Authors: Valérie Beaudouin, Zeynep Pehlivan
Category: Paper:Short Paper
Keywords: network, web archives, digitized heritage, WW1, amateurs
The Great War on the Web: the Making of Citing and Referencing by Amateurs
Over the last two decades, an important amount of work has been carried out by cultural heritage institutions to make their collections available online. How are these digitized collections discovered, discussed and shared on the Web? 1
The digitized heritage around the First World War (WW1) is an ideal area for such analysis: many digitized collections, centenary anniversary (2014–2018) and an important activism around the Great War. Family, local and militant history are the main motivations of persons that get involved in the history of WW1 (Offenstadt, 2010).
Who are the users who publish or discuss around WW1 on the web? Are they amateurs, experts, academics? How do they publish, share and comment digitized documents? These questions matter for the development of Digital Humanities, but also to those in charge of managing the collections. We conduct an exploratory analysis to understand how the activity around the war is visible in the digital space.
Our research consists of two steps:
- Identification and categorization of web sites dedicated to WW1 and network analysis of the links between those sources, in order to draw an overall cartography of Web activity on WW1 and to identify the position of amateurs.
- Focus on one of the main nodes in the web cartography (a forum dedicated to WW1), to analyze the forms of circulations of digitalized documents.
We also conducted a series of semi-structured interviews with participants.
1. Corpus and methodology
The web is ephemeral: working on web archives allows us to rely on a stabilized corpus, which guaranties the reproducibility of the research (Brügger, 2013). Bibliothèque Nationale de France (BnF), in charge of archiving the French web, created a specific web archive collection dedicated to the centenary of the WW1, based on web sources chosen by librarians. The process of archiving is regularly repeated. Our research relies on the November 2014’s archive (9 698 633 Urls for a total size of 800 Gb).
The first step of our analysis consists of generating an oriented network graph on web archives to study the relations (materialized by hyperlinks) between web sources related to WW1. We can consider a link as a pragmatic activity of citing or referencing sources (documents, web sites etc.), although in our approach we are not able to qualify the exact nature and function of the link (Saemmer, 2015).
To make the large-scale graphs readable, the nodes in the graph correspond to the seed urls chosen by librarians and all the data crawled from each url is agregated to it. Librarians, in charge of web archiving, qualify the producers (or authors) of the websites. Depending on this categorization, we will distinguish institutional websites (public and official, red) and personal websites (personal and associative, blue).
2. Mapping WW1 on the Web
The network graph allows to evaluate the place of “amateurs” websites compared to institutional sources.
Basic characteristics of our network are calculated using Gephi (Bastian et al., 2009). The network consisted of 514 nodes and 3713 edges with an average degree of 7.22. The average network distance between all pairs of nodes (average path length) is 2.78 edges with a diameter (longest distance) of 8 edges. The clustering coefficient (the degree to which they tend to cluster together) is 0.27 and the modularity index is 0.28. Overall, WW1 French network is made of highly connected pages (∼2.7 edges per node) and shows small-world scale-free network properties (Humphries et al., 2008; Watts et al., 1998) with high clustering coefficient, short average path length and a degree distribution following a “power-law” (smallworldness index = 15).
More than half of the sources (52%) come from personal websites that are involved in WW1 as a serious leisure, but not as a profession. The institutional sites are less present (36 %).
To detect influential actors on our network, we use the degree centrality which is simply the number of direct relationships that an actor has, the sum of outgoing and incoming links. The network is visualized in Figure 1 by using Gephi, Force Atlas 2 algorithm (Jacomy et al., 2014) as layout with node sizes proportional to their degree centrality.
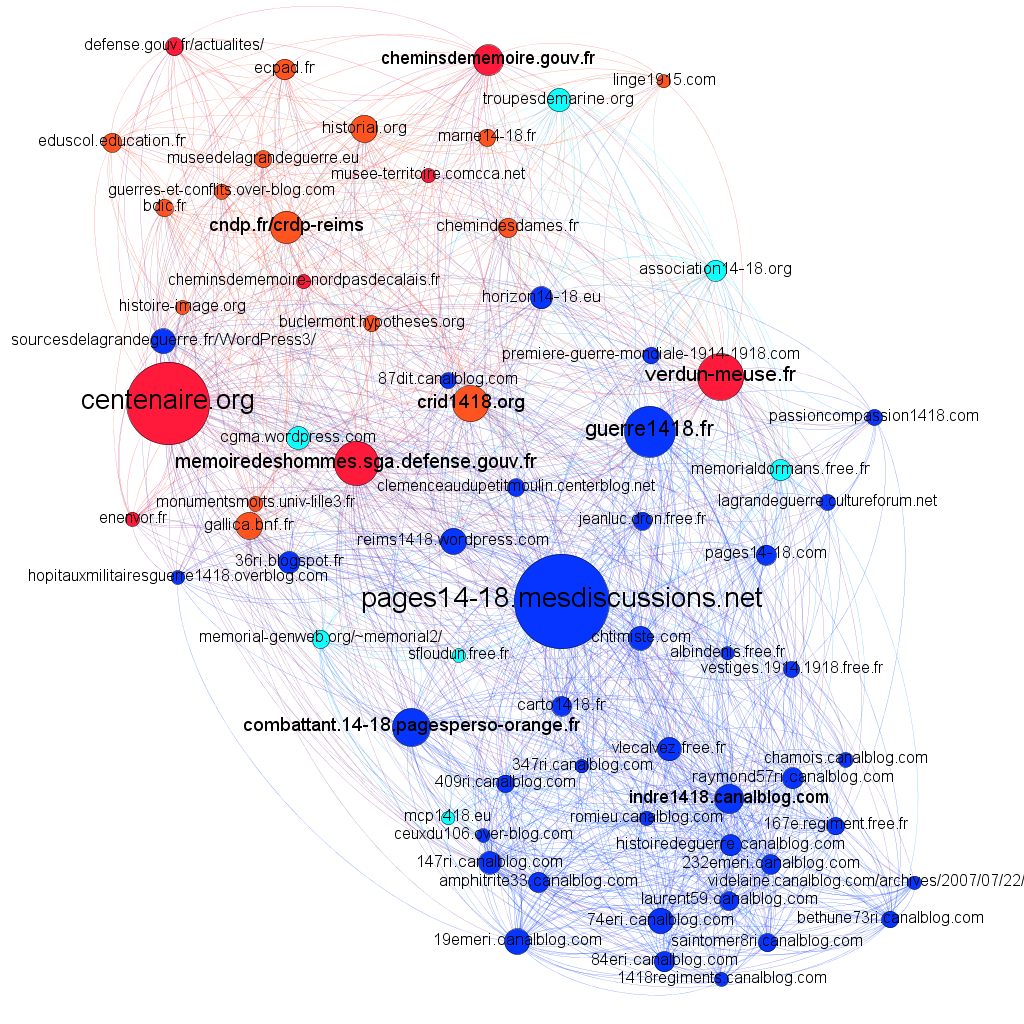
The two main actors are centenaire.org, the official site dedicated to the Centenary, on one side and pages1418.mesdiscussions.net, a web forum managed by amateurs, on the other. Around them, we can distinguish two clusters: the red gathers the institutional sites, while the blue (bottom) gathers all the personal web sites that are intensely interconnected. The forum (Pages 14-18) has a specific position: although it is immersed in the middle of the amateur sphere, it is well connected to institutional sources, because users of this forum are mediators to institutional ressources. The forum constitutes a community of practice (Lave and Wenger, 1991): questions and answers on one side and discussions on the other are two kinds of interactions that allow to share and elaborate knowledge collectively (Conein and Latapy, 2008). Thanks to the forum, a lot of personal websites emerged, each of them dedicated to a specific regiment of foot. Experts of those regiments are the authors of those website that accumate documents (public and personal documents and photographies) on each soldier, each battle, each place occupied.
Degree centrality considers only direct relationships, we also use Hubs and Authorities, known as HITS (Kleinberg, 1999) algorithm. A hub is defined as an actor that points to many other actors and an authority is defined as an actor pointed by many others. HITS algorithm calculates two scores for each actor, hub score and authority score, in a mutually reinforcing way based on the idea that a good authority must be pointed to by several good hubs while a good hub must point to several good authorities (Table 1).
| Top 5 Authorities | Authority Score | Top 5 Hubs | Hub Score |
| memoiredeshommes.sga.defense.gouv.fr | 0.0199 | pages14-18.mesdiscussions.net | 0.0379 |
| centenaire.org | 0.0135 | centenaire.org | 0.0276 |
| crid1418.org | 0.0127 | guerre1418.fr | 0.0251 |
| chtimiste.com | 0.0125 | combattant.14-18.pagesperso-orange.fr | 0.0175 |
| gallica.bnf.fr | 0.0124 | verdun-meuse.fr | 0.0163 |
Table 1 : Hubs and Authorities
Some authorities, like memoiredeshommes.sga.defense.fr and gallica.bnf.fr, have a very specific profile: as documents warehouses, they receive a lot of links but do not point to other resources. The Centenary website is at the same time a top level authority and hub. The forum, pages1418.mesdiscussions.net, and other personal websites are hubs that point to a relatively large number of authorities.
3. Forum activity of citations
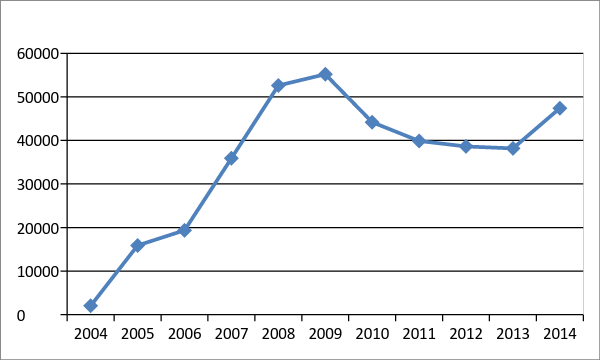
Based on the specific position of the forum, we decided to focus on it. This forum, founded in 2004 by an amateur, has gradually become a reference site in terms of exchanges and discussions on the WW1. It is a highly active platform with about 400,000 messages in 10 years and about 18,000 subscribers.
This forum was archived by BnF in January 2015 and we rely on this corpus for our work. For analysing the activity of citing, we classified the citations into four categories:
- Message_Citation: using a part of previous message
- Quote: text inserted using another source
- Links: hyperlink by using 'link' tag
- Images: hyperlink by using 'img' tag
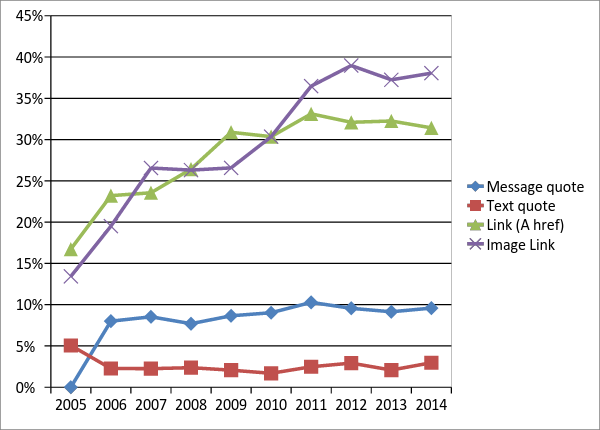
As shown by Figure 4, while the usage of quote and message_citations stays stable, the usage of links and images increases over time according to the increase of digitized documents available on line.
In the corpus, we identified 255,374 image or link citations, an average of 1 citation for 2 messages. We extracted their domain name. The ten more cited domains, which represent 60% of total links, are shown in Table 2.
| Netloc | Fréquence |
| images.mesdiscussions.net | 91990 |
| pages14-18.mesdiscussions.net | 9636 |
| www.memoiredeshommes.sga.defense.gouv.fr | 8984 |
| gallica.bnf.fr | 6721 |
| www.asoublies1418.fr | 4979 |
| usera.imagecave.com | 4274 |
| 74eri.canalblog.com | 4019 |
| www.servimg.com | 2674 |
| imageshack.us | 2592 |
| largonnealheure1418.wordpress.com | 2407 |
| perso.orange.fr | 1916 |
| www.casimages.com | 1588 |
| www.memorial-genweb.org | 1574 |
| www.hiboox.fr | 1492 |
| www.pages14-18.com | 1387 |
| pagesperso-orange.fr | 1372 |
| perso.wanadoo.fr | 1200 |
| albindenis.free.fr | 1129 |
| images.imagehotel.net | 1041 |
| images4.hiboox.com | 1016 |
Table 2. Most frequent hosts extracted from url citations
The most notable result is the importance of image hosting services. Instead of giving a direct link to an online source, people use hosting services (ex: images.mesdiscussions.net). We can estimate that more that 100 000 citations (40% of total) are of this kind where almost half of them point to images. Users are not confident with the life of web sources. They prefer to download and post the picture than to point to a link which may disappear. The image, in this case is directly available and visible into the post.
Secondly, the forum itself is the most cited website: due to his long history and intense activity, a lot of questions have already been answered. An activity of knowledge management consists in answering a question by signaling an old topic about the same topic.
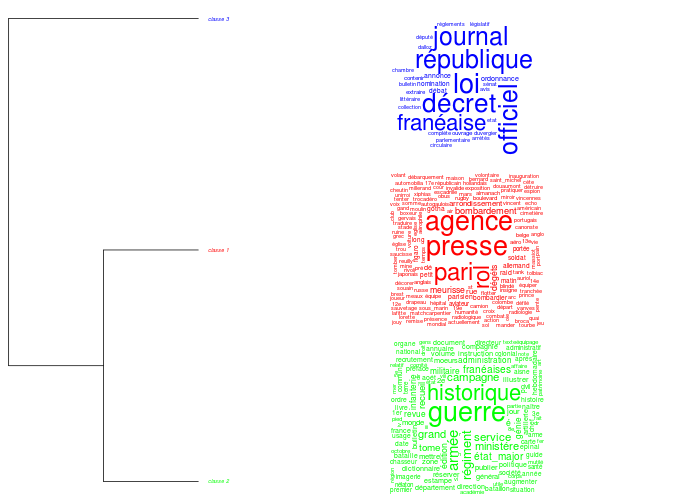
Memoire des hommes and Gallica are the most cited institutional sites. The first one is a gold mine for genealogists who search for ancestors dead during the war and for historians interested in the battles and regiment history. Gallica is a huge warehouse (4 millions of documents): there is a need to identify what kind of documents people are looking for. We extracted the titles of the documents cited and made a content analysis with Iramuteq (Reinert, 1993) (Figure 4); we identified three kinds of documents: photographs and newspapers, official documents (“journaux officiels”, “décrets”) and documents related to the history of regiments (“historiques des Régiments”) from the department of Defense.
Users of the forum also cite a lot of personal web sites dedicated to specific aspects of the war: the history of the soldiers from a specific regiment or squadron for example.
4. Conclusion
To understand what internet users do with digitized archives, we explored systematically the websites discussing WW1. We developed an original methodology combining web and text mining methods applied to web archives. This method is transferrable. It includes expert advice to qualify the relevant variables for qualifying and selecting sources.
Our analysis shows a great involvment of amateurs (more than half of the websites) in the memory of WW1. They participate to a network of personal websites that gives a specific vision of WW1, more focused on soldiers, regiments, geographic places, objects, remains of war, close to micro-history. A the core of this network, we find the forum, which is the place for interactions and discussions on documents, data, interpretations.
In doing research with digitized resources, amateurs collectively increase their professionalism. Although they do not have the status of academics, they acquire methods in exploring and citing their sources, commenting and sharing with other users. Those amateurs, in doing research with digitized resources, play a major role by discovering and citing institutional heritage documents, adding to their value and creating networks and resources.
- Bastian M., Heymann S. and Jacomy M. (2009). Gephi: an open source software for exploring and manipulating networks, International AAAI Conference on Weblogs and Social Media.
- Brügger N. (2013). Historical Network Analysis of the Web, Social Science Computer Review, 31(3): 306-21.
- Conein B. and Latapy M. (2008). Les usages épistémiques des réseaux de communication électronique: Le cas de l’Open-Source, Sociologie du Travail, 50(3): 331-52.
- Humphries, M.D. and Gurney, K. (2008). Network 'small-world-ness': A quantitative method for determining canonical network equivalence, PLoS ONE,3(4), e0002051.
- Jacomy, M., Venturini, T., Heymann, S. and Bastian, M. (2014). ForceAtlas2, a Continuous Graph Layout Algorithm for Handy Network Visualization Designed for the Gephi Software. PLoS ONE 9(6), e98679. doi:10.1371/journal.pone.0098679
Freeman, L. C. (1977). A Set of Measures of Centrality Based on Betweenness, Sociometry, 40(1): 35-41. - Kleinberg, J. (1999). Authoritative sources in a hyperlinked environment. Journal of ACM, 46(5): 604-32. DOI=http://dx.doi.org/10.1145/324133.324140
- Lave, J. and Wenger, E. (1991). Situated learning: legitimate peripheral participation, Cambridge: Cambridge University Press.
- Offenstadt, N. (2010). 14-18 aujourd’hui - La Grande Guerre dans la France contemporain, Paris: Odile Jacob.
- Reinert, M. (1993). Les “mondes lexicaux” et leur “logique” à travers l’analyse statistique d'un corpus de récits de cauchemars », Langage et société, 66: 5-39.
- Saemmer, A. (2015). Rhétorique du texte numérique: figures de la lecture, anticipations de pratiques, ENSSIB.
- Watts, D. J. et Strogatz, S. H. (1998). Collective dynamics of ‘small-world’ networks, Nature, 393(6684): 440-42.
- Wenger, E. (1998). Communities of Practice: Learning, Meaning, and Identity, Cambridge, U.K.: Cambridge University Press.
“The future of online digitized heritage: the example of the Great War” is a research project conducted by the BnF, the BDIC and Télécom ParisTech as part of the Cluster of Excellence, Pasts in the present, Investissements d'avenir, réf. ANR-11-LABX-0026-01 (Valérie Beaudouin, Philippe Chevallier, Lionel Maurel, Josselin Morvan, Zeynep Pehlivan, Peter Stirling).