Authors: Mikko Tolonen, Niko Ilomäki, Hege Roivainen, Leo Lahti
Category: Paper:Long Paper
Keywords: metadata, fennica, kungliga, knowledge production, library
Printing in a Periphery: a Quantitative Study of Finnish Knowledge Production, 1640-1828
This paper presents a transparent and quantitative analysis of the overall development of Finnish book production between 1640-1828. The work is based on automated information extraction from library catalogues, and introduces the concept of open analytical ecosystems as a novel research tool for digital humanities. This extends our earlier pilot project on the use of the English Short Title (ESTC) catalogue ( https://github.com/rOpenGov/estc). In this new work we focus on Scandinavia, further demonstrating the potential of digitized library catalogues as a valuable resource for digital humanities and reproducible research. We continue our experimental analysis of paper consumption in early modern book production, and provide a practical demonstration on the importance of open-science principles for digital humanities.
Compared to our earlier British analysis (Lahti et al., 2015) we now integrate data across multiple library catalogues from Finland and Sweden. This analysis transcends national boundaries and brings forward key questions in metadata integration such as entry harmonization and duplicate identification. We propose a set of best practices for such tasks in automated large-scale analyses, and exemplify their use in the Scandinavian context. Such pilot project is crucial to later integrate data across the Heritage of the Printed Book database that eventually covers all of early modern Europe. Our emerging data analytical ecosystem supports these goals concretely.
Instead of ready-made standard software, such as Open Refine, Palladio, or similar user-friendly software, we have developed a set of custom tools in the R statistical programming environment to combine automation with full flexibility and access to state-of-the-art data analysis and visualization algorithms. An important contribution in comparison with related earlier work, for example Kalev’s GDELT ( http://blog.gdeltproject.org/mapping-212-years-of-history-through-books/), is that we have drastically refined the metadata, for instance by harmonizing synonymous entries and by enriching the data with external information such as name-gender mappings and geographical information. The bibliographic metadata in national library catalogues follow international standards and, as we demonstrate, the fully open source computational data analysis tools introduced within this project are immediately relevant and widely applicable in further studies based on library catalogue metadata.
We focus on the extraction and statistical analysis of library catalogue metadata to study the emergence and development of public discourse in Finland (1640–1828). The main data source for our analysis is Fennica, Finnish National Bibliography ( https://github.com/rOpenGov/fennica). This is complemented with further metadata and content analysis of Finnish newspapers and journals and material from Sweden, from the Kungliga collection, Stockholm ( https://github.com/rOpenGov/kungliga), and include comparisons with further library catalogue material from other countries as well. The analysis allows us to provide concrete, quantitative figures on publication activity, places, and topics and compare these to political, technological, and social ruptures. The quantitative analysis of print culture will allow us to study how the development of Finnish book, newspaper and journal production compares to European trends.
It is not enough, however, to see European public discourse by combining nationally organized knowledge. The hypothesis is that the European map of knowledge production will have local flavors in different corners of Europe. The aim should thus be to integrate data across library catalogues to analyze different streams of influence and varying regional perspectives and uncover potential asymmetries that may have guided intellectual life. The comparison between neighboring countries also allows for the detection of local publishing networks in the Baltic Sea region.
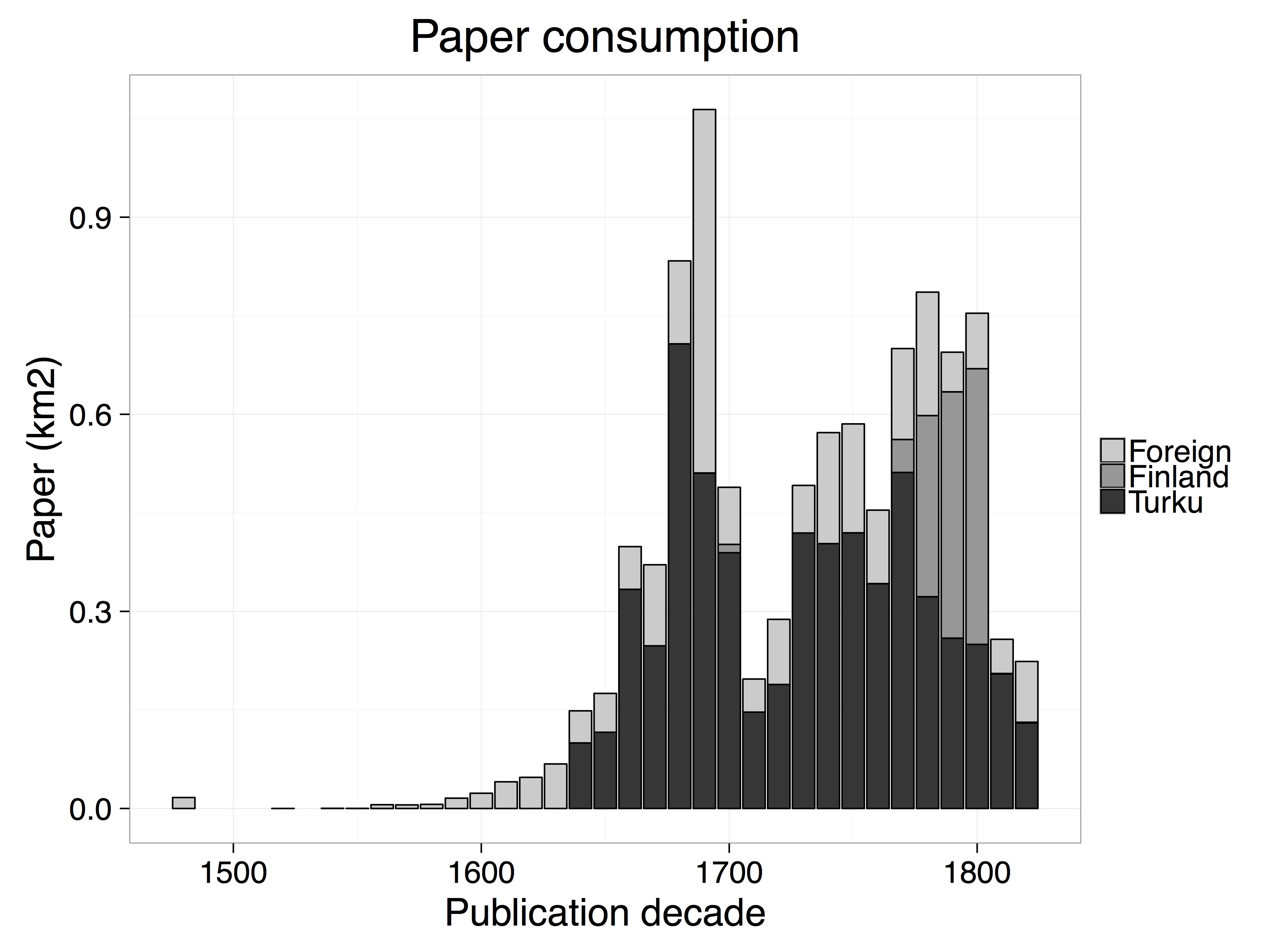
Our aim in this paper is particularly to study the development of publishing houses in Finland and their spread from Turku to other parts of Finland. We will also identify overlooked moments of transformation in public discourse in Finland by blending historical and computational approaches. The research undertaken will reflect on how social change and public discourse are intertwined, and how cultural, institutional, legal and technological changes are reflected both in publication metadata and the textual content of the publications. In terms of the historical timeframe, our study begins with the founding of the first Finnish press at the Academy of Turku in 1640, tracks the overall publishing history of the country until 1828 when Helsinki starts to play a major role in Finland.
Public discourse in Finland has been largely approached from the perspective of the breakthrough of the Finnish language, the role of elite discourse at the university, early Swedish-language newspapers, and book history. We combine these perspectives, and further analyze how language-barriers, elite culture and popular debate, as well as different publication channels interacted. Large-scale quantitative analysis of library catalogues opens novel opportunities to characterize the general impact of the turn from Swedish to Russian rule in early nineteenth-century regarding public discourse in Finland. Previous historical research on the development of civility in nineteenth-century Finland has lacked appropriate quantitative tools to take an objective ‘bird-eye’ view of these complicated and crucial transformations. Questions of how, for instance, the establishment of the university in Turku/Åbo (1640), the introduction of freedom of print (1766), the formation of a Finnish Grand Duchy in the Russian Empire (1809–1812), the changes in the enforcement of censorship, the decision to transform Helsinki into a capital city (1819), the lack of estate representation in the Grand Duchy, and the slow emergence of a Finnish written language resonated in publication practices are explored from a quantitative perspective.
Our open data analytical ecosystems provide powerful and flexible data analytical tools that can best serve the needs of genuinely data-intensive research, in contrast to traditional point-and-click interfaces that are suitable for simple query tasks but not designed for fully transparent, reproducible and automated large-scale algorithmic data mining. The open source ecosystems will also enable new collaboration models around digital data collections that are now becoming increasingly available for research and other purposes. This emphasis on transparent and collaborative methodology, already wide-spread in other fields of computational science, sets the context for our work within digital humanities. Others can benefit from the new tools and the libraries from the refined data sets. The data analytical algorithms, including data extraction, statistical analysis, summarization and reporting, will be are released in full detail within a unified open source ecosystem in Github ( http://github.com/rOpenGov/fennica), where all steps from raw data to the final results can be traced back and improved further. In this sense, our emphasis on open data analytical process and collaboration model is different from Anderson's and Blanke's discussion on digital humanities ecosystems (Anderson and Blanke, 2012), which focuses on the role of the community of researchers.
This paper continues an ongoing trend of quantitative analysis of publishing history (Moretti, 2013; Towsey et al., 2015). While reuse of library catalogue data has been discussed in recent digital humanities scholarship (for example, Prescott, 2013 and Bode and Osborne, 2014), large-scale library catalogues represent a so far underestimated research resource, containing systematic information on publication activity over years, language barriers, genres, geographical regions and other variables in which the evolution of the public sphere is reflected. Moreover, our work complements the distant reading and related concepts discussed by Bode and Moretti by introducing concrete algorithms and proposing a collaborative development model. Lincoln Mullen has used a related approach to analyze historical texts ( http://lincolnmullen.com/#software).
Our ultimate aim is to develop algorithms to extract, harmonize and integrate relevant metadata across the different European library catalogues, regardless of language. This research data will be further enriched by complementing it with data from auxiliary sources, such as linked data on person records, biographies of partner organizations, ontologies and other assets. The enriched information is then used to formulate statistical summaries and systematic quantitative comparisons, as well as interactive and dynamic visual representations of the publication activity, topics and geographical variation and of their evolution over time. To demonstrate the efficiency of this approach, we quantify the importance of Turku in the Finnish publication landscape during 1640-1828.
- Anderson, S. and Blanke, T. (2012). Taking the Long View: From e-Science Humanities to Humanities Digital Ecosystems. Historical Social Research, 37: 147-64.
- Bode, K. and Osborne, R. (2014). Book History from the Archival Record. In Leslie Howsam (Ed.), The Cambridge Companion to the History of the Book. Cambridge University Press, pp. 219-36.
- Lahti, L., Ilomäki, N., Tolonen, M. (2015). A Quantitative Study of History in the English Short-Title Catalogue (ESTC) 1470-1800. LIBER Quarterly, 25(2): 87-116.
- Moretti, F. (2013). Distant Reading. Verso books.
- Prescott, A. (2013). Bibliographic records as humanities big data. Big Data IEEE International Conference 2013: Conference Abstracts. Silicon Valley, pp. 55-58.
- Towsey, M., Bode, K. Burrows, S. et al. (2015). Remapping Cultural History: Digital Humanities, Historical Bibliometrics, and the Reception of Print Culture. Digital Humanities 2015 Conference, University of Western Sydney.