Authors: Andre Blessing, Jonas Kuhn
Category: Paper:Poster
Keywords: biographical data, Information extraction, NLP, crosslingual
Crosslingual Textual Emigration Analysis
The presented work describes the adaptation of a Natural Language Processing (NLP) based biographical data exploration system to a new language. We argue that such a transfer step has many characteristic properties of a typical challenge in the Digital Humanities (DH): Resources and tools of different origin and with different accuracy are combined for their use in a multidisciplinary context. Hence, we view the project context as an interesting test-bed for a few methodological considerations.
In previous work, we developed a web-based application called Textual Emigration Analysis (TEA) (Blessing and Kuhn, 2014). The system consists of two components. The import component automatically extracts emigration paths from a German Wikipedia data set. The user interface component provides several views (interactive map, aggregated tables and underlying textual content) on the extracted data. The whole application was originally designed for German Wikipedia articles and the applied NLP pipeline is based on webservices of the CLARIN-D infrastructure (Mahlow et al., 2014). Later, other German sources of biographical data were included by adapting the import component (ÖBL: Austrian Biographical Dictionary 1815-1950, and NDB: the New German Biography).
One often requested feature was the adaptation of the system to other languages. In DH research it is important to investigate different sources. As a consequence, textual data may include different languages. In particular, biographical analysis systems benefit if sources of different languages can be analysed. However, the development of such language-sensitive systems still lacks sufficient support. Therefore, the used methods should not require any knowledge of the new target language during development phase. In this work we present the adaptation process for French.

Wikipedia and Wikidata are important resources for the development of language technology tools which also holds for cross-lingual approaches. Wikidata enables a clean mapping between the different language editions of Wikipedia. Following the idea of cross-lingual distant supervision (Blessing 2012), our method consists of three steps. First, we use the results of our TEA tool to find biographical articles that include mentions of emigration paths. Subsequently, Wikidata is used to map those articles to their corresponding French articles, if they exist. Finally, we use anchor points in the text to find comparable sentences.
In most cases, emigration sentences contain geospatial and time expressions (e.g., “He emigrated in 1941 to Switzerland.” ), which can be used to find comparable sentences in the target language. We exploit the hyperlink structure of Wikipedia to recognize geospatial expressions and HeidelTime (Strötgen, 2013) to identify time expressions. The locations can be mapped through Wikidata into the target language and the atomic date representation of HeidelTime enables a simple identification of all matching sentences in the target sentence.
This results in an annotated corpus in the new target language which can be used as training data for the emigration extraction component . Each sentence of the training corpus is automatically enriched with linguistic annotations (Figure 1) which is necessary to extract features for the emigration extraction component.
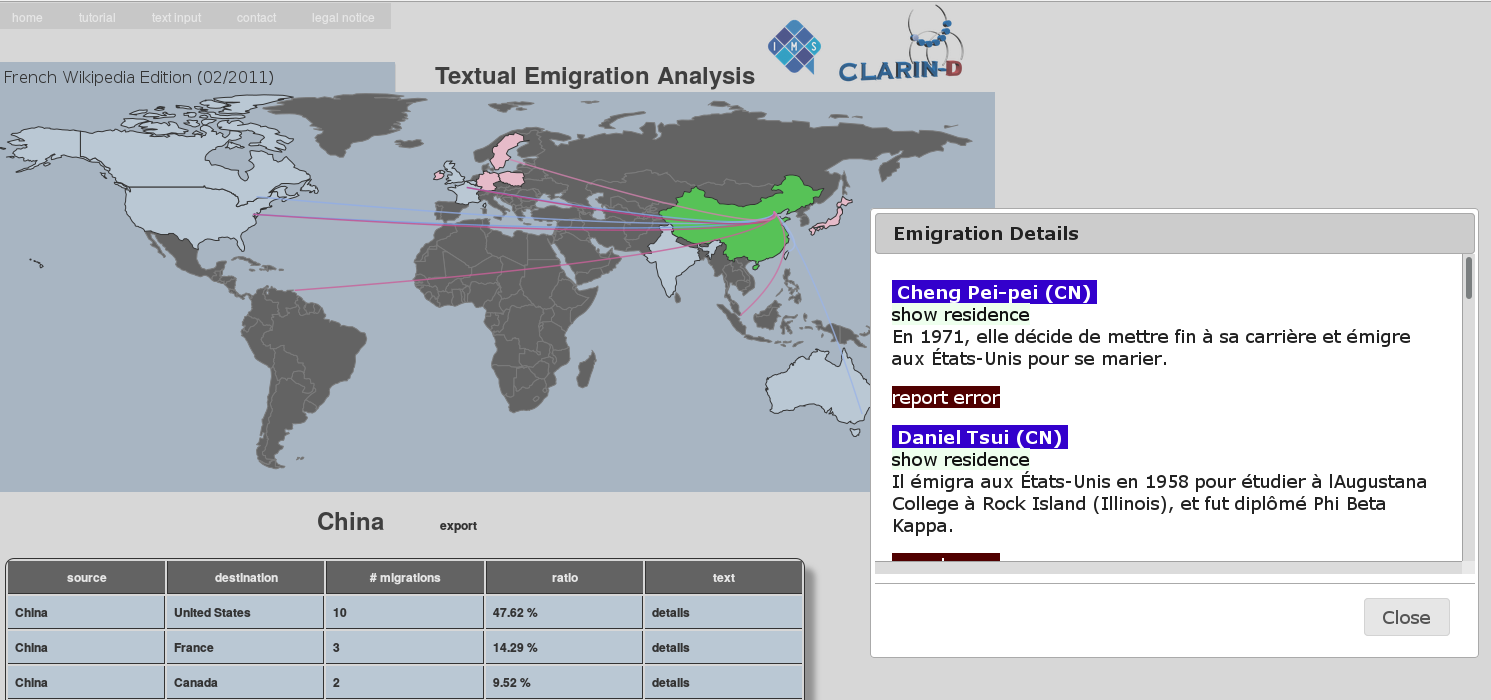
Figure 2 depicts our web-based application after integrating the automatically learned French emigration data. Our system can be accessed online: http://clarin01.ims.uni-stuttgart.de/tea
- Blessing, A. and Schüthze, H. (2012). Crosslingual Distant Supervision for Extracting Relations of Different Complexity. Proceedings of the twenty-first ACM International Conference on Information and Knowledge Manageme2012 ( CIKM-12 ), ACM, New York, NY, USA.
- Blessing, A. and Kuhn, J. (2014). Textual Emigration Analysis (TEA). Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC'14) European Language Resources Association (ELRA), Reykjavik, Iceland.
- Mahlow, C., Eckart, K., Stegmann, J., Blessing, A., Thiele, G., Gärtner, M. and Kuhn, J. (2014). Resources, Tools and Applications at the CLARIN Center Stuttgart. Proceedings of the 12th Konferenz zur Verarbeitung natürlicher Sprache (KONVENS 2014).
- Strötgen, J. and Gertz, M. (2013). Multilingual and Cross-domain Temporal Tagging. Language Resources and Evaluation. Springer 47(2): 269-98.