Authors: Biligsaikhan Batjargal, Garmaabazar Khaltarkhuu, Akira Maeda
Category: Paper:Poster
Keywords: digital humanities, machine learning, historical documents, traditional Mongolian script
Named Entity Extraction from digitized texts of Mongolian Historical Documents in Traditional Mongolian Script
1. Abstract
In this paper, we demonstrate a named entity extraction method for digitized ancient Mongolian documents by using features of traditional Mongolian script. In the field of humanities, getting knowledge by analyzing various historical documents is an important task. There are increasing demands from Mongolian humanities researchers to perform text analysis at massive scale with prompt and accurate results. A few ancient Mongolian historical manuscripts including 1) the “Qad-un ündüsün-ü quriyangγui altan tobči neretü sudur (The Altan Tobchi or the Golden Summary: Short history of the Origins of the Khans)” a.k.a “Little” Altan Tobchi, and 2) the “Asaraġci neretü-yin teüke or Asragch nėrtiin tüükh (The Story of Asragch)”, which were written in traditional Mongolian script have been converted to digital texts and made publicly available through the traditional Mongolian script digital library (TMSDL) (Batjargal et al., 2013). Figure 1 shows a page of the “Little” Altan Tobchi in the TMSDL. The demands from Mongolian humanities researchers, as well as the lessons learned from the TMSDL have encouraged us to conduct further research in developing a new method for extracting named entities from ancient Mongolian historical documents. However, there has been little research on text mining or named entity extraction for Mongolian language and none of the research has considered text mining on ancient Mongolian historical documents due to the lack of research in those areas. Thus, we want to propose a named entity extraction method for ancient historical documents in traditional Mongolian script by employing machine learning techniques for aiming to reduce the labor-intensive analysis on historical text.

Figure 1. Screenshot of the TMSDL
In the proposed approach, an ancient Mongolian corpus gets tokenized, each token gets annotated and gold standard annotations are prepared for inputting into computer system for learning. The proposed method learns the extraction rules of personal names and place names from annotated training corpora, and then extracts named entities from ancient Mongolian texts by employing machine learning techniques (Batjargal et al., 2015).
We use the IOB2 (Ramshaw and Marcus, 1995) format for tagging tokens. Because of some unique features of traditional Mongolian script, we also use “Start/End” (SE) chunk tag set (Asahara and Matsumoto, 2003). “S” tag is attached to the first character of each word including the named entities and “E” tag to the last character. Thus, each token will include the 1) IOB2 tag and 2) SE tag.
We also consider the following features of traditional Mongolian script for differentiating personal names and place names.
- Information of the preceding and following tokens: Features are extracted by looking the context of the current, preceding, and succeeding tokens. If the preceding token is generational or dynastic information, an inherited or life-time title of nobility, or a traditional descriptive phrase, it could indicate the current token is a personal name.
- Suffix: Many living being and humankind proper names take only certain plural suffixes such as
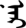 (nar/ner) and possessive suffixes (Chinggaltai, 1963). Some suffixes are visually separated from the stem of a word or other suffixes, but any attached suffixes are considered to be an integral part of the word.
(nar/ner) and possessive suffixes (Chinggaltai, 1963). Some suffixes are visually separated from the stem of a word or other suffixes, but any attached suffixes are considered to be an integral part of the word. - Beginning of a sentence: Subjects or personal names often appear at the beginning of a sentence.
- End of a token: Words with a final vowel letter ‘a’ or ‘e’ are separated visually from the preceding consonant by a narrow gap. However, the ‘a’ or ‘e’ is an integral part of the word stem.
For evaluation, we calculated precision, recall, and F-measure by the 5-fold cross-validation. To prepare the gold standard annotations, we annotated all the personal names and place names in the “Little” Altan Tobchi using the manually compiled personal and place names’ indices obtained from the “Qad-un ündüsün quriyangγui altan tobči –Textological Study” (Choimaa, 2002). For the experimental corpus, we utilized digitized text of chronological manuscripts “Little” Altan Tobchi. We utilized the LIBLINEAR with the L2-regularized L2-loss support vector classification (dual) solver (Rong-En Fan et al., 2008).
We will further improve the proposed method by considering more features by conducting various experiments with different combinations of features for checking whether the particular feature set will improve the preliminary results of 0.70 of precision, 0.57 of recall and 0.63 of F-measure or not.
- Asahara, M. and Matsumoto, Y. (2003). Japanese Named Entity Extraction with Redundant Morphological Analysis, Proceeding of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language, Stroudsburg, PA, USA, June 2003, pp. 8–15.
- Batjargal, B., Khaltarkhuu, G., Kimura, F. and Maeda, A. (2012). Developing a Digital Library of Historical Records in Traditional Mongolian Script, International Journal of Digital Library Systems, 3(1): 33–53.
- Batjargal, B., Khaltarkhuu, G., Kimura, F. and Maeda, A. (2015). An Approach to Named Entity Extraction from Mongolian Historical Documents, Proceedings of the International Conference on Culture and Computing (Culture and Computing 2015), Kyoto, Japan, October 2015, pp. 205-06.
- Chinggaltai. (1963). A Grammar of the Mongol Language. New York: Frederick Ungar Publishing Co.
- Choimaa, Sh. (2002). Qad-un űndűsűn quriyangγui altan tobči (Textological Study) vol. 1. (in Mongolian). Ulaanbaatar: Centre for Mongol Studies, National University of Mongolia, Urlakh Erdem.
- Fan, R.-E., Chang, K.–W., Hsieh, C.–J., Wang, X.–R. and Lin, C.-J. (2008). LIBLINEAR: A Library for Large Linear Classification. Journal of Machine Learning Research, 9: 1871–74.
- Ramshaw, L. A. and Marcus, M. P. (1995). Text Chunking Using Transformation-based Learning, Proceedings of the 3rd ACL Workshop on Very Large Corpora, Cambridge MA, USA, June 1995, pp. 82–94.