Authors: Christian Chiarcos, Frank Abromeit, Christian Fäth, Max Ionov
Category: Paper:Short Paper
Keywords: etymology, dictionaries, Turkic, LLOD, Lemon
Etymology Meets Linked Data. A Case Study In Turkic
1. Linking Etymological Dictionaries
When studying low-resource languages, historical documents or dialectal variation, researchers often face the problem that lexical resources are sparse, dated, or simply unavailable. At the moment, the problem is addressed by different initiatives to either aggregate language resources 1 in a central repository or to collect metadata about them 2. The availability of this huge and diverse amount of material, often in different formats, and with a highly specialized focus on selected language varieties, poses the challenge how to access and search this wealth of information. Our project aims to address both aspects:
- uniform access to lexical resources. At the moment, most resources are distributed across different providers. Platforms to query or browse this data are available, but they use different representation formalisms and remain isolated from each other. We employ Linked Data to develop interoperable representations to access distributed resources in a uniform fashion.
- search across multilingual resources. We are not only interested in a specific language, but also, in related varieties: Much of the material we have is sparse, and we can address gaps in our lexical knowledge by consulting background information about form and meaning of possible cognates in other languages.
The project will implement search functionalities as web services and provide a prototypical web interface that allows to query Linked Data versions of open lexical resources. As a first step towards this goal, this paper addresses representation formalisms and data modelling, illustrated for an etymological dictionary of the Turkic language family.
2. Linked Open Data
Linked (Open) Data defines rules of best practice for publishing data on the web, and since (Chiarcos et al., 2012), these rules have been increasingly applied to language resources, giving rise to the Linguistic Linked Open Data (LLOD) cloud (Chiarcos et al., 2013) 3. A linguistically relevant resource constitutes Linguistic Linked (Open) Data if (1) its elements are uniquely identifiably by means of URIs, (2) its URIs resolve via HTTP, (3) it can be accessed using web standards such as RDF and SPARQL, and (4) it includes links to other resources. It is Linguistic Linked Open Data (LLOD) if – in addition to these rules –, it is published under an open license. For etymological dictionaries, the capability to refer to and to search across distributed data sets (federation, dynamicity, ecosystem) in an interoperable way (representation, interoperability) allows to design novel, integrative approaches on accessing and using etymological databases, but only if common vocabularies and terms already established in the community are being used, re-used and extended. (Moran & Brümmer, 2013) established lemon (McCrae et al., 2011) 4 for representing etymological data. Inspired by the pre-lemon inventory (de Melo, 2014), we introduce lemon extensions for etymological relations, illustrated for the linked data edition of the Starling Turkic etymological dictionary. With further dictionaries for Turkic languages becoming available as a result of our project, these are linked with each other and with language resources from contact languages such as Mongolian, Iranian, Caucasian, Arabic, and Russian.
3. Turkic Etymology in Starling
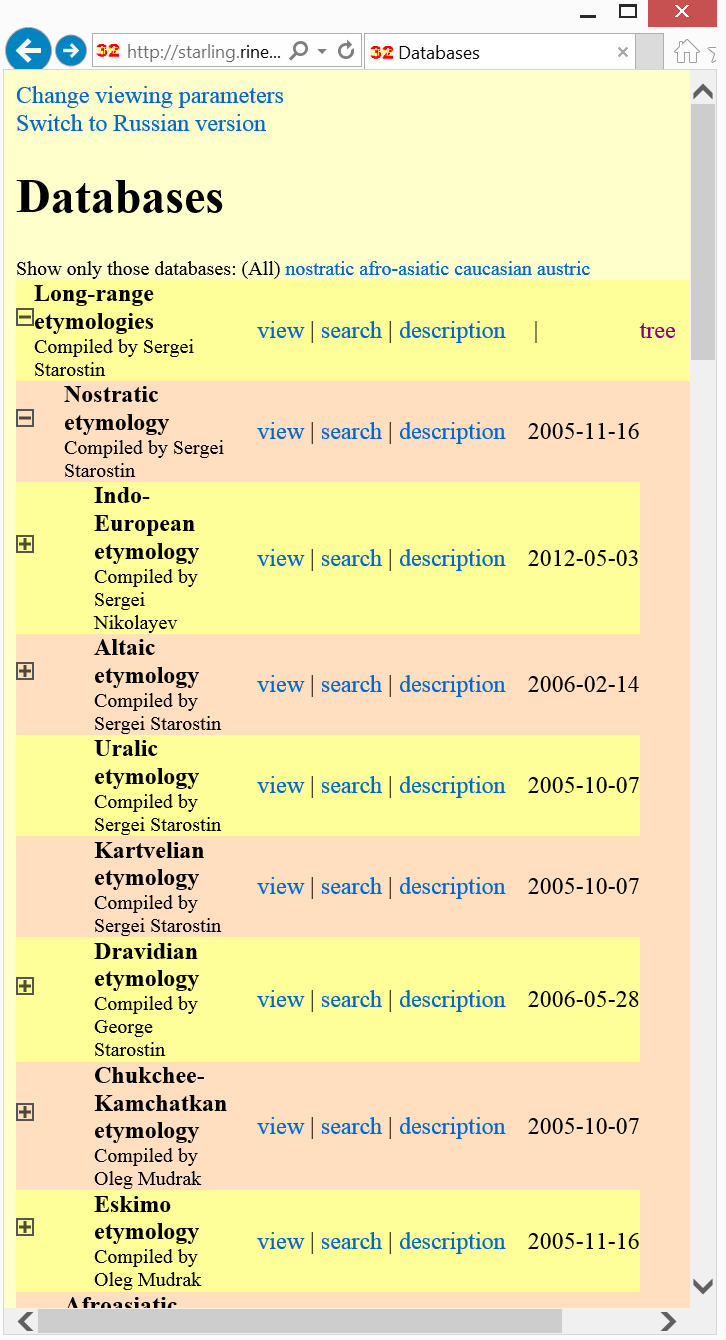
The Tower of Babel (Starling) 5 is a web portal on historical and comparative linguistics (Starostin, 2010), widely used in academia to publish etymological datasets over the internet. Starling allows exploring its dictionaries by means of faceted browsing using a coarse-grained phylogenetic tree (Fig. 2.a). We illustrate its data structures for the Turkic Etymological Dictionary (Dybo et al., 2012) with an example result for the query meaning="bird" (Fig.2.b). Following the Proto-Turkic root, we find a cross-reference to the Altaic dictionary, and the meaning (sense) of the proto-form in English and Russian. The following entries pertain to cognates in different Turkic languages: They provide complex information including one or multiple forms, co-indexed with the meaning field, and optionally augmented with additional gloss (e.g., ‘moth’ for Middle Turkic/Chagatai), bibliography (as a hyperlink, Fig. 3) or additional comments (e.g., < Az. for Halaj). We used an XML export of the Starling data (Fig. 1) to create RDF and (by converting cross-references) Linked Data.



4. Data Model for the Turkic Etymology
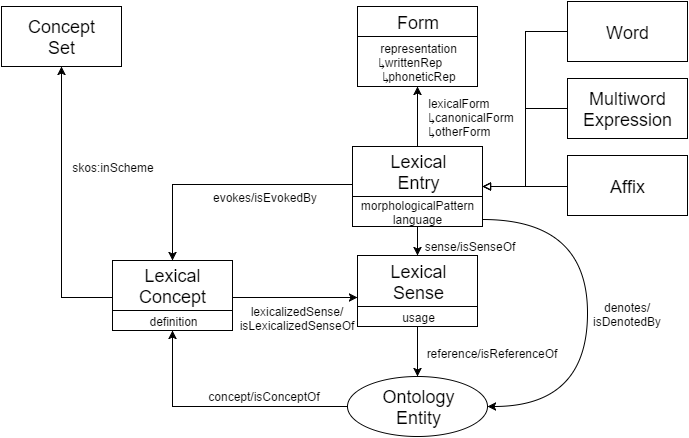
Following LLOD conventions, we employ the Ontolex/Lemon vocabulary (McCrae et al., 2011) 6 as shown in Fig. 4. Originally developed to add linguistic information to existing ontologies, Lemon evolved into a de-facto standard to represent lexical resources as LLOD. Here, we focus on Lemon extensions to represent etymological cognates: Etymological relations involve a relationship on the level of meaning (sense) and on the level of form, and thus require a novel property between one LexicalEntry and another. Between etymological cognates, it is not always clear whether one was the source of the other, or a more indirect relation holds. To express a generic etymological link without additional directionality information, we introduce the property lemonet:cognate. If source and target are known, a subproperty lemonet:derivedFrom is introduced. Similar to lemonet:cognate, it is transitive, but it is not symmetric. Distinguishing lemonet:cognate and lemonet:derivedFrom follows de Melo’s apparent directionality differentiation. Here, however, we provide a formal definition as a (minimal) extension of Lemon following (Chiarcos & Sukhareva, 2014) which supports inferring general cognate relations by subsumption and transitive/symmetric closure. In the Starling data, the directionality of etymological links is generally known, so we represent etymological relations with lemonet:derivedFrom between lexical entries from different Lemon lexicons. By subsumption inference, transitivity and symmetry of its superproperty, lemonet:cognate relations can be inferred automatically between all language-specific forms.
5. Applications
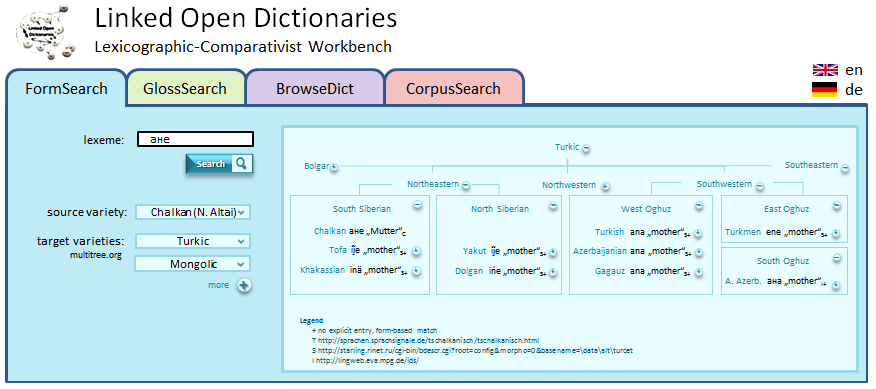
The Comparative-Lexicographical Workbench (Fig. 5) will provide novel search functionalities extending the functionality of existing platforms, form-based search and a gloss-(meaning-) based search, currently applied to the Turkic language family and its contact languages.
- gloss-(meaning-)based search. Dictionary lemmas are complemented with a gloss paraphrasing their meaning. Linked Data allows transitive search over sequences of bilingual dictionaries (e.g., Kazakh-Russian-English).
- form-based search. Given a lexeme in a particular language, say, Kazakh, and a set of related languages, say, the Turkish languages in general, the system will retrieve phonologically similar lexemes for the respective target languages.
Both search functionalities aim to detect candidate cognates. The data provided by Starling represents a gold standard, but can also be directly integrated into the search process: In Fig. 5, we query for Chalkan ана and possible cognates from Turkic (as an inherited word) or Mongolic (as a possible source of loan words). The results are organized according to the taxonomic status of the varieties in www.multitree.org. They include a gloss from a Chalkan dictionary (marked by subscript C), but in addition provide form-based matches (subscript +) from the Starling dictionaries (S), e.g., with Turkish ana and its etymologically corresponding forms, etc.
6. Summary
We described preliminary steps towards the development of a Comparative-Lexicographical Workbench that uses Linked Data formalisms to retrieve cognates as given in etymological dictionaries as well as to automatically identify cognate candidates from different languages (which are similar in form and meaning). In our presentation, both will be illustrated for the Turkic language family, and we will show how both aspects complement each other.
- Chiarcos, C., Nordhoff, S. and Hellmann, S. (2012). Linked Data in Linguistics. Berlin: Springer.
- Chiarcos, C., Cimiano, P., Declerck, T. and McCrae, J. (2013). Linguistic linked open data (llod). Proc. 2nd Workshop on Linked Data in Linguistics (LDL-2013), Pisa, Italy, pp. 1-11.
- Chiarcos, C. and Sukhareva, M. (2014). Linking Etymological Databases. Proc. 3rd Workshop on Linked Data in Linguistics (LDL-2014), Reykjavik, pp. 41–49.
- De Melo, G. (2014). Etymological Wordnet: Tracing the history of words. Proc. LREC 2014, Reykjavik.
- Dybo, A. V., Starostin, S. A. and Mudrak, O. A. (2012). Etymological Dictionary of the Altaic Languages. Brill, Leiden.
- McCrae, J., Spohr, D. and Cimiano, P. (2011). Linking lexical resources and ontologies on the semantic web with lemon. Proc. 8th Extended Semantic Web Conference (ESWC-2011), Heraklion, Crete, pp. 245–59.
- Moran, S. and Brümmer, M. (2013). Lemon-aid: Using Lemon to aid quantitative historical linguistic analysis. Proc. 2nd Workshop on Linked Data in Linguistics (LDL-2013), Pisa, Italy.
- Starostin, G. (2010). Preliminary lexicostatistics as a basis for language classification: A new approach. Journal of Language Relationship, 3: 79–117.