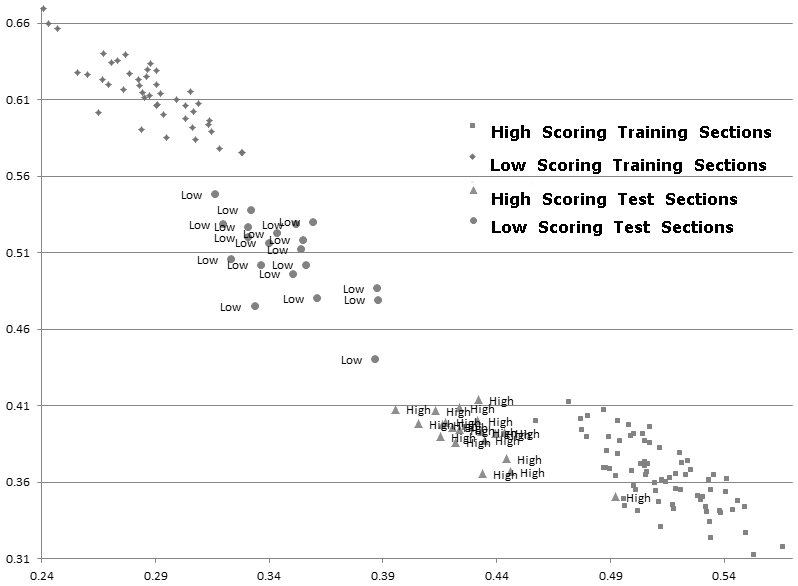
Certainly (intra-)textual variation helps to create memorable characters and narrators, and it is often crucially linked to description or narrative action. Some kinds of variation, however, can mask important kinds of consistency and unity, and a reasoned argument can be made for ignoring some sections of texts, or for analyzing them in randomized form. Alternatively, or in addition, word lists based on truncated and randomized sections also often improve results. Though the value and legitimacy of such transformations and truncations will need further study, they seem a promising line of research.
- Burrows, J. (2006). All the way through: testing for authorship in different frequency strata. Literary and Linguistic Computing, 22(1): 27-47.
- Burrows, J. (1992). Not unless you ask nicely: the interpretative nexus between analysis and information, Literary and Linguistic Computing, 7(2): 91-109.
- Burrows, J. (1987). Computation into Criticism. Oxford: Clarendon Press.
- Craig, H. (1999). Contrast and change in the idiolects of Ben Jonson characters. Computers and the Humanities, 33(3): 221-40.
- Craig, H, and Kinney, A. (Eds.) (2009). Shakespeare, Computers, and the Mystery of Authorship. Cambridge: Cambridge U Press.
- Hoover D. (forthcoming). Argument, evidence, and the limits of digital literary studies. In Gold, M. (Ed), Debates in the Digital Humanities. University of Minnesota Press.
- Hoover, D. (2013). The full-spectrum text-analysis spreadsheet, Digital Humanities 2013: Conference Abstracts. Lincoln, NE: Center for Digital Research in the Humanities, University of Nebraska, pp. 226-29.
- Hoover, D. (2007). Corpus stylistics, stylometry, and the styles of Henry James. Style, 41(2): 160-89.
- Hoover, D. (2003). Multivariate analysis and the study of style variation. Literary and Linguistic Computing, 18(4): 341-60.
- Hoover, D., Culpeper, J. and O’Halloran, K. (2014). Digital Literary Studies: Corpus Approaches to Poetry, Prose, and Drama. London: Routledge.
- Jeffrey, J. (2010). Voice, genre, and intentionality: an integrated methods study of voice criteria examined in the context of large scale-writing assessment. Diss. English Education. New York University.
- Jeffrey, J., Hoover, D. and Han, M. (2013). Lexical variation in highly and poorly rated US secondary students’ writing: implications for the common core writing standards, AERA 2013 Annual Meeting, San Francisco, April 27-May 1.
- McKenna, C. W. F. and Antonia, A. (1996). A few simple words’ of interior monologue in “Ulysses”: reconfiguring the evidence. Literary and Linguistic Computing, 11(2): 55-66.
- Stamou, C. (2008). Stylochronometry: stylistic development, sequence of composition, and relative dating. Literary and Linguistic Computing, 23(2): 181-99.
- Stewart, L. (2003). Charles Brockden Brown: quantitative analysis and literary interpretation. Literary and Linguistic Computing, 18(2): 129-38.